 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCardioDiT: Latent Diffusion Transformers for 4D Cardiac MRI Synthesis
Mar 26, 2026Latent diffusion models (LDMs) have recently achieved strong performance in 3D medical image synthesis. However, modalities like cine cardiac MRI (CMR), representing a temporally synchronized 3D volume across the cardiac cycle, add an additional dimension that most generative approaches do not model directly. Instead, they factorize space and time or enforce temporal consistency through auxiliary mechanisms such as anatomical masks. Such strategies introduce structural biases that may limit global context integration and lead to subtle spatiotemporal discontinuities or physiologically inconsistent cardiac dynamics. We investigate whether a unified 4D generative model can learn continuous cardiac dynamics without architectural factorization. We propose CardioDiT, a fully 4D latent diffusion framework for short-axis cine CMR synthesis based on diffusion transformers. A spatiotemporal VQ-VAE encodes 2D+t slices into compact latents, which a diffusion transformer then models jointly as complete 3D+t volumes, coupling space and time throughout the generative process. We evaluate CardioDiT on public CMR datasets and a larger private cohort, comparing it to baselines with progressively stronger spatiotemporal coupling. Results show improved inter-slice consistency, temporally coherent motion, and realistic cardiac function distributions, suggesting that explicit 4D modeling with a diffusion transformer provides a principled foundation for spatiotemporal cardiac image synthesis. Code and models trained on public data are available at https://github.com/Cardio-AI/cardiodit.
VolDiT: Controllable Volumetric Medical Image Synthesis with Diffusion Transformers
Mar 26, 2026Diffusion models have become a leading approach for high-fidelity medical image synthesis. However, most existing methods for 3D medical image generation rely on convolutional U-Net backbones within latent diffusion frameworks. While effective, these architectures impose strong locality biases and limited receptive fields, which may constrain scalability, global context integration, and flexible conditioning. In this work, we introduce VolDiT, the first purely transformer-based 3D Diffusion Transformer for volumetric medical image synthesis. Our approach extends diffusion transformers to native 3D data through volumetric patch embeddings and global self-attention operating directly over 3D tokens. To enable structured control, we propose a timestep-gated control adapter that maps segmentation masks into learnable control tokens that modulate transformer layers during denoising. This token-level conditioning mechanism allows precise spatial guidance while preserving the modeling advantages of transformer architectures. We evaluate our model on high-resolution 3D medical image synthesis tasks and compare it to state-of-the-art 3D latent diffusion models based on U-Nets. Results demonstrate improved global coherence, superior generative fidelity, and enhanced controllability. Our findings suggest that fully transformerbased diffusion models provide a flexible foundation for volumetric medical image synthesis. The code and models trained on public data are available at https://github.com/Cardio-AI/voldit.
MedLoRD: A Medical Low-Resource Diffusion Model for High-Resolution 3D CT Image Synthesis
Mar 17, 2025



Advancements in AI for medical imaging offer significant potential. However, their applications are constrained by the limited availability of data and the reluctance of medical centers to share it due to patient privacy concerns. Generative models present a promising solution by creating synthetic data as a substitute for real patient data. However, medical images are typically high-dimensional, and current state-of-the-art methods are often impractical for computational resource-constrained healthcare environments. These models rely on data sub-sampling, raising doubts about their feasibility and real-world applicability. Furthermore, many of these models are evaluated on quantitative metrics that alone can be misleading in assessing the image quality and clinical meaningfulness of the generated images. To address this, we introduce MedLoRD, a generative diffusion model designed for computational resource-constrained environments. MedLoRD is capable of generating high-dimensional medical volumes with resolutions up to 512$\times$512$\times$256, utilizing GPUs with only 24GB VRAM, which are commonly found in standard desktop workstations. MedLoRD is evaluated across multiple modalities, including Coronary Computed Tomography Angiography and Lung Computed Tomography datasets. Extensive evaluations through radiological evaluation, relative regional volume analysis, adherence to conditional masks, and downstream tasks show that MedLoRD generates high-fidelity images closely adhering to segmentation mask conditions, surpassing the capabilities of current state-of-the-art generative models for medical image synthesis in computational resource-constrained environments.
