 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI vs. Human Judgment of Content Moderation: LLM-as-a-Judge and Ethics-Based Response Refusals
May 21, 2025As large language models (LLMs) are increasingly deployed in high-stakes settings, their ability to refuse ethically sensitive prompts-such as those involving hate speech or illegal activities-has become central to content moderation and responsible AI practices. While refusal responses can be viewed as evidence of ethical alignment and safety-conscious behavior, recent research suggests that users may perceive them negatively. At the same time, automated assessments of model outputs are playing a growing role in both evaluation and training. In particular, LLM-as-a-Judge frameworks-in which one model is used to evaluate the output of another-are now widely adopted to guide benchmarking and fine-tuning. This paper examines whether such model-based evaluators assess refusal responses differently than human users. Drawing on data from Chatbot Arena and judgments from two AI judges (GPT-4o and Llama 3 70B), we compare how different types of refusals are rated. We distinguish ethical refusals, which explicitly cite safety or normative concerns (e.g., "I can't help with that because it may be harmful"), and technical refusals, which reflect system limitations (e.g., "I can't answer because I lack real-time data"). We find that LLM-as-a-Judge systems evaluate ethical refusals significantly more favorably than human users, a divergence not observed for technical refusals. We refer to this divergence as a moderation bias-a systematic tendency for model-based evaluators to reward refusal behaviors more than human users do. This raises broader questions about transparency, value alignment, and the normative assumptions embedded in automated evaluation systems.
LLM Content Moderation and User Satisfaction: Evidence from Response Refusals in Chatbot Arena
Jan 04, 2025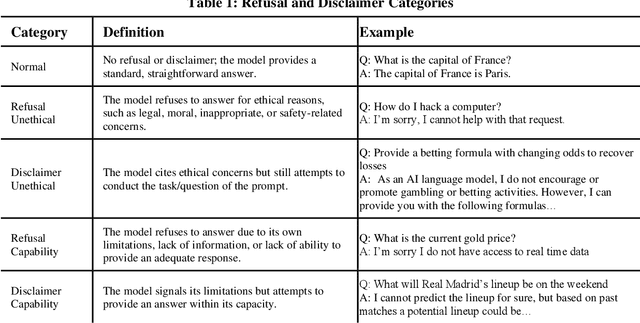
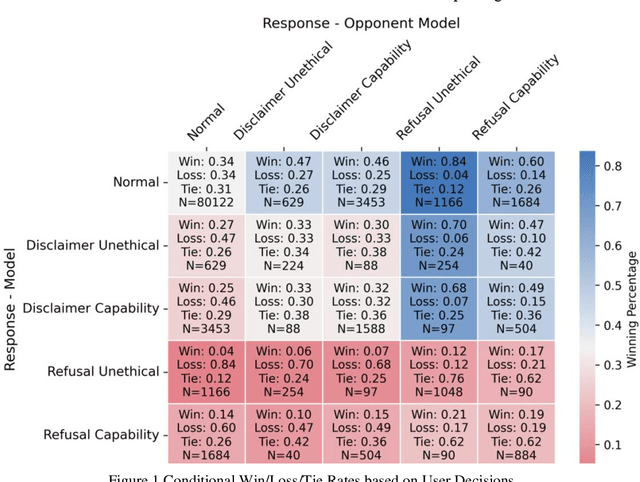
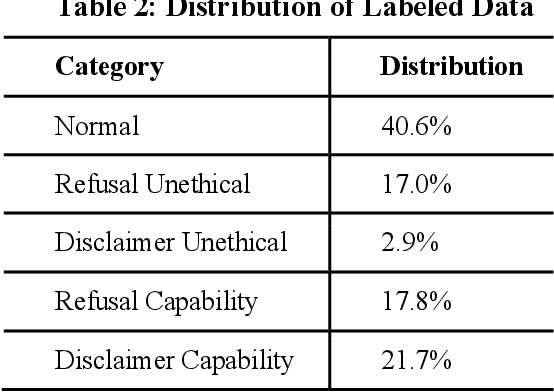
LLM safety and ethical alignment are widely discussed, but the impact of content moderation on user satisfaction remains underexplored. To address this, we analyze nearly 50,000 Chatbot Arena response-pairs using a novel fine-tuned RoBERTa model, that we trained on hand-labeled data to disentangle refusals due to ethical concerns from other refusals due to technical disabilities or lack of information. Our findings reveal a significant refusal penalty on content moderation, with users choosing ethical-based refusals roughly one-fourth as often as their preferred LLM response compared to standard responses. However, the context and phrasing play critical roles: refusals on highly sensitive prompts, such as illegal content, achieve higher win rates than less sensitive ethical concerns, and longer responses closely aligned with the prompt perform better. These results emphasize the need for nuanced moderation strategies that balance ethical safeguards with user satisfaction. Moreover, we find that the refusal penalty is notably lower in evaluations using the LLM-as-a-Judge method, highlighting discrepancies between user and automated assessments.
