 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Robustness Verification and Attack Synthesis in Stochastic Systems
Oct 05, 2021

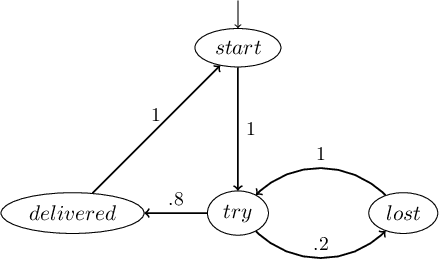

Probabilistic model checking is a useful technique for specifying and verifying properties of stochastic systems including randomized protocols and the theoretical underpinnings of reinforcement learning models. However, these methods rely on the assumed structure and probabilities of certain system transitions. These assumptions may be incorrect, and may even be violated in the event that an adversary gains control of some or all components in the system. In this paper, motivated by research in adversarial machine learning on adversarial examples, we develop a formal framework for adversarial robustness in systems defined as discrete time Markov chains (DTMCs), and extend to include deterministic, memoryless policies acting in Markov decision processes (MDPs). Our framework includes a flexible approach for specifying several adversarial models with different capabilities to manipulate the system. We outline a class of threat models under which adversaries can perturb system transitions, constrained by an $\varepsilon$ ball around the original transition probabilities and define four specific instances of this threat model. We define three main DTMC adversarial robustness problems and present two optimization-based solutions, leveraging traditional and parametric probabilistic model checking techniques. We then evaluate our solutions on two stochastic protocols and a collection of GridWorld case studies, which model an agent acting in an environment described as an MDP. We find that the parametric solution results in fast computation for small parameter spaces. In the case of less restrictive (stronger) adversaries, the number of parameters increases, and directly computing property satisfaction probabilities is more scalable. We demonstrate the usefulness of our definitions and solutions by comparing system outcomes over various properties, threat models, and case studies.
QFlip: An Adaptive Reinforcement Learning Strategy for the FlipIt Security Game
Aug 14, 2019



A rise in Advanced Persistent Threats (APTs) has introduced a need for robustness against long-running, stealthy attacks which circumvent existing cryptographic security guarantees. FlipIt is a security game that models attacker-defender interactions in advanced scenarios such as APTs. Previous work analyzed extensively non-adaptive strategies in FlipIt, but adaptive strategies rise naturally in practical interactions as players receive feedback during the game. We model the FlipIt game as a Markov Decision Process and introduce QFlip, an adaptive strategy for FlipIt based on temporal difference reinforcement learning. We prove theoretical results on the convergence of our new strategy against an opponent playing with a Periodic strategy. We confirm our analysis experimentally by extensive evaluation of QFlip against specific opponents. QFlip converges to the optimal adaptive strategy for Periodic and Exponential opponents using associated state spaces. Finally, we introduce a generalized QFlip strategy with composite state space that outperforms a Greedy strategy for several distributions including Periodic and Uniform, without prior knowledge of the opponent's strategy. We also release an OpenAI Gym environment for FlipIt to facilitate future research.