Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual De-Duplication Strategies: Applying scalable similarity search with monolingual & multilingual embedding models
Paper and Code

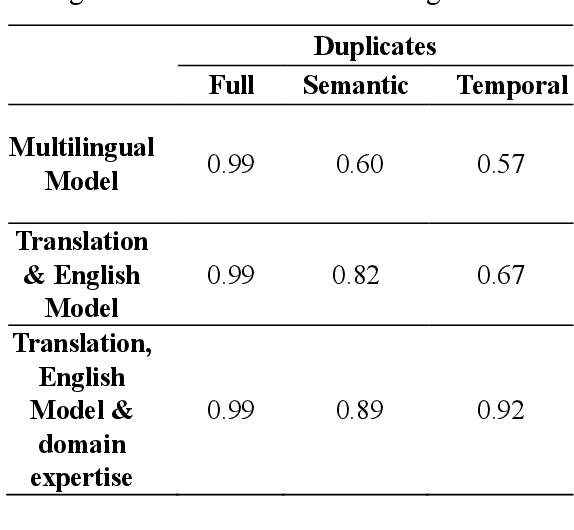
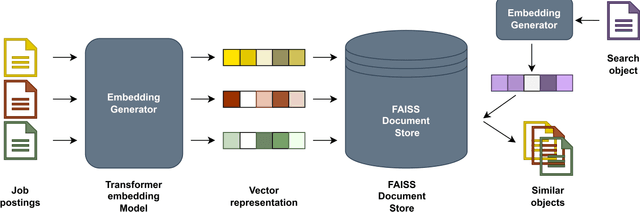

This paper addresses the deduplication of multilingual textual data using advanced NLP tools. We compare a two-step method involving translation to English followed by embedding with mpnet, and a multilingual embedding model (distiluse). The two-step approach achieved a higher F1 score (82% vs. 60%), particularly with less widely used languages, which can be increased up to 89% by leveraging expert rules based on domain knowledge. We also highlight limitations related to token length constraints and computational efficiency. Our methodology suggests improvements for future multilingual deduplication tasks.
* 6 pages, 3 figures
View paper on