 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Organization in Computation & Chemistry: Return to AlChemy
Aug 23, 2024



How do complex adaptive systems, such as life, emerge from simple constituent parts? In the 1990s Walter Fontana and Leo Buss proposed a novel modeling approach to this question, based on a formal model of computation known as $\lambda$ calculus. The model demonstrated how simple rules, embedded in a combinatorially large space of possibilities, could yield complex, dynamically stable organizations, reminiscent of biochemical reaction networks. Here, we revisit this classic model, called AlChemy, which has been understudied over the past thirty years. We reproduce the original results and study the robustness of those results using the greater computing resources available today. Our analysis reveals several unanticipated features of the system, demonstrating a surprising mix of dynamical robustness and fragility. Specifically, we find that complex, stable organizations emerge more frequently than previously expected, that these organizations are robust against collapse into trivial fixed-points, but that these stable organizations cannot be easily combined into higher order entities. We also study the role played by the random generators used in the model, characterizing the initial distribution of objects produced by two random expression generators, and their consequences on the results. Finally, we provide a constructive proof that shows how an extension of the model, based on typed $\lambda$ calculus, could simulate transitions between arbitrary states in any possible chemical reaction network, thus indicating a concrete connection between AlChemy and chemical reaction networks. We conclude with a discussion of possible applications of AlChemy to self-organization in modern programming languages and quantitative approaches to the origin of life.
Automated Program Repair: Emerging trends pose and expose problems for benchmarks
May 08, 2024
Machine learning (ML) now pervades the field of Automated Program Repair (APR). Algorithms deploy neural machine translation and large language models (LLMs) to generate software patches, among other tasks. But, there are important differences between these applications of ML and earlier work. Evaluations and comparisons must take care to ensure that results are valid and likely to generalize. A challenge is that the most popular APR evaluation benchmarks were not designed with ML techniques in mind. This is especially true for LLMs, whose large and often poorly-disclosed training datasets may include problems on which they are evaluated.
GEVO-ML: Optimizing Machine Learning Code with Evolutionary Computation
Oct 16, 2023
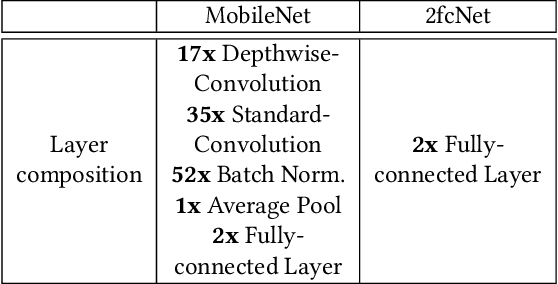