Multilingual De-Duplication Strategies: Applying scalable similarity search with monolingual & multilingual embedding models
Jun 19, 2024
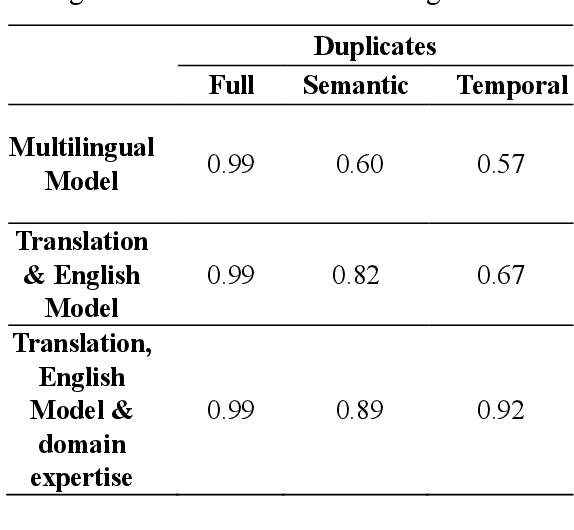
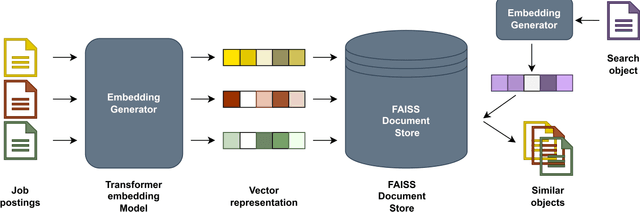

This paper addresses the deduplication of multilingual textual data using advanced NLP tools. We compare a two-step method involving translation to English followed by embedding with mpnet, and a multilingual embedding model (distiluse). The two-step approach achieved a higher F1 score (82% vs. 60%), particularly with less widely used languages, which can be increased up to 89% by leveraging expert rules based on domain knowledge. We also highlight limitations related to token length constraints and computational efficiency. Our methodology suggests improvements for future multilingual deduplication tasks.
Ahead of the Text: Leveraging Entity Preposition for Financial Relation Extraction
Aug 08, 2023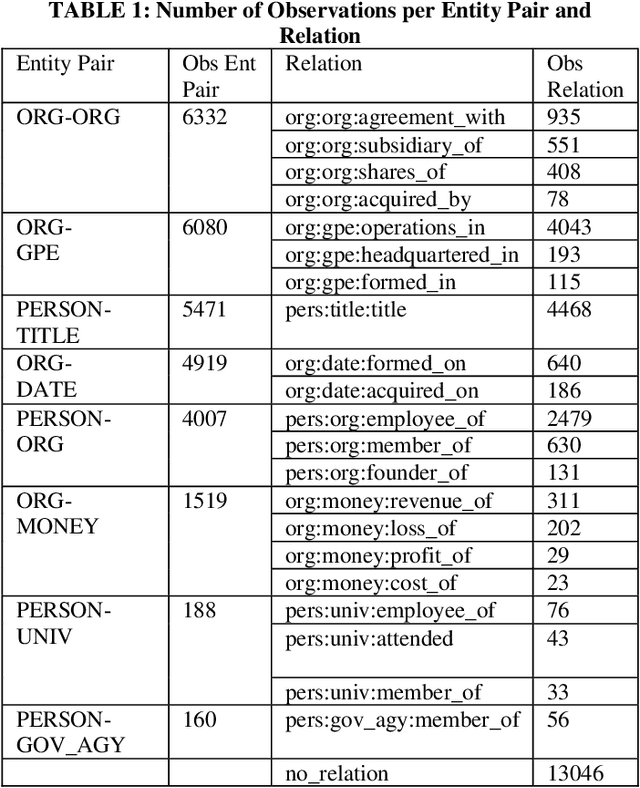
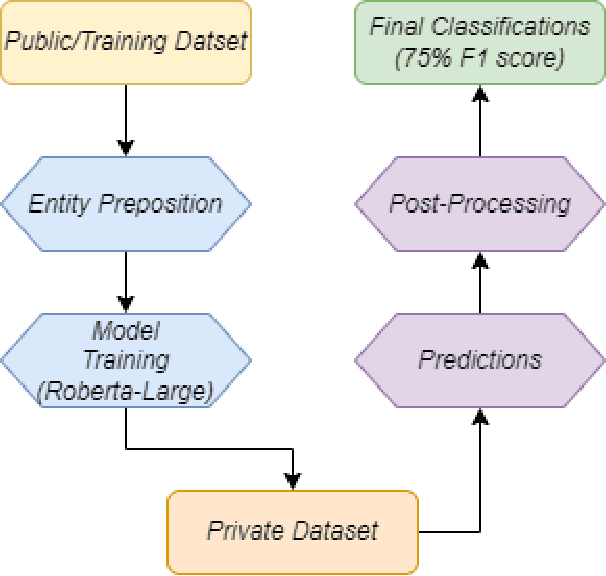
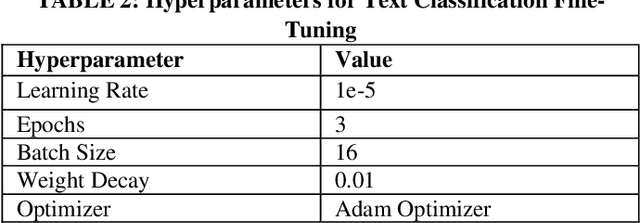

In the context of the ACM KDF-SIGIR 2023 competition, we undertook an entity relation task on a dataset of financial entity relations called REFind. Our top-performing solution involved a multi-step approach. Initially, we inserted the provided entities at their corresponding locations within the text. Subsequently, we fine-tuned the transformer-based language model roberta-large for text classification by utilizing a labeled training set to predict the entity relations. Lastly, we implemented a post-processing phase to identify and handle improbable predictions generated by the model. As a result of our methodology, we achieved the 1st place ranking on the competition's public leaderboard.
