 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Series Prediction under Distribution Shift using Differentiable Forgetting
Jul 23, 2022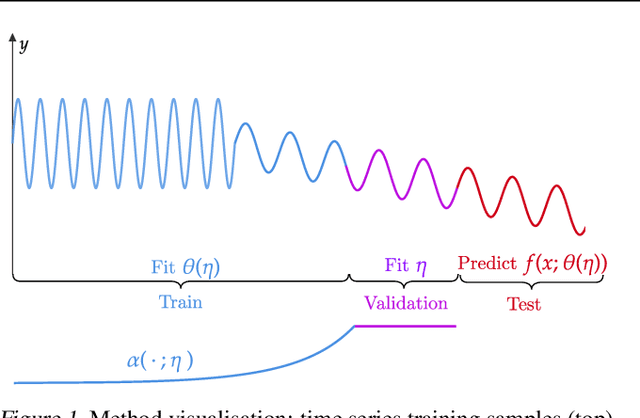

Time series prediction is often complicated by distribution shift which demands adaptive models to accommodate time-varying distributions. We frame time series prediction under distribution shift as a weighted empirical risk minimisation problem. The weighting of previous observations in the empirical risk is determined by a forgetting mechanism which controls the trade-off between the relevancy and effective sample size that is used for the estimation of the predictive model. In contrast to previous work, we propose a gradient-based learning method for the parameters of the forgetting mechanism. This speeds up optimisation and therefore allows more expressive forgetting mechanisms.
Lead-lag detection and network clustering for multivariate time series with an application to the US equity market
Jan 20, 2022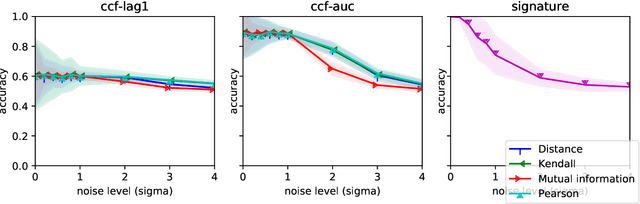

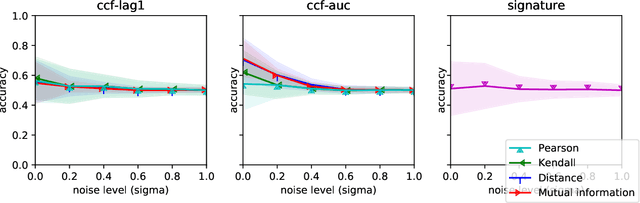

In multivariate time series systems, it has been observed that certain groups of variables partially lead the evolution of the system, while other variables follow this evolution with a time delay; the result is a lead-lag structure amongst the time series variables. In this paper, we propose a method for the detection of lead-lag clusters of time series in multivariate systems. We demonstrate that the web of pairwise lead-lag relationships between time series can be helpfully construed as a directed network, for which there exist suitable algorithms for the detection of pairs of lead-lag clusters with high pairwise imbalance. Within our framework, we consider a number of choices for the pairwise lead-lag metric and directed network clustering components. Our framework is validated on both a synthetic generative model for multivariate lead-lag time series systems and daily real-world US equity prices data. We showcase that our method is able to detect statistically significant lead-lag clusters in the US equity market. We study the nature of these clusters in the context of the empirical finance literature on lead-lag relations and demonstrate how these can be used for the construction of predictive financial signals.