 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning Smaller Language Models for Question Answering over Financial Documents
Aug 22, 2024



Recent research has shown that smaller language models can acquire substantial reasoning abilities when fine-tuned with reasoning exemplars crafted by a significantly larger teacher model. We explore this paradigm for the financial domain, focusing on the challenge of answering questions that require multi-hop numerical reasoning over financial texts. We assess the performance of several smaller models that have been fine-tuned to generate programs that encode the required financial reasoning and calculations. Our findings demonstrate that these fine-tuned smaller models approach the performance of the teacher model. To provide a granular analysis of model performance, we propose an approach to investigate the specific student model capabilities that are enhanced by fine-tuning. Our empirical analysis indicates that fine-tuning refines the student models ability to express and apply the required financial concepts along with adapting the entity extraction for the specific data format. In addition, we hypothesize and demonstrate that comparable financial reasoning capability can be induced using relatively smaller datasets.
Zero-Shot Question Answering over Financial Documents using Large Language Models
Nov 19, 2023



We introduce a large language model (LLM) based approach to answer complex questions requiring multi-hop numerical reasoning over financial reports. While LLMs have exhibited remarkable performance on various natural language and reasoning tasks, complex reasoning problems often rely on few-shot prompts that require carefully crafted examples. In contrast, our approach uses novel zero-shot prompts that guide the LLM to encode the required reasoning into a Python program or a domain specific language. The generated program is then executed by a program interpreter, thus mitigating the limitations of LLM in performing accurate arithmetic calculations. We evaluate the proposed approach on three financial datasets using some of the recently developed generative pretrained transformer (GPT) models and perform comparisons with various zero-shot baselines. The experimental results demonstrate that our approach significantly improves the accuracy for all the LLMs over their respective baselines. We provide a detailed analysis of the results, generating insights to support our findings. The success of our approach demonstrates the enormous potential to extract complex domain specific numerical reasoning by designing zero-shot prompts to effectively exploit the knowledge embedded in LLMs.
