 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStonkBERT: Can Language Models Predict Medium-Run Stock Price Movements?
Feb 04, 2022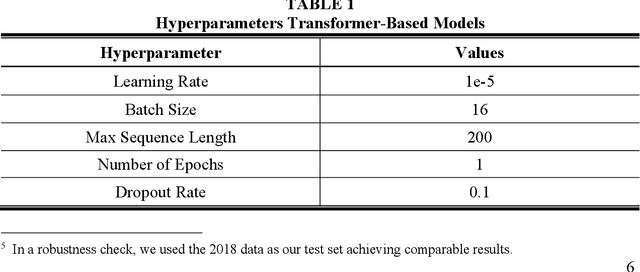

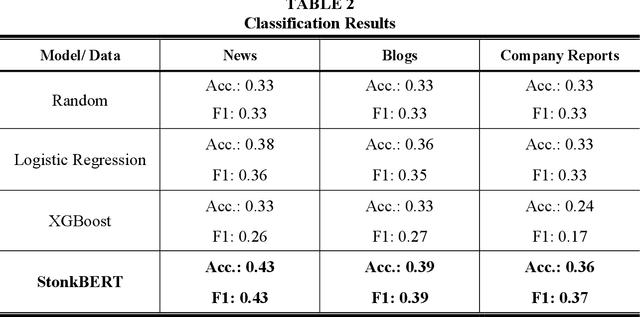
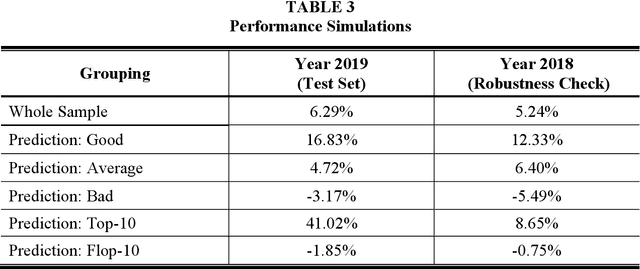
To answer this question, we fine-tune transformer-based language models, including BERT, on different sources of company-related text data for a classification task to predict the one-year stock price performance. We use three different types of text data: News articles, blogs, and annual reports. This allows us to analyze to what extent the performance of language models is dependent on the type of the underlying document. StonkBERT, our transformer-based stock performance classifier, shows substantial improvement in predictive accuracy compared to traditional language models. The highest performance was achieved with news articles as text source. Performance simulations indicate that these improvements in classification accuracy also translate into above-average stock market returns.