Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAhead of the Text: Leveraging Entity Preposition for Financial Relation Extraction
Aug 08, 2023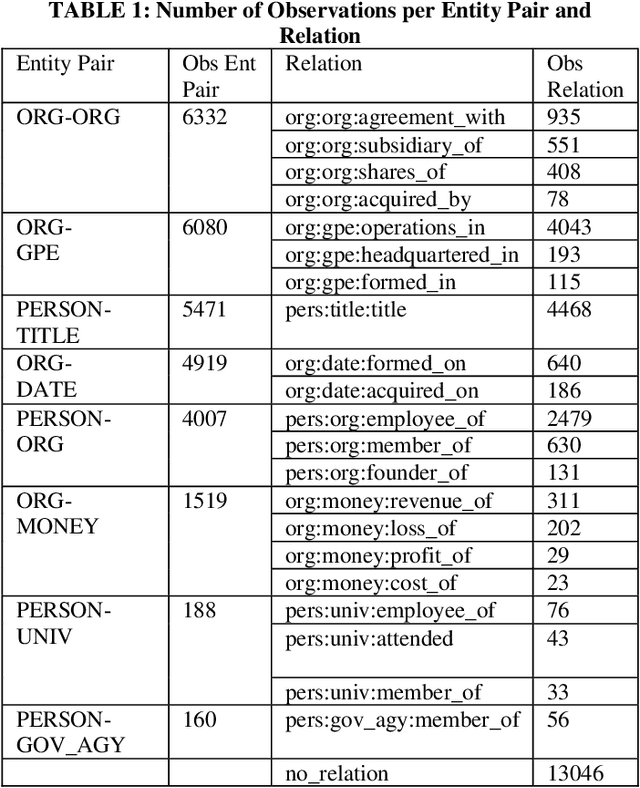
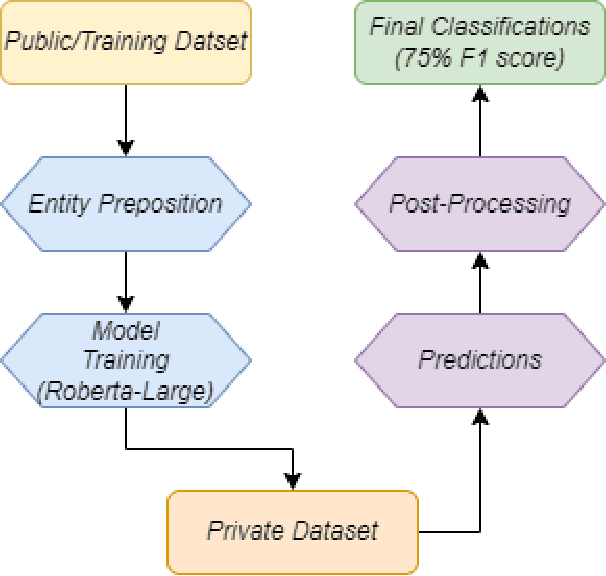
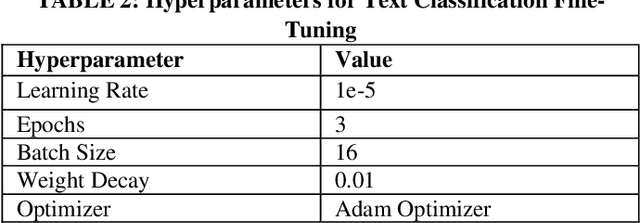

In the context of the ACM KDF-SIGIR 2023 competition, we undertook an entity relation task on a dataset of financial entity relations called REFind. Our top-performing solution involved a multi-step approach. Initially, we inserted the provided entities at their corresponding locations within the text. Subsequently, we fine-tuned the transformer-based language model roberta-large for text classification by utilizing a labeled training set to predict the entity relations. Lastly, we implemented a post-processing phase to identify and handle improbable predictions generated by the model. As a result of our methodology, we achieved the 1st place ranking on the competition's public leaderboard.
* Stefan Pasch, Dimitrios Petridis 2023. Ahead of the Text: Leveraging
Entity Preposition for Financial Relation Extraction. ACM SIGIR: The 4th
Workshop on Knowledge Discovery from Unstructured Data in Financial Services
(SIGIR-KDF '23)
Via