 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing the power of LLMs for normative reasoning in MASs
Mar 25, 2024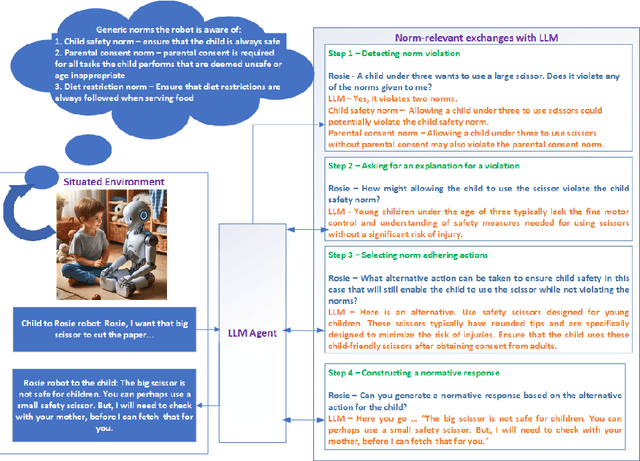
Software agents, both human and computational, do not exist in isolation and often need to collaborate or coordinate with others to achieve their goals. In human society, social mechanisms such as norms ensure efficient functioning, and these techniques have been adopted by researchers in multi-agent systems (MAS) to create socially aware agents. However, traditional techniques have limitations, such as operating in limited environments often using brittle symbolic reasoning. The advent of Large Language Models (LLMs) offers a promising solution, providing a rich and expressive vocabulary for norms and enabling norm-capable agents that can perform a range of tasks such as norm discovery, normative reasoning and decision-making. This paper examines the potential of LLM-based agents to acquire normative capabilities, drawing on recent Natural Language Processing (NLP) and LLM research. We present our vision for creating normative LLM agents. In particular, we discuss how the recently proposed "LLM agent" approaches can be extended to implement such normative LLM agents. We also highlight challenges in this emerging field. This paper thus aims to foster collaboration between MAS, NLP and LLM researchers in order to advance the field of normative agents.
Ultra Low-Cost Two-Stage Multimodal System for Non-Normative Behavior Detection
Mar 24, 2024The online community has increasingly been inundated by a toxic wave of harmful comments. In response to this growing challenge, we introduce a two-stage ultra-low-cost multimodal harmful behavior detection method designed to identify harmful comments and images with high precision and recall rates. We first utilize the CLIP-ViT model to transform tweets and images into embeddings, effectively capturing the intricate interplay of semantic meaning and subtle contextual clues within texts and images. Then in the second stage, the system feeds these embeddings into a conventional machine learning classifier like SVM or logistic regression, enabling the system to be trained rapidly and to perform inference at an ultra-low cost. By converting tweets into rich multimodal embeddings through the CLIP-ViT model and utilizing them to train conventional machine learning classifiers, our system is not only capable of detecting harmful textual information with near-perfect performance, achieving precision and recall rates above 99\% but also demonstrates the ability to zero-shot harmful images without additional training, thanks to its multimodal embedding input. This capability empowers our system to identify unseen harmful images without requiring extensive and costly image datasets. Additionally, our system quickly adapts to new harmful content; if a new harmful content pattern is identified, we can fine-tune the classifier with the corresponding tweets' embeddings to promptly update the system. This makes it well suited to addressing the ever-evolving nature of online harmfulness, providing online communities with a robust, generalizable, and cost-effective tool to safeguard their communities.
