 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Inductive Invariant Based Verification of Neural Network Controlled Systems
Dec 17, 2023The integration of neural networks into safety-critical systems has shown great potential in recent years. However, the challenge of effectively verifying the safety of Neural Network Controlled Systems (NNCS) persists. This paper introduces a novel approach to NNCS safety verification, leveraging the inductive invariant method. Verifying the inductiveness of a candidate inductive invariant in the context of NNCS is hard because of the scale and nonlinearity of neural networks. Our compositional method makes this verification process manageable by decomposing the inductiveness proof obligation into smaller, more tractable subproblems. Alongside the high-level method, we present an algorithm capable of automatically verifying the inductiveness of given candidates by automatically inferring the necessary decomposition predicates. The algorithm significantly outperforms the baseline method and shows remarkable reductions in execution time in our case studies, shortening the verification time from hours (or timeout) to seconds.
On Neural Network Equivalence Checking using SMT Solvers
Mar 22, 2022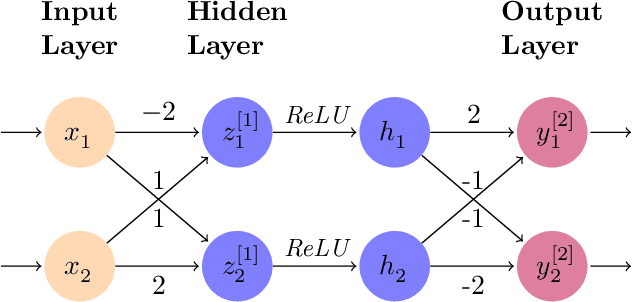

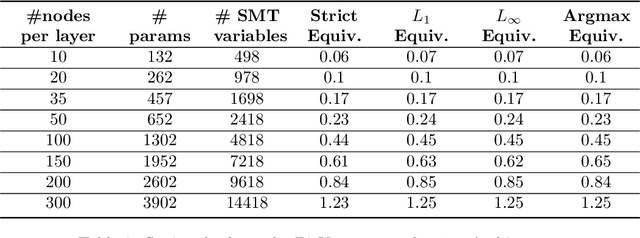
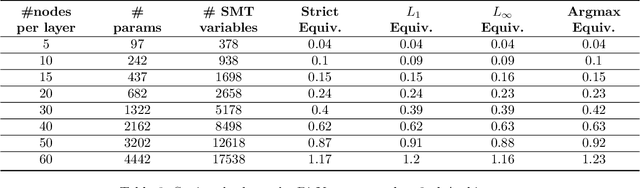
Two pretrained neural networks are deemed equivalent if they yield similar outputs for the same inputs. Equivalence checking of neural networks is of great importance, due to its utility in replacing learning-enabled components with equivalent ones, when there is need to fulfill additional requirements or to address security threats, as is the case for example when using knowledge distillation, adversarial training etc. SMT solvers can potentially provide solutions to the problem of neural network equivalence checking that will be sound and complete, but as it is expected any such solution is associated with significant limitations with respect to the size of neural networks to be checked. This work presents a first SMT-based encoding of the equivalence checking problem, explores its utility and limitations and proposes avenues for future research and improvements towards more scalable and practically applicable solutions. We present experimental results that shed light to the aforementioned issues, for diverse types of neural network models (classifiers and regression networks) and equivalence criteria, towards a general and application-independent equivalence checking approach.
Adversarial Robustness Verification and Attack Synthesis in Stochastic Systems
Oct 05, 2021

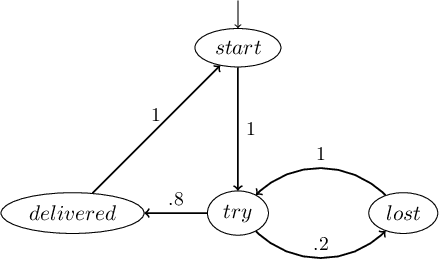

Probabilistic model checking is a useful technique for specifying and verifying properties of stochastic systems including randomized protocols and the theoretical underpinnings of reinforcement learning models. However, these methods rely on the assumed structure and probabilities of certain system transitions. These assumptions may be incorrect, and may even be violated in the event that an adversary gains control of some or all components in the system. In this paper, motivated by research in adversarial machine learning on adversarial examples, we develop a formal framework for adversarial robustness in systems defined as discrete time Markov chains (DTMCs), and extend to include deterministic, memoryless policies acting in Markov decision processes (MDPs). Our framework includes a flexible approach for specifying several adversarial models with different capabilities to manipulate the system. We outline a class of threat models under which adversaries can perturb system transitions, constrained by an $\varepsilon$ ball around the original transition probabilities and define four specific instances of this threat model. We define three main DTMC adversarial robustness problems and present two optimization-based solutions, leveraging traditional and parametric probabilistic model checking techniques. We then evaluate our solutions on two stochastic protocols and a collection of GridWorld case studies, which model an agent acting in an environment described as an MDP. We find that the parametric solution results in fast computation for small parameter spaces. In the case of less restrictive (stronger) adversaries, the number of parameters increases, and directly computing property satisfaction probabilities is more scalable. We demonstrate the usefulness of our definitions and solutions by comparing system outcomes over various properties, threat models, and case studies.
Metrics and methods for robustness evaluation of neural networks with generative models
Mar 15, 2020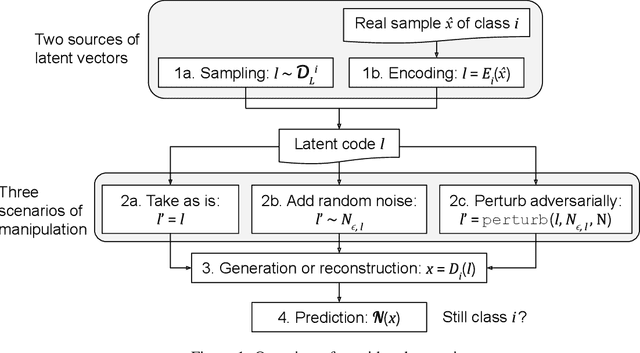
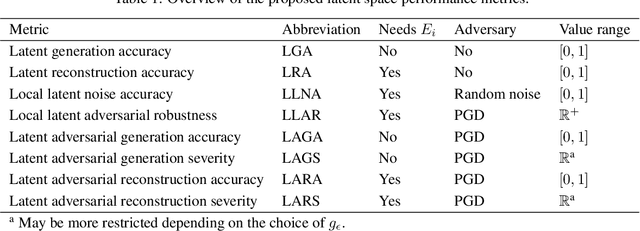

