 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Infomax and Domain-Independent Representations for Causal Effect Inference with Real-World Data
Paper and Code
Feb 22, 2022
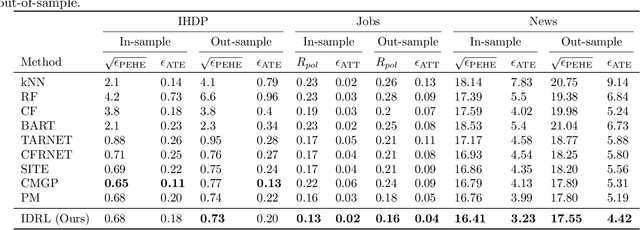

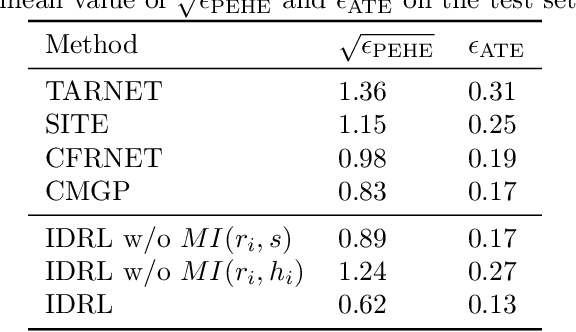
The foremost challenge to causal inference with real-world data is to handle the imbalance in the covariates with respect to different treatment options, caused by treatment selection bias. To address this issue, recent literature has explored domain-invariant representation learning based on different domain divergence metrics (e.g., Wasserstein distance, maximum mean discrepancy, position-dependent metric, and domain overlap). In this paper, we reveal the weaknesses of these strategies, i.e., they lead to the loss of predictive information when enforcing the domain invariance; and the treatment effect estimation performance is unstable, which heavily relies on the characteristics of the domain distributions and the choice of domain divergence metrics. Motivated by information theory, we propose to learn the Infomax and Domain-Independent Representations to solve the above puzzles. Our method utilizes the mutual information between the global feature representations and individual feature representations, and the mutual information between feature representations and treatment assignment predictions, in order to maximally capture the common predictive information for both treatment and control groups. Moreover, our method filters out the influence of instrumental and irrelevant variables, and thus it effectively increases the predictive ability of potential outcomes. Experimental results on both the synthetic and real-world datasets show that our method achieves state-of-the-art performance on causal effect inference. Moreover, our method exhibits reliable prediction performances when facing data with different characteristics of data distributions, complicated variable types, and severe covariate imbalance.