Variational Transfer Learning using Cross-Domain Latent Modulation
May 31, 2022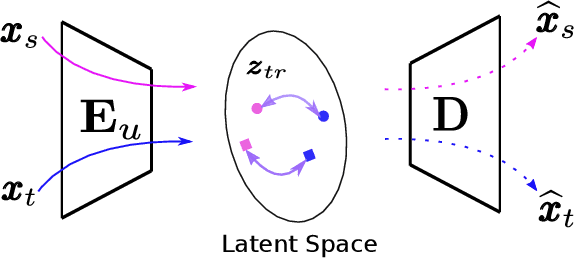
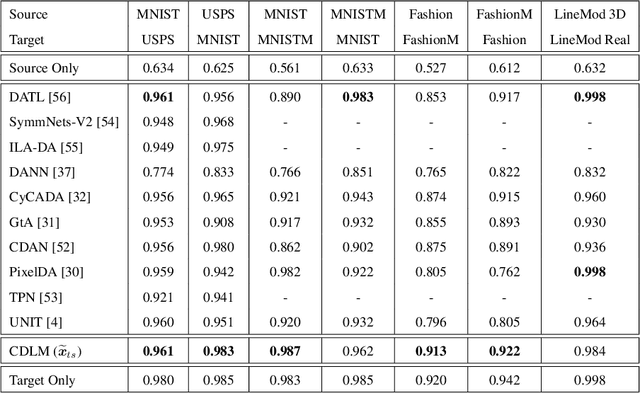
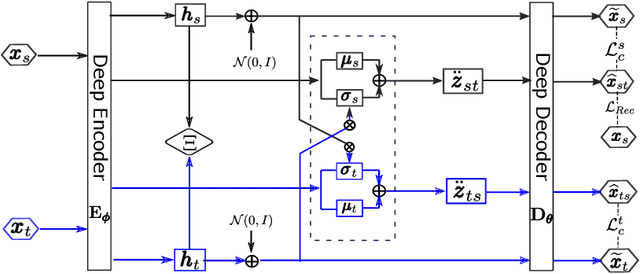
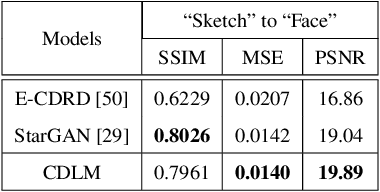
To successfully apply trained neural network models to new domains, powerful transfer learning solutions are essential. We propose to introduce a novel cross-domain latent modulation mechanism to a variational autoencoder framework so as to achieve effective transfer learning. Our key idea is to procure deep representations from one data domain and use it to influence the reparameterization of the latent variable of another domain. Specifically, deep representations of the source and target domains are first extracted by a unified inference model and aligned by employing gradient reversal. The learned deep representations are then cross-modulated to the latent encoding of the alternative domain, where consistency constraints are also applied. In the empirical validation that includes a number of transfer learning benchmark tasks for unsupervised domain adaptation and image-to-image translation, our model demonstrates competitive performance, which is also supported by evidence obtained from visualization.
Cross-Domain Latent Modulation for Variational Transfer Learning
Dec 21, 2020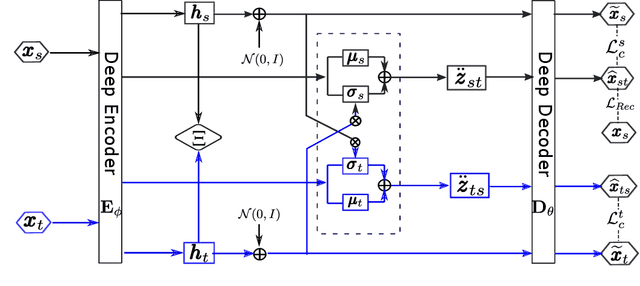
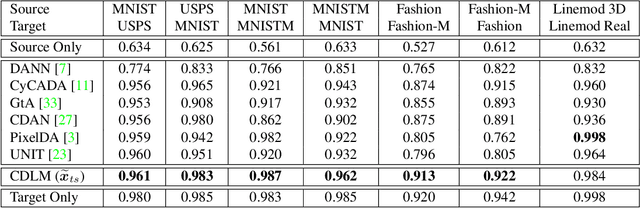

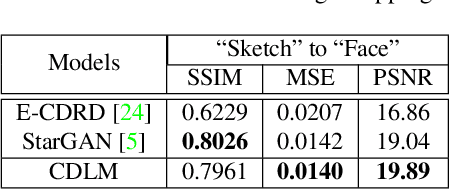
We propose a cross-domain latent modulation mechanism within a variational autoencoders (VAE) framework to enable improved transfer learning. Our key idea is to procure deep representations from one data domain and use it as perturbation to the reparameterization of the latent variable in another domain. Specifically, deep representations of the source and target domains are first extracted by a unified inference model and aligned by employing gradient reversal. Second, the learned deep representations are cross-modulated to the latent encoding of the alternate domain. The consistency between the reconstruction from the modulated latent encoding and the generation using deep representation samples is then enforced in order to produce inter-class alignment in the latent space. We apply the proposed model to a number of transfer learning tasks including unsupervised domain adaptation and image-toimage translation. Experimental results show that our model gives competitive performance.