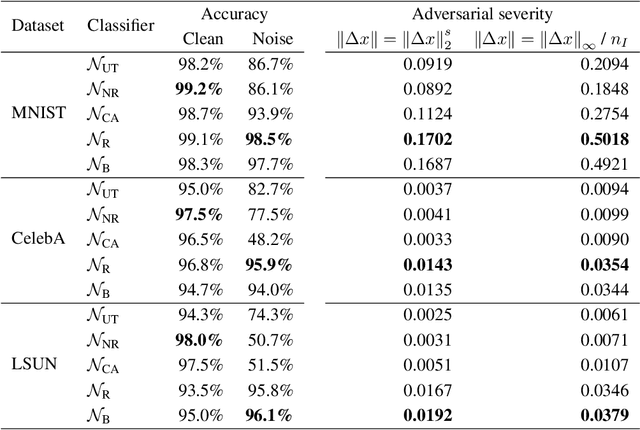
Recent studies have shown that modern deep neural network classifiers are easy to fool, assuming that an adversary is able to slightly modify their inputs. Many papers have proposed adversarial attacks, defenses and methods to measure robustness to such adversarial perturbations. However, most commonly considered adversarial examples are based on $\ell_p$-bounded perturbations in the input space of the neural network, which are unlikely to arise naturally. Recently, especially in computer vision, researchers discovered "natural" or "semantic" perturbations, such as rotations, changes of brightness, or more high-level changes, but these perturbations have not yet been systematically utilized to measure the performance of classifiers. In this paper, we propose several metrics to measure robustness of classifiers to natural adversarial examples, and methods to evaluate them. These metrics, called latent space performance metrics, are based on the ability of generative models to capture probability distributions, and are defined in their latent spaces. On three image classification case studies, we evaluate the proposed metrics for several classifiers, including ones trained in conventional and robust ways. We find that the latent counterparts of adversarial robustness are associated with the accuracy of the classifier rather than its conventional adversarial robustness, but the latter is still reflected on the properties of found latent perturbations. In addition, our novel method of finding latent adversarial perturbations demonstrates that these perturbations are often perceptually small.
Learning Moore Machines from Input-Output Traces
Sep 02, 2016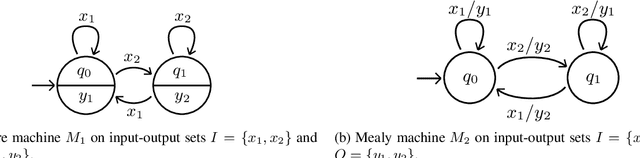
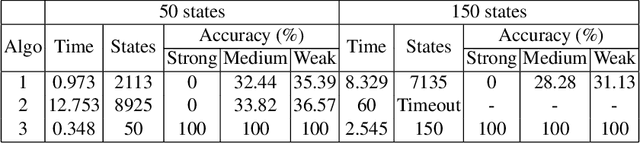

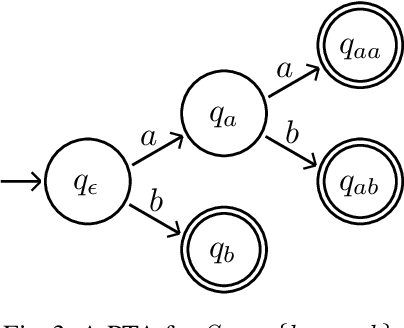
The problem of learning automata from example traces (but no equivalence or membership queries) is fundamental in automata learning theory and practice. In this paper we study this problem for finite state machines with inputs and outputs, and in particular for Moore machines. We develop three algorithms for solving this problem: (1) the PTAP algorithm, which transforms a set of input-output traces into an incomplete Moore machine and then completes the machine with self-loops; (2) the PRPNI algorithm, which uses the well-known RPNI algorithm for automata learning to learn a product of automata encoding a Moore machine; and (3) the MooreMI algorithm, which directly learns a Moore machine using PTAP extended with state merging. We prove that MooreMI has the fundamental identification in the limit property. We also compare the algorithms experimentally in terms of the size of the learned machine and several notions of accuracy, introduced in this paper. Finally, we compare with OSTIA, an algorithm that learns a more general class of transducers, and find that OSTIA generally does not learn a Moore machine, even when fed with a characteristic sample.