Latent Pollution Model: The Hidden Carbon Footprint in 3D Image Synthesis
Jul 20, 2024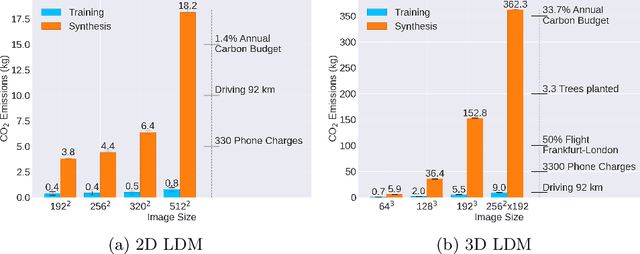
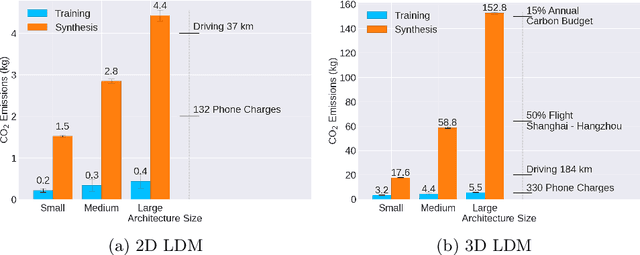
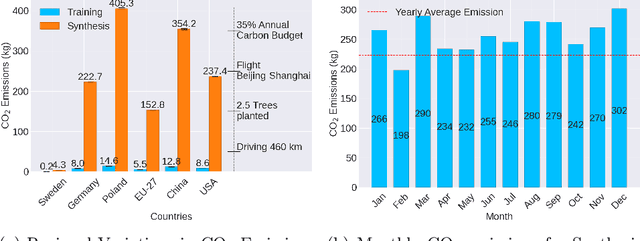
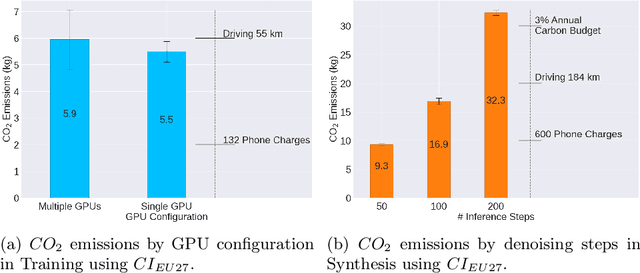
Contemporary developments in generative AI are rapidly transforming the field of medical AI. These developments have been predominantly driven by the availability of large datasets and high computing power, which have facilitated a significant increase in model capacity. Despite their considerable potential, these models demand substantially high power, leading to high carbon dioxide (CO2) emissions. Given the harm such models are causing to the environment, there has been little focus on the carbon footprints of such models. This study analyzes carbon emissions from 2D and 3D latent diffusion models (LDMs) during training and data generation phases, revealing a surprising finding: the synthesis of large images contributes most significantly to these emissions. We assess different scenarios including model sizes, image dimensions, distributed training, and data generation steps. Our findings reveal substantial carbon emissions from these models, with training 2D and 3D models comparable to driving a car for 10 km and 90 km, respectively. The process of data generation is even more significant, with CO2 emissions equivalent to driving 160 km for 2D models and driving for up to 3345 km for 3D synthesis. Additionally, we found that the location of the experiment can increase carbon emissions by up to 94 times, and even the time of year can influence emissions by up to 50%. These figures are alarming, considering they represent only a single training and data generation phase for each model. Our results emphasize the urgent need for developing environmentally sustainable strategies in generative AI.
Unconditional Latent Diffusion Models Memorize Patient Imaging Data
Feb 01, 2024



Generative latent diffusion models hold a wide range of applications in the medical imaging domain. A noteworthy application is privacy-preserved open-data sharing by proposing synthetic data as surrogates of real patient data. Despite the promise, these models are susceptible to patient data memorization, where models generate patient data copies instead of novel synthetic samples. This undermines the whole purpose of preserving patient data and may even result in patient re-identification. Considering the importance of the problem, surprisingly it has received relatively little attention in the medical imaging community. To this end, we assess memorization in latent diffusion models for medical image synthesis. We train 2D and 3D latent diffusion models on CT, MR, and X-ray datasets for synthetic data generation. Afterwards, we examine the amount of training data memorized utilizing self-supervised models and further investigate various factors that can possibly lead to memorization by training models in different settings. We observe a surprisingly large amount of data memorization among all datasets, with up to 41.7%, 19.6%, and 32.6% of the training data memorized in CT, MRI, and X-ray datasets respectively. Further analyses reveal that increasing training data size and using data augmentation reduce memorization, while over-training enhances it. Overall, our results suggest a call for memorization-informed evaluation of synthetic data prior to open-data sharing.