 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVehicle-to-Vehicle Charging: Model, Complexity, and Heuristics
Apr 12, 2024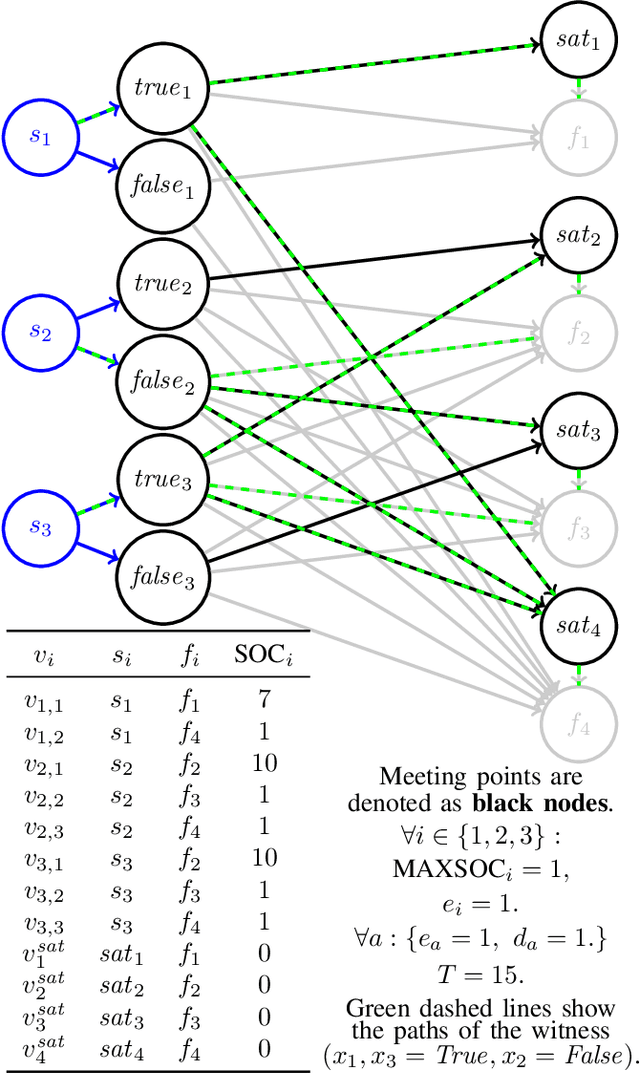
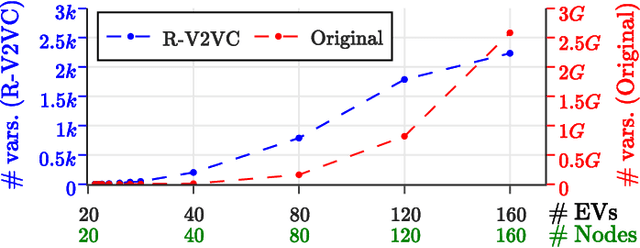
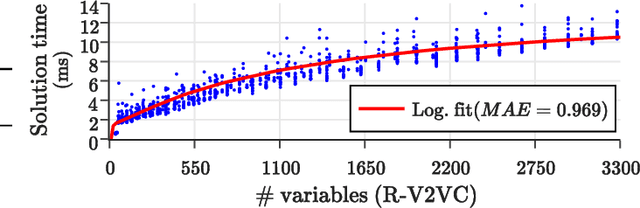
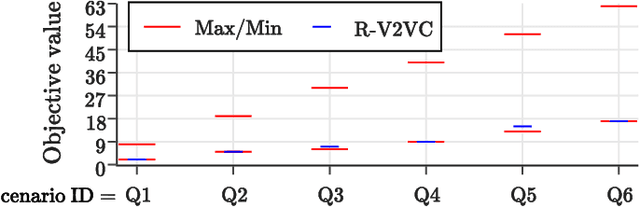
The rapid adoption of Electric Vehicles (EVs) poses challenges for electricity grids to accommodate or mitigate peak demand. Vehicle-to-Vehicle Charging (V2VC) has been recently adopted by popular EVs, posing new opportunities and challenges to the management and operation of EVs. We present a novel V2VC model that allows decision-makers to take V2VC into account when optimizing their EV operations. We show that optimizing V2VC is NP-Complete and find that even small problem instances are computationally challenging. We propose R-V2VC, a heuristic that takes advantage of the resulting totally unimodular constraint matrix to efficiently solve problems of realistic sizes. Our results demonstrate that R-V2VC presents a linear growth in the solution time as the problem size increases, while achieving solutions of optimal or near-optimal quality. R-V2VC can be used for real-world operations and to study what-if scenarios when evaluating the costs and benefits of V2VC.
