 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Adversarial Transition Learning using Cross-Grafted Generative Stacks
Paper and Code
Sep 25, 2020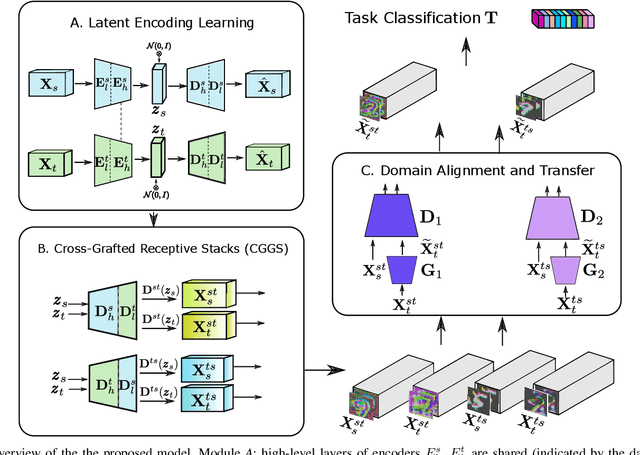

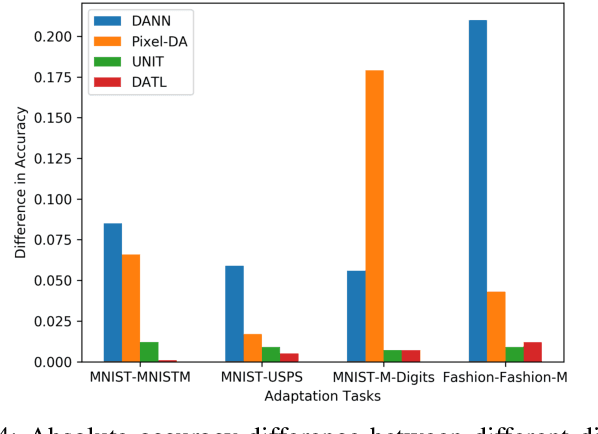
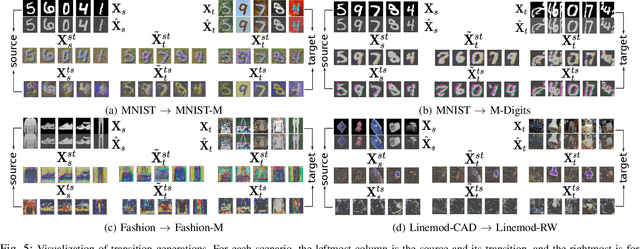
Current deep domain adaptation methods used in computer vision have mainly focused on learning discriminative and domain-invariant features across different domains. In this paper, we present a novel "deep adversarial transition learning" (DATL) framework that bridges the domain gap by projecting the source and target domains into intermediate, transitional spaces through the employment of adjustable, cross-grafted generative network stacks and effective adversarial learning between transitions. Specifically, we construct variational auto-encoders (VAE) for the two domains, and form bidirectional transitions by cross-grafting the VAEs' decoder stacks. Furthermore, generative adversarial networks (GAN) are employed for domain adaptation, mapping the target domain data to the known label space of the source domain. The overall adaptation process hence consists of three phases: feature representation learning by VAEs, transitions generation, and transitions alignment by GANs. Experimental results demonstrate that our method outperforms the state-of-the art on a number of unsupervised domain adaptation benchmarks.