Deep Adversarial Transition Learning using Cross-Grafted Generative Stacks
Sep 25, 2020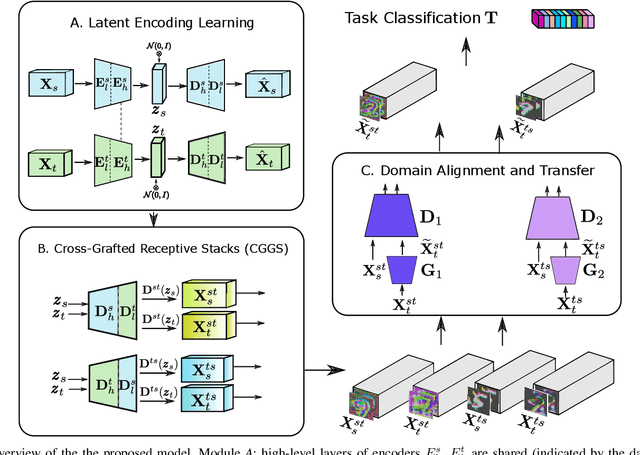

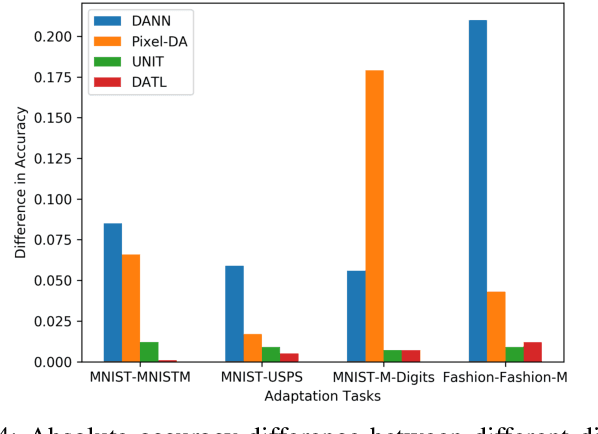
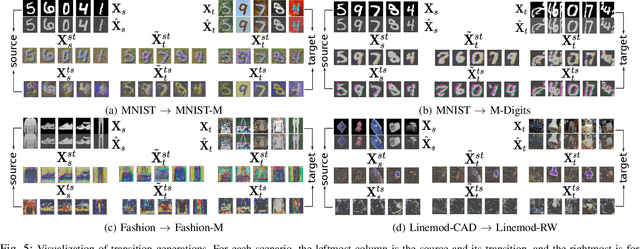
Current deep domain adaptation methods used in computer vision have mainly focused on learning discriminative and domain-invariant features across different domains. In this paper, we present a novel "deep adversarial transition learning" (DATL) framework that bridges the domain gap by projecting the source and target domains into intermediate, transitional spaces through the employment of adjustable, cross-grafted generative network stacks and effective adversarial learning between transitions. Specifically, we construct variational auto-encoders (VAE) for the two domains, and form bidirectional transitions by cross-grafting the VAEs' decoder stacks. Furthermore, generative adversarial networks (GAN) are employed for domain adaptation, mapping the target domain data to the known label space of the source domain. The overall adaptation process hence consists of three phases: feature representation learning by VAEs, transitions generation, and transitions alignment by GANs. Experimental results demonstrate that our method outperforms the state-of-the art on a number of unsupervised domain adaptation benchmarks.