Causal Inference With Selectively-Deconfounded Data
Feb 25, 2020
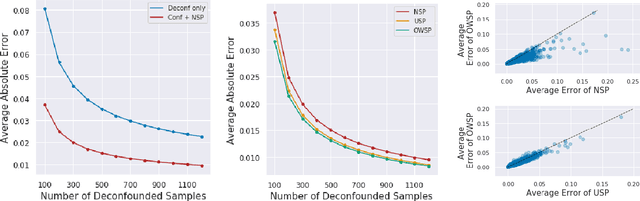
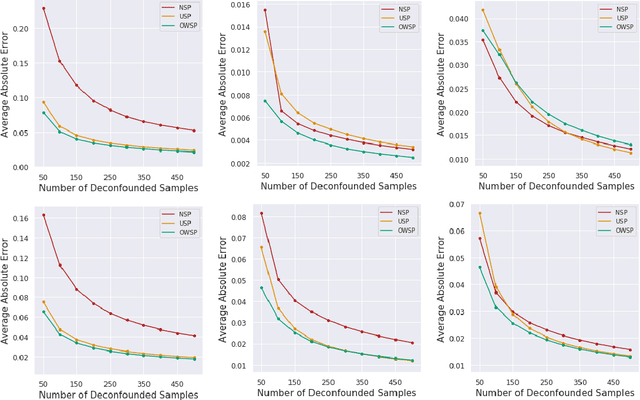
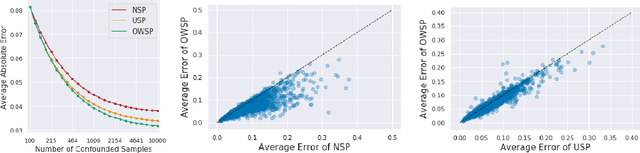
Given only data generated by a standard confounding graph with unobserved confounder, the Average Treatment Effect (ATE) is not identifiable. To estimate the ATE, a practitioner must then either (a) collect deconfounded data; (b) run a clinical trial; or (c) elucidate further properties of the causal graph that might render the ATE identifiable. In this paper, we consider the benefit of incorporating a (large) confounded observational dataset alongside a (small) deconfounded observational dataset when estimating the ATE. Our theoretical results show that the inclusion of confounded data can significantly reduce the quantity of deconfounded data required to estimate the ATE to within a desired accuracy level. Moreover, in some cases---say, genetics---we could imagine retrospectively selecting samples to deconfound. We demonstrate that by strategically selecting these examples based upon the (already observed) treatment and outcome, we can reduce our data dependence further. Our theoretical and empirical results establish that the worst-case relative performance of our approach (vs. a natural benchmark) is bounded while our best-case gains are unbounded. Next, we demonstrate the benefits of selective deconfounding using a large real-world dataset related to genetic mutation in cancer. Finally, we introduce an online version of the problem, proposing two adaptive heuristics.
The Topology of Mutated Driver Pathways
Nov 30, 2019
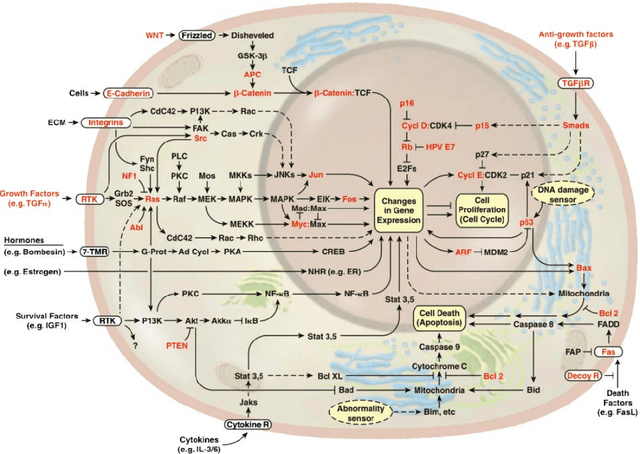
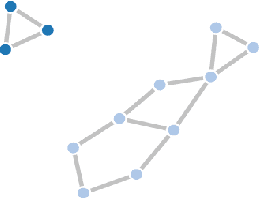
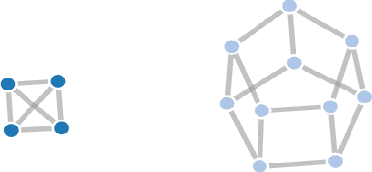
Much progress has been made, and continues to be made, towards identifying candidate mutated driver pathways in cancer. However, no systematic approach to understanding how candidate pathways relate to each other for a given cancer (such as Acute myeloid leukemia), and how one type of cancer may be similar or different from another with regard to their respective pathways (Acute myeloid leukemia vs. Glioblastoma multiforme for instance), has emerged thus far. Our work attempts to contribute to the understanding of {\em space of pathways} through a novel topological framework. We illustrate our approach, using mutation data (obtained from TCGA) of two types of tumors: Acute myeloid leukemia (AML) and Glioblastoma multiforme (GBM). We find that the space of pathways for AML is homotopy equivalent to a sphere, while that of GBM is equivalent to a genus-2 surface. We hope to trigger new types of questions (i.e., allow for novel kinds of hypotheses) towards a more comprehensive grasp of cancer.