 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEVO-ML: Optimizing Machine Learning Code with Evolutionary Computation
Paper and Code
Oct 16, 2023
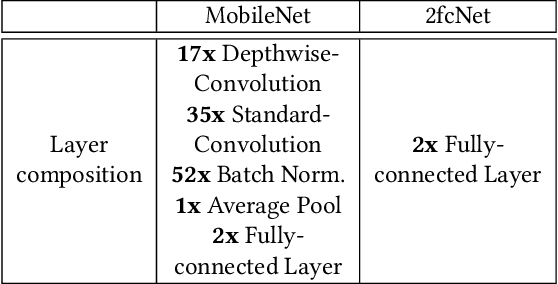


Parallel accelerators, such as GPUs, are key enablers for large-scale Machine Learning (ML) applications. However, ML model developers often lack detailed knowledge of the underlying system architectures, while system programmers usually do not have a high-level understanding of the ML model that runs on the specific system. To mitigate this gap between two relevant aspects of domain knowledge, this paper proposes GEVO-ML, a tool for automatically discovering optimization opportunities and tuning the performance of ML kernels, where the model and training/prediction processes are uniformly represented in a single intermediate language, the Multiple-Layer Intermediate Representation (MLIR). GEVO-ML uses multi-objective evolutionary search to find edits (mutations) to MLIR code that ultimately runs on GPUs, improving performance on desired criteria while retaining required functionality. We demonstrate GEVO-ML on two different ML workloads for both model training and prediction. GEVO-ML finds significant Pareto improvements for these models, achieving 90.43% performance improvement when model accuracy is relaxed by 2%, from 91.2% to 89.3%. For the training workloads, GEVO-ML finds a 4.88% improvement in model accuracy, from 91% to 96%, without sacrificing training or testing speed. Our analysis of key GEVO-ML mutations reveals diverse code modifications, while might be foreign to human developers, achieving similar effects with how human developers improve model design, for example, by changing learning rates or pruning non-essential layer parameters.