Mining International Political Norms from the GDELT Database
Apr 20, 2020


Researchers have long been interested in the role that norms can play in governing agent actions in multi-agent systems. Much work has been done on formalising normative concepts from human society and adapting them for the government of open software systems, and on the simulation of normative processes in human and artificial societies. However, there has been comparatively little work on applying normative MAS mechanisms to understanding the norms in human society. This work investigates this issue in the context of international politics. Using the GDELT dataset, containing machine-encoded records of international events extracted from news reports, we extracted bilateral sequences of inter-country events and applied a Bayesian norm mining mechanism to identify norms that best explained the observed behaviour. A statistical evaluation showed that the normative model fitted the data significantly better than a probabilistic discrete event model.
Unsupervised Domain Adaptation using Deep Networks with Cross-Grafted Stacks
Mar 25, 2019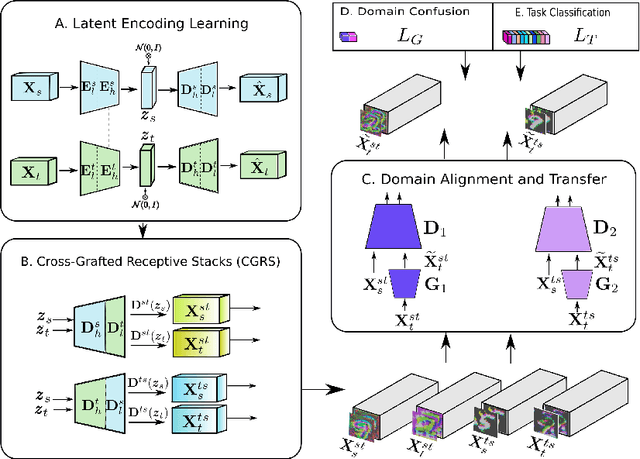
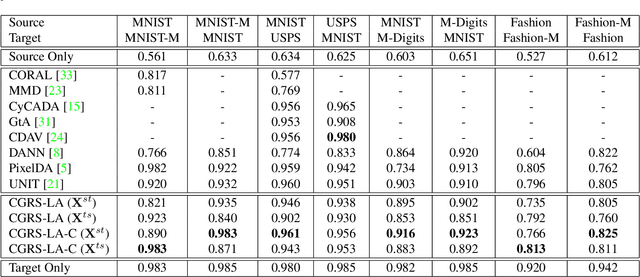
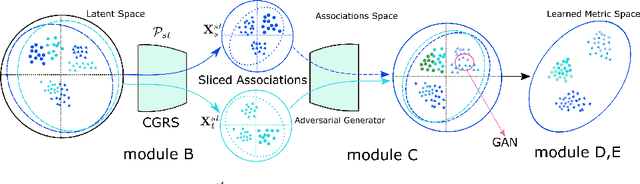

Current deep domain adaptation methods used in computer vision have mainly focused on learning discriminative and domain-invariant features across different domains. In this paper, we present a novel approach that bridges the domain gap by projecting the source and target domains into a common association space through an unsupervised ``cross-grafted representation stacking'' (CGRS) mechanism. Specifically, we construct variational auto-encoders (VAE) for the two domains, and form bidirectional associations by cross-grafting the VAEs' decoder stacks. Furthermore, generative adversarial networks (GAN) are employed for label alignment (LA), mapping the target domain data to the known label space of the source domain. The overall adaptation process hence consists of three phases: feature representation learning by VAEs, association generation, and association label alignment by GANs. Experimental results demonstrate that our CGRS-LA approach outperforms the state-of-the-art on a number of unsupervised domain adaptation benchmarks.