 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Semantic Segmentation of Vessel Images using Leaking Perturbations
Oct 22, 2021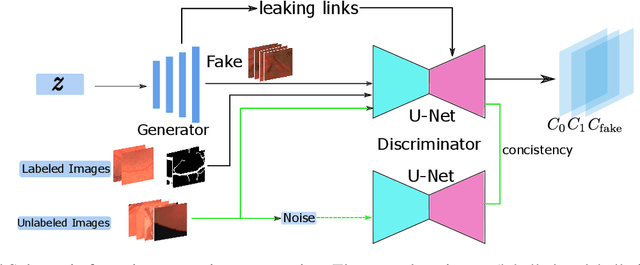
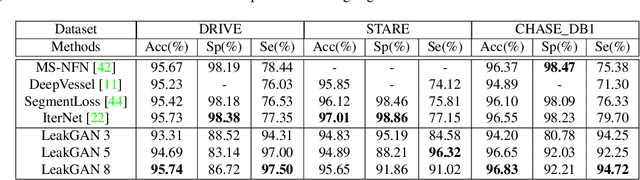
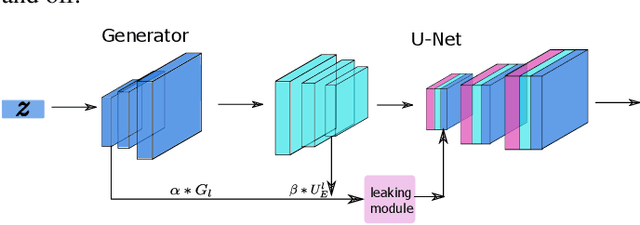

Semantic segmentation based on deep learning methods can attain appealing accuracy provided large amounts of annotated samples. However, it remains a challenging task when only limited labelled data are available, which is especially common in medical imaging. In this paper, we propose to use Leaking GAN, a GAN-based semi-supervised architecture for retina vessel semantic segmentation. Our key idea is to pollute the discriminator by leaking information from the generator. This leads to more moderate generations that benefit the training of GAN. As a result, the unlabelled examples can be better utilized to boost the learning of the discriminator, which eventually leads to stronger classification performance. In addition, to overcome the variations in medical images, the mean-teacher mechanism is utilized as an auxiliary regularization of the discriminator. Further, we modify the focal loss to fit it as the consistency objective for mean-teacher regularizer. Extensive experiments demonstrate that the Leaking GAN framework achieves competitive performance compared to the state-of-the-art methods when evaluated on benchmark datasets including DRIVE, STARE and CHASE\_DB1, using as few as 8 labelled images in the semi-supervised setting. It also outperforms existing algorithms on cross-domain segmentation tasks.
Cross-Domain Latent Modulation for Variational Transfer Learning
Dec 21, 2020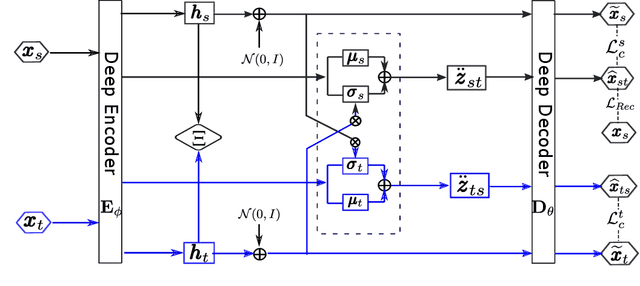
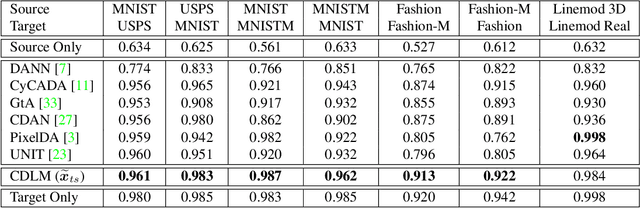

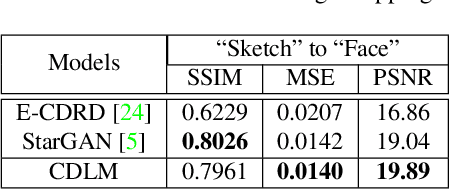
We propose a cross-domain latent modulation mechanism within a variational autoencoders (VAE) framework to enable improved transfer learning. Our key idea is to procure deep representations from one data domain and use it as perturbation to the reparameterization of the latent variable in another domain. Specifically, deep representations of the source and target domains are first extracted by a unified inference model and aligned by employing gradient reversal. Second, the learned deep representations are cross-modulated to the latent encoding of the alternate domain. The consistency between the reconstruction from the modulated latent encoding and the generation using deep representation samples is then enforced in order to produce inter-class alignment in the latent space. We apply the proposed model to a number of transfer learning tasks including unsupervised domain adaptation and image-toimage translation. Experimental results show that our model gives competitive performance.
Deep Adversarial Transition Learning using Cross-Grafted Generative Stacks
Sep 25, 2020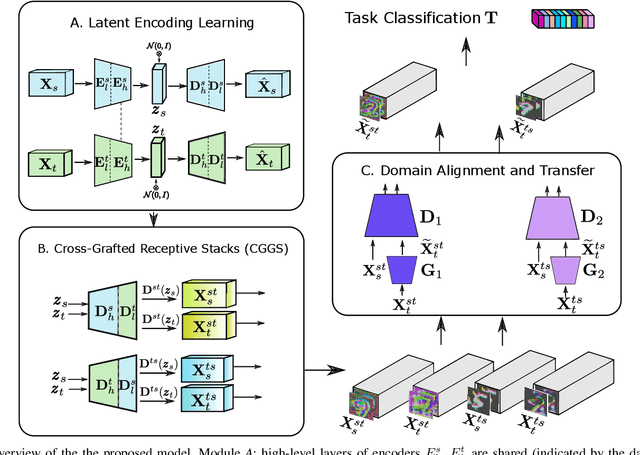