Parallel accelerators, such as GPUs, are key enablers for large-scale Machine Learning (ML) applications. However, ML model developers often lack detailed knowledge of the underlying system architectures, while system programmers usually do not have a high-level understanding of the ML model that runs on the specific system. To mitigate this gap between two relevant aspects of domain knowledge, this paper proposes GEVO-ML, a tool for automatically discovering optimization opportunities and tuning the performance of ML kernels, where the model and training/prediction processes are uniformly represented in a single intermediate language, the Multiple-Layer Intermediate Representation (MLIR). GEVO-ML uses multi-objective evolutionary search to find edits (mutations) to MLIR code that ultimately runs on GPUs, improving performance on desired criteria while retaining required functionality. We demonstrate GEVO-ML on two different ML workloads for both model training and prediction. GEVO-ML finds significant Pareto improvements for these models, achieving 90.43% performance improvement when model accuracy is relaxed by 2%, from 91.2% to 89.3%. For the training workloads, GEVO-ML finds a 4.88% improvement in model accuracy, from 91% to 96%, without sacrificing training or testing speed. Our analysis of key GEVO-ML mutations reveals diverse code modifications, while might be foreign to human developers, achieving similar effects with how human developers improve model design, for example, by changing learning rates or pruning non-essential layer parameters.
GEVO: GPU Code Optimization using Evolutionary Computation
Apr 27, 2020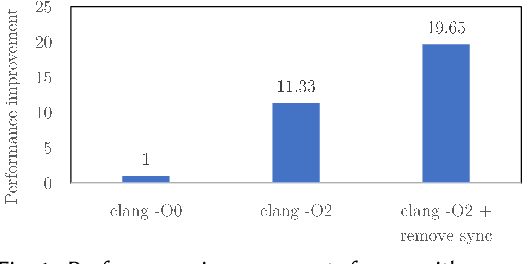
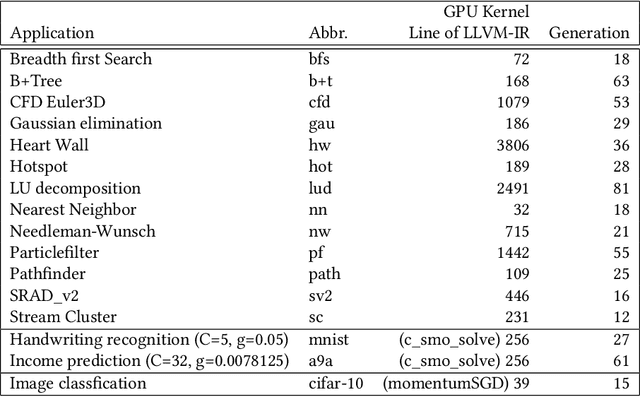
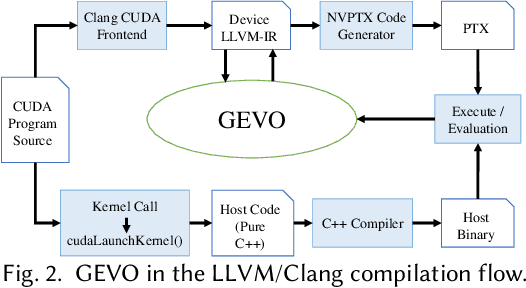
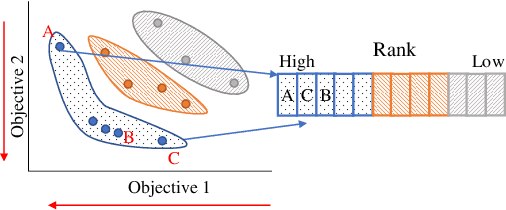
GPUs are a key enabler of the revolution in machine learning and high performance computing, functioning as de facto co-processors to accelerate large-scale computation. As the programming stack and tool support have matured, GPUs have also become accessible to programmers, who may lack detailed knowledge of the underlying architecture and fail to fully leverage the GPU's computation power. GEVO (Gpu optimization using EVOlutionary computation) is a tool for automatically discovering optimization opportunities and tuning the performance of GPU kernels in the LLVM representation. GEVO uses population-based search to find edits to GPU code compiled to LLVM-IR and improves performance on desired criteria while retaining required functionality. We demonstrate that GEVO improves the execution time of the GPU programs in the Rodinia benchmark suite and the machine learning models, SVM and ResNet18, on NVIDIA Tesla P100. For the Rodinia benchmarks, GEVO improves GPU kernel runtime performance by an average of 49.48% and by as much as 412% over the fully compiler-optimized baseline. If kernel output accuracy is relaxed to tolerate up to 1% error, GEVO can find kernel variants that outperform the baseline version by an average of 51.08%. For the machine learning workloads, GEVO achieves kernel performance improvement for SVM on the MNIST handwriting recognition (3.24X) and the a9a income prediction (2.93X) datasets with no loss of model accuracy. GEVO achieves 1.79X kernel performance improvement on image classification using ResNet18/CIFAR-10, with less than 1% model accuracy reduction.
The Surprising Creativity of Digital Evolution: A Collection of Anecdotes from the Evolutionary Computation and Artificial Life Research Communities
Aug 14, 2018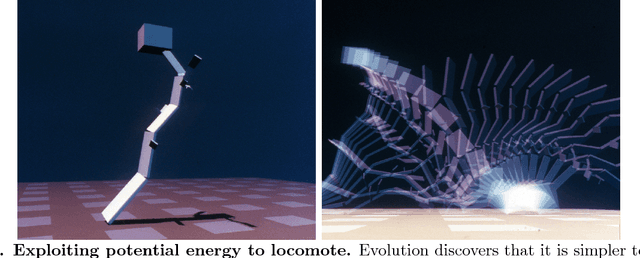



Biological evolution provides a creative fount of complex and subtle adaptations, often surprising the scientists who discover them. However, because evolution is an algorithmic process that transcends the substrate in which it occurs, evolution's creativity is not limited to nature. Indeed, many researchers in the field of digital evolution have observed their evolving algorithms and organisms subverting their intentions, exposing unrecognized bugs in their code, producing unexpected adaptations, or exhibiting outcomes uncannily convergent with ones in nature. Such stories routinely reveal creativity by evolution in these digital worlds, but they rarely fit into the standard scientific narrative. Instead they are often treated as mere obstacles to be overcome, rather than results that warrant study in their own right. The stories themselves are traded among researchers through oral tradition, but that mode of information transmission is inefficient and prone to error and outright loss. Moreover, the fact that these stories tend to be shared only among practitioners means that many natural scientists do not realize how interesting and lifelike digital organisms are and how natural their evolution can be. To our knowledge, no collection of such anecdotes has been published before. This paper is the crowd-sourced product of researchers in the fields of artificial life and evolutionary computation who have provided first-hand accounts of such cases. It thus serves as a written, fact-checked collection of scientifically important and even entertaining stories. In doing so we also present here substantial evidence that the existence and importance of evolutionary surprises extends beyond the natural world, and may indeed be a universal property of all complex evolving systems.