 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedLoRD: A Medical Low-Resource Diffusion Model for High-Resolution 3D CT Image Synthesis
Mar 17, 2025



Advancements in AI for medical imaging offer significant potential. However, their applications are constrained by the limited availability of data and the reluctance of medical centers to share it due to patient privacy concerns. Generative models present a promising solution by creating synthetic data as a substitute for real patient data. However, medical images are typically high-dimensional, and current state-of-the-art methods are often impractical for computational resource-constrained healthcare environments. These models rely on data sub-sampling, raising doubts about their feasibility and real-world applicability. Furthermore, many of these models are evaluated on quantitative metrics that alone can be misleading in assessing the image quality and clinical meaningfulness of the generated images. To address this, we introduce MedLoRD, a generative diffusion model designed for computational resource-constrained environments. MedLoRD is capable of generating high-dimensional medical volumes with resolutions up to 512$\times$512$\times$256, utilizing GPUs with only 24GB VRAM, which are commonly found in standard desktop workstations. MedLoRD is evaluated across multiple modalities, including Coronary Computed Tomography Angiography and Lung Computed Tomography datasets. Extensive evaluations through radiological evaluation, relative regional volume analysis, adherence to conditional masks, and downstream tasks show that MedLoRD generates high-fidelity images closely adhering to segmentation mask conditions, surpassing the capabilities of current state-of-the-art generative models for medical image synthesis in computational resource-constrained environments.
Unconditional Latent Diffusion Models Memorize Patient Imaging Data
Feb 01, 2024



Generative latent diffusion models hold a wide range of applications in the medical imaging domain. A noteworthy application is privacy-preserved open-data sharing by proposing synthetic data as surrogates of real patient data. Despite the promise, these models are susceptible to patient data memorization, where models generate patient data copies instead of novel synthetic samples. This undermines the whole purpose of preserving patient data and may even result in patient re-identification. Considering the importance of the problem, surprisingly it has received relatively little attention in the medical imaging community. To this end, we assess memorization in latent diffusion models for medical image synthesis. We train 2D and 3D latent diffusion models on CT, MR, and X-ray datasets for synthetic data generation. Afterwards, we examine the amount of training data memorized utilizing self-supervised models and further investigate various factors that can possibly lead to memorization by training models in different settings. We observe a surprisingly large amount of data memorization among all datasets, with up to 41.7%, 19.6%, and 32.6% of the training data memorized in CT, MRI, and X-ray datasets respectively. Further analyses reveal that increasing training data size and using data augmentation reduce memorization, while over-training enhances it. Overall, our results suggest a call for memorization-informed evaluation of synthetic data prior to open-data sharing.
Investigating Data Memorization in 3D Latent Diffusion Models for Medical Image Synthesis
Jul 06, 2023

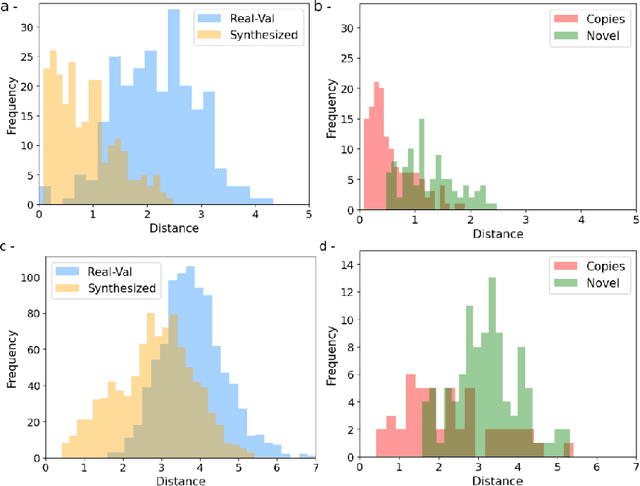

Generative latent diffusion models have been established as state-of-the-art in data generation. One promising application is generation of realistic synthetic medical imaging data for open data sharing without compromising patient privacy. Despite the promise, the capacity of such models to memorize sensitive patient training data and synthesize samples showing high resemblance to training data samples is relatively unexplored. Here, we assess the memorization capacity of 3D latent diffusion models on photon-counting coronary computed tomography angiography and knee magnetic resonance imaging datasets. To detect potential memorization of training samples, we utilize self-supervised models based on contrastive learning. Our results suggest that such latent diffusion models indeed memorize training data, and there is a dire need for devising strategies to mitigate memorization.