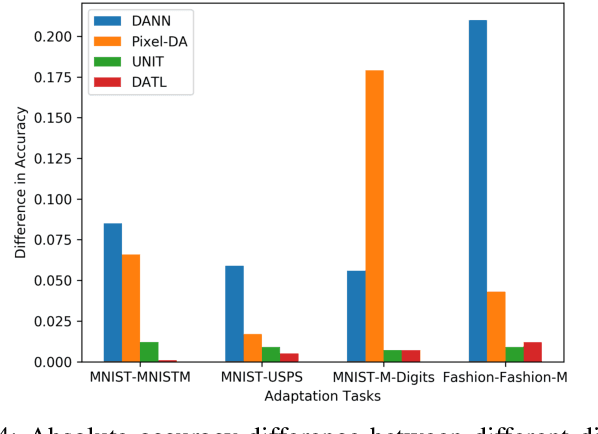
Current deep domain adaptation methods used in computer vision have mainly focused on learning discriminative and domain-invariant features across different domains. In this paper, we present a novel "deep adversarial transition learning" (DATL) framework that bridges the domain gap by projecting the source and target domains into intermediate, transitional spaces through the employment of adjustable, cross-grafted generative network stacks and effective adversarial learning between transitions. Specifically, we construct variational auto-encoders (VAE) for the two domains, and form bidirectional transitions by cross-grafting the VAEs' decoder stacks. Furthermore, generative adversarial networks (GAN) are employed for domain adaptation, mapping the target domain data to the known label space of the source domain. The overall adaptation process hence consists of three phases: feature representation learning by VAEs, transitions generation, and transitions alignment by GANs. Experimental results demonstrate that our method outperforms the state-of-the art on a number of unsupervised domain adaptation benchmarks.
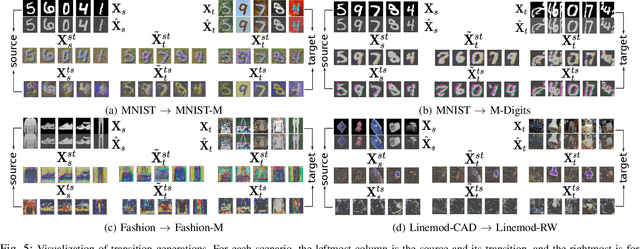
Unsupervised Domain Adaptation using Deep Networks with Cross-Grafted Stacks
Mar 25, 2019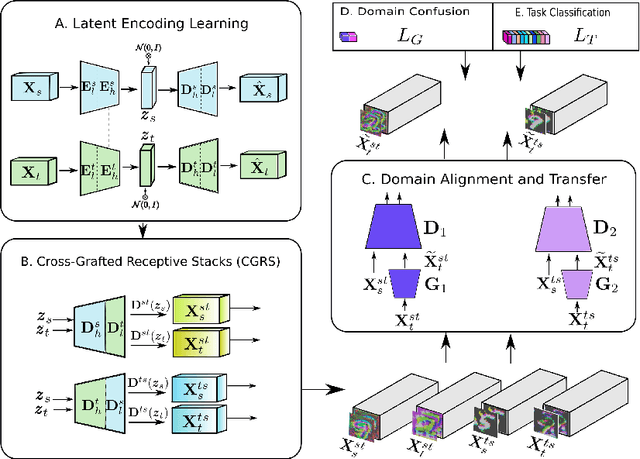
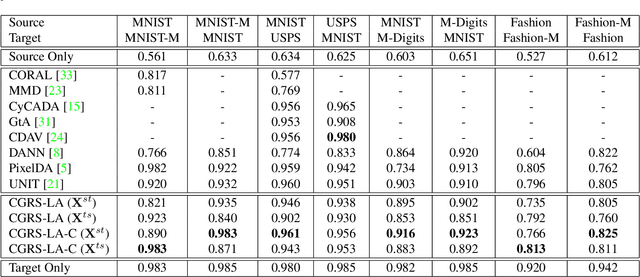
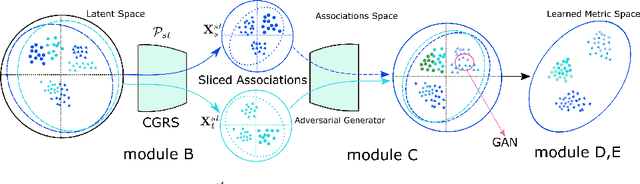

Current deep domain adaptation methods used in computer vision have mainly focused on learning discriminative and domain-invariant features across different domains. In this paper, we present a novel approach that bridges the domain gap by projecting the source and target domains into a common association space through an unsupervised ``cross-grafted representation stacking'' (CGRS) mechanism. Specifically, we construct variational auto-encoders (VAE) for the two domains, and form bidirectional associations by cross-grafting the VAEs' decoder stacks. Furthermore, generative adversarial networks (GAN) are employed for label alignment (LA), mapping the target domain data to the known label space of the source domain. The overall adaptation process hence consists of three phases: feature representation learning by VAEs, association generation, and association label alignment by GANs. Experimental results demonstrate that our CGRS-LA approach outperforms the state-of-the-art on a number of unsupervised domain adaptation benchmarks.