 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarially Optimized Mixup for Robust Classification
Mar 22, 2021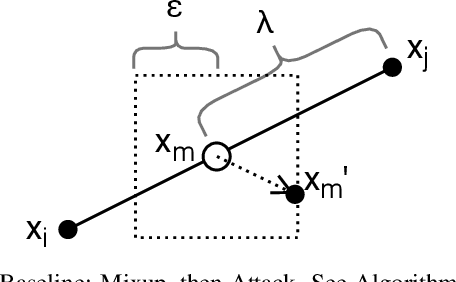
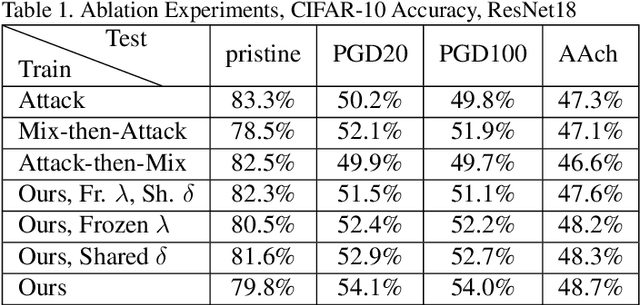
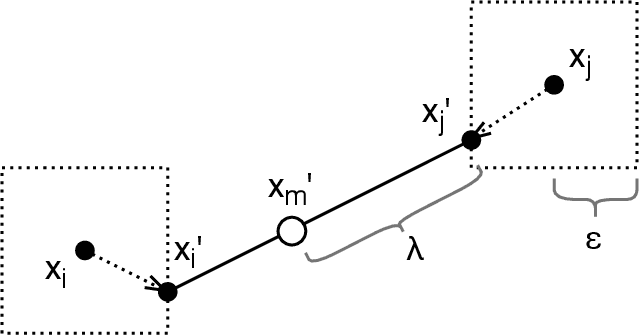
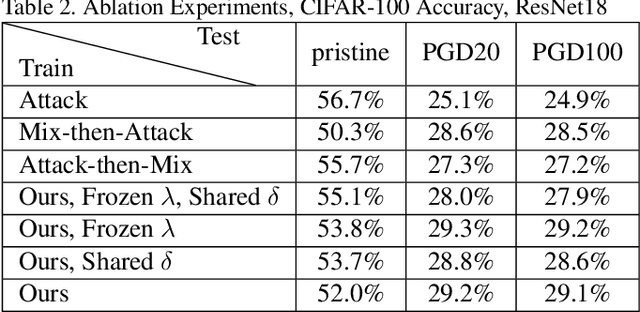
Mixup is a procedure for data augmentation that trains networks to make smoothly interpolated predictions between datapoints. Adversarial training is a strong form of data augmentation that optimizes for worst-case predictions in a compact space around each data-point, resulting in neural networks that make much more robust predictions. In this paper, we bring these ideas together by adversarially probing the space between datapoints, using projected gradient descent (PGD). The fundamental approach in this work is to leverage backpropagation through the mixup interpolation during training to optimize for places where the network makes unsmooth and incongruous predictions. Additionally, we also explore several modifications and nuances, like optimization of the mixup ratio and geometrical label assignment, and discuss their impact on enhancing network robustness. Through these ideas, we have been able to train networks that robustly generalize better; experiments on CIFAR-10 and CIFAR-100 demonstrate consistent improvements in accuracy against strong adversaries, including the recent strong ensemble attack AutoAttack. Our source code would be released for reproducibility.
Attribution of Gradient Based Adversarial Attacks for Reverse Engineering of Deceptions
Mar 19, 2021
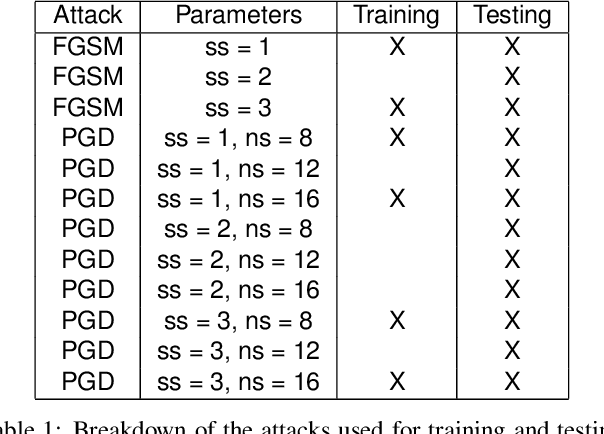
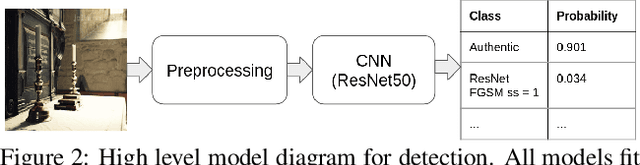
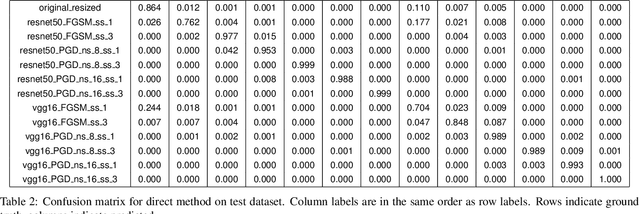
Machine Learning (ML) algorithms are susceptible to adversarial attacks and deception both during training and deployment. Automatic reverse engineering of the toolchains behind these adversarial machine learning attacks will aid in recovering the tools and processes used in these attacks. In this paper, we present two techniques that support automated identification and attribution of adversarial ML attack toolchains using Co-occurrence Pixel statistics and Laplacian Residuals. Our experiments show that the proposed techniques can identify parameters used to generate adversarial samples. To the best of our knowledge, this is the first approach to attribute gradient based adversarial attacks and estimate their parameters. Source code and data is available at: https://github.com/michael-goebel/ei_red