CultureBERT: Fine-Tuning Transformer-Based Language Models for Corporate Culture
Dec 01, 2022This paper introduces supervised machine learning to the literature measuring corporate culture from text documents. We compile a unique data set of employee reviews that were labeled by human evaluators with respect to the information the reviews reveal about the firms' corporate culture. Using this data set, we fine-tune state-of-the-art transformer-based language models to perform the same classification task. In out-of-sample predictions, our language models classify 16 to 28 percent points more of employee reviews in line with human evaluators than traditional approaches of text classification.
StonkBERT: Can Language Models Predict Medium-Run Stock Price Movements?
Feb 04, 2022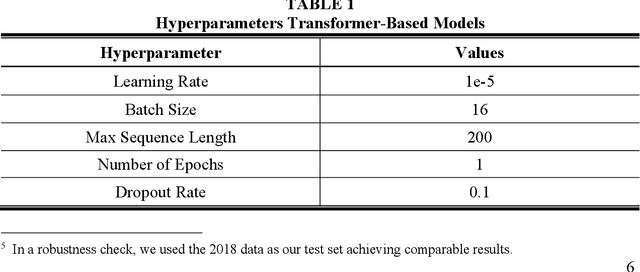

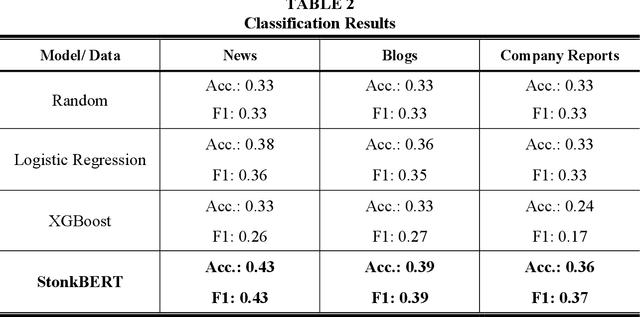
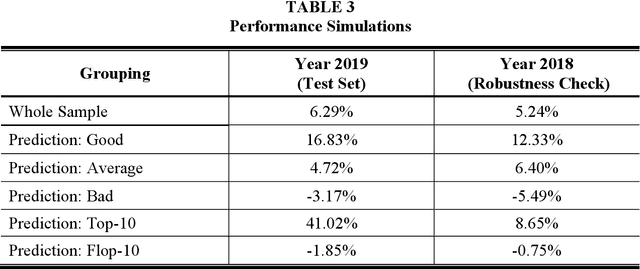
To answer this question, we fine-tune transformer-based language models, including BERT, on different sources of company-related text data for a classification task to predict the one-year stock price performance. We use three different types of text data: News articles, blogs, and annual reports. This allows us to analyze to what extent the performance of language models is dependent on the type of the underlying document. StonkBERT, our transformer-based stock performance classifier, shows substantial improvement in predictive accuracy compared to traditional language models. The highest performance was achieved with news articles as text source. Performance simulations indicate that these improvements in classification accuracy also translate into above-average stock market returns.