 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning and face recognition: the state of the art
Feb 10, 2019Deep Neural Networks (DNNs) have established themselves as a dominant technique in machine learning. DNNs have been top performers on a wide variety of tasks including image classification, speech recognition, and face recognition. Convolutional neural networks (CNNs) have been used in nearly all of the top performing methods on the Labeled Faces in the Wild (LFW) dataset. In this talk and accompanying paper, I attempt to provide a review and summary of the deep learning techniques used in the state-of-the-art. In addition, I highlight the need for both larger and more challenging public datasets to benchmark these systems. The high accuracy (99.63% for FaceNet at the time of publishing) and utilization of outside data (hundreds of millions of images in the case of Google's FaceNet) suggest that current face verification benchmarks such as LFW may not be challenging enough, nor provide enough data, for current techniques. There exist a variety of organizations with mobile photo sharing applications that would be capable of releasing a very large scale and highly diverse dataset of facial images captured on mobile devices. Such an "ImageNet for Face Recognition" would likely receive a warm welcome from researchers and practitioners alike.
* Published May 15th 2015 in the Proc. SPIE 9457, Biometric and Surveillance Technology for Human and Activity Identification XII, 94570B; Ioannis A. Kakadiaris; Ajay Kumar; Walter J. Scheirer, Editor(s)
RenderNet: A deep convolutional network for differentiable rendering from 3D shapes
Jun 19, 2018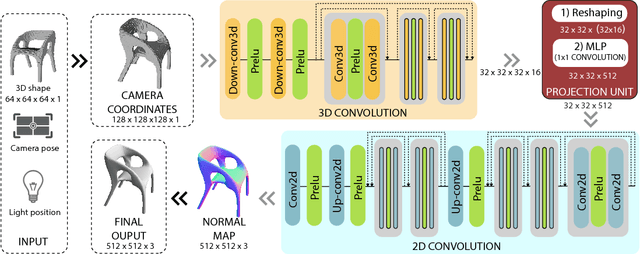

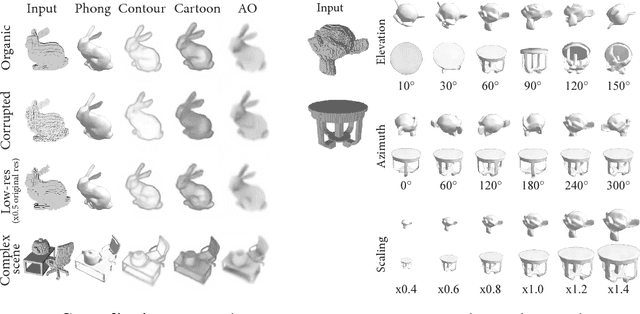

Traditional computer graphics rendering pipeline is designed for procedurally generating 2D quality images from 3D shapes with high performance. The non-differentiability due to discrete operations such as visibility computation makes it hard to explicitly correlate rendering parameters and the resulting image, posing a significant challenge for inverse rendering tasks. Recent work on differentiable rendering achieves differentiability either by designing surrogate gradients for non-differentiable operations or via an approximate but differentiable renderer. These methods, however, are still limited when it comes to handling occlusion, and restricted to particular rendering effects. We present RenderNet, a differentiable rendering convolutional network with a novel projection unit that can render 2D images from 3D shapes. Spatial occlusion and shading calculation are automatically encoded in the network. Our experiments show that RenderNet can successfully learn to implement different shaders, and can be used in inverse rendering tasks to estimate shape, pose, lighting and texture from a single image.