 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning Smaller Language Models for Question Answering over Financial Documents
Aug 22, 2024



Recent research has shown that smaller language models can acquire substantial reasoning abilities when fine-tuned with reasoning exemplars crafted by a significantly larger teacher model. We explore this paradigm for the financial domain, focusing on the challenge of answering questions that require multi-hop numerical reasoning over financial texts. We assess the performance of several smaller models that have been fine-tuned to generate programs that encode the required financial reasoning and calculations. Our findings demonstrate that these fine-tuned smaller models approach the performance of the teacher model. To provide a granular analysis of model performance, we propose an approach to investigate the specific student model capabilities that are enhanced by fine-tuning. Our empirical analysis indicates that fine-tuning refines the student models ability to express and apply the required financial concepts along with adapting the entity extraction for the specific data format. In addition, we hypothesize and demonstrate that comparable financial reasoning capability can be induced using relatively smaller datasets.
Zero-Shot Question Answering over Financial Documents using Large Language Models
Nov 19, 2023



We introduce a large language model (LLM) based approach to answer complex questions requiring multi-hop numerical reasoning over financial reports. While LLMs have exhibited remarkable performance on various natural language and reasoning tasks, complex reasoning problems often rely on few-shot prompts that require carefully crafted examples. In contrast, our approach uses novel zero-shot prompts that guide the LLM to encode the required reasoning into a Python program or a domain specific language. The generated program is then executed by a program interpreter, thus mitigating the limitations of LLM in performing accurate arithmetic calculations. We evaluate the proposed approach on three financial datasets using some of the recently developed generative pretrained transformer (GPT) models and perform comparisons with various zero-shot baselines. The experimental results demonstrate that our approach significantly improves the accuracy for all the LLMs over their respective baselines. We provide a detailed analysis of the results, generating insights to support our findings. The success of our approach demonstrates the enormous potential to extract complex domain specific numerical reasoning by designing zero-shot prompts to effectively exploit the knowledge embedded in LLMs.
DeepPSL: End-to-end perception and reasoning with applications to zero shot learning
Oct 13, 2021
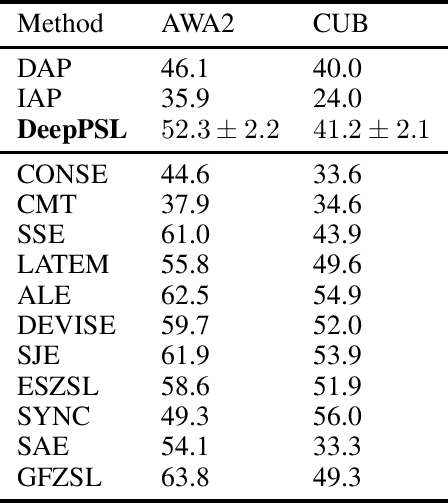

We introduce DeepPSL a variant of Probabilistic Soft Logic (PSL) to produce an end-to-end trainable system that integrates reasoning and perception. PSL represents first-order logic in terms of a convex graphical model -- Hinge Loss Markov random fields (HL-MRFs). PSL stands out among probabilistic logic frameworks due to its tractability having been applied to systems of more than 1 billion ground rules. The key to our approach is to represent predicates in first-order logic using deep neural networks and then to approximately back-propagate through the HL-MRF and thus train every aspect of the first-order system being represented. We believe that this approach represents an interesting direction for the integration of deep learning and reasoning techniques with applications to knowledge base learning, multi-task learning, and explainability. We evaluate DeepPSL on a zero shot learning problem in image classification. State of the art results demonstrate the utility and flexibility of our approach.