The Role of Pragmatics in Legal Norm Representation
Jul 08, 2015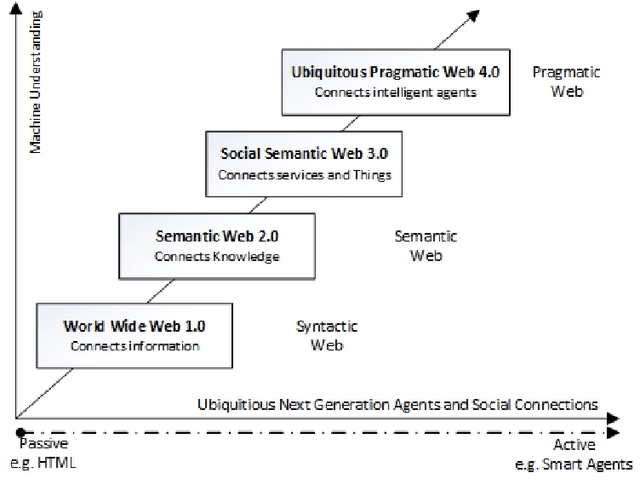
Despite the 'apparent clarity' of a given legal provision, its application may result in an outcome that does not exactly conform to the semantic level of a statute. The vagueness within a legal text is induced intentionally to accommodate all possible scenarios under which such norms should be applied, thus making the role of pragmatics an important aspect also in the representation of a legal norm and reasoning on top of it. The notion of pragmatics considered in this paper does not focus on the aspects associated with judicial decision making. The paper aims to shed light on the aspects of pragmatics in legal linguistics, mainly focusing on the domain of patent law, only from a knowledge representation perspective. The philosophical discussions presented in this paper are grounded based on the legal theories from Grice and Marmor.
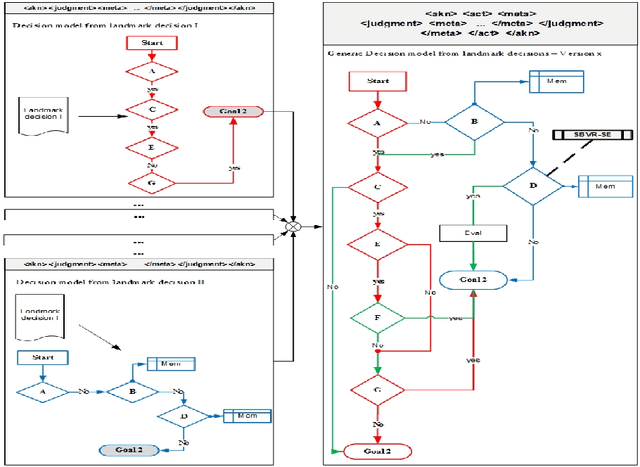
Rule reasoning for legal norm validation of FSTP facts
Dec 05, 2014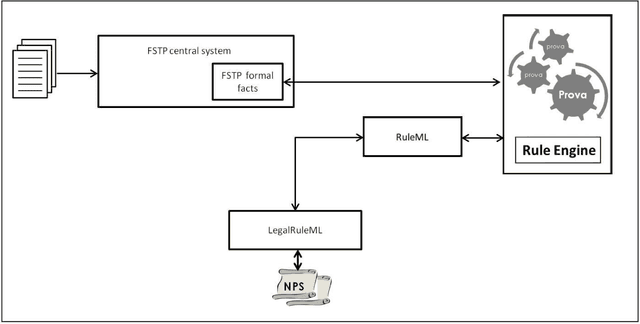
Non-obviousness or inventive step is a general requirement for patentability in most patent law systems. An invention should be at an adequate distance beyond its prior art in order to be patented. This short paper provides an overview on a methodology proposed for legal norm validation of FSTP facts using rule reasoning approach.
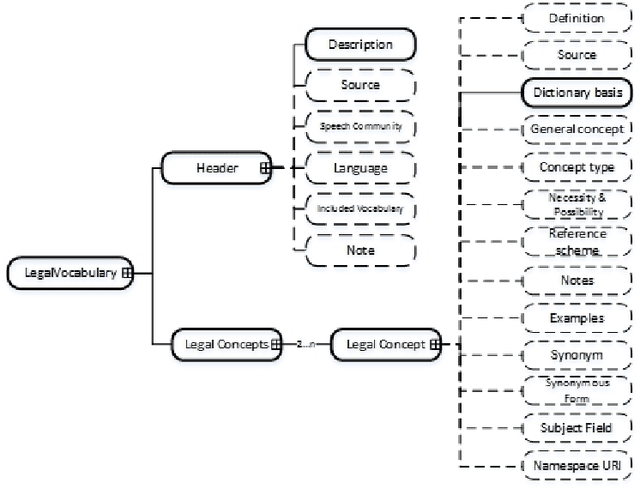
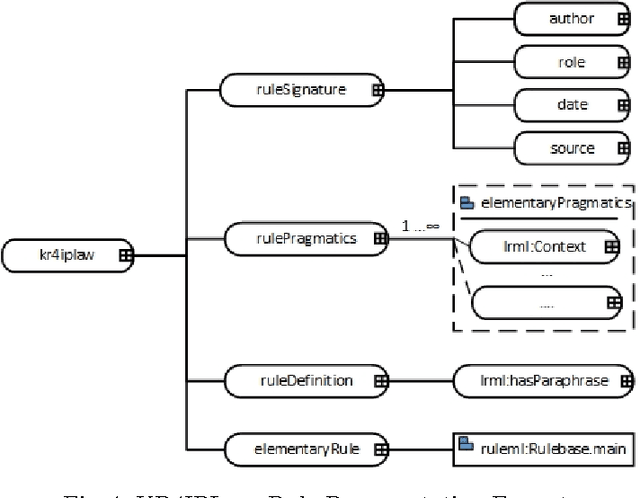
Bridging the gap between Legal Practitioners and Knowledge Engineers using semi-formal KR
May 31, 2014
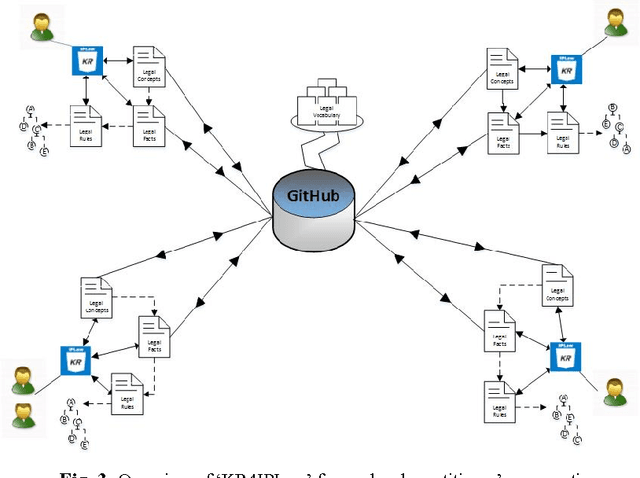

The use of Structured English as a computation independent knowledge representation format for non-technical users in business rules representation has been proposed in OMGs Semantics and Business Vocabulary Representation (SBVR). In the legal domain we face a similar problem. Formal representation languages, such as OASIS LegalRuleML and legal ontologies (LKIF, legal OWL2 ontologies etc.) support the technical knowledge engineer and the automated reasoning. But, they can be hardly used directly by the legal domain experts who do not have a computer science background. In this paper we adapt the SBVR Structured English approach for the legal domain and implement a proof-of-concept, called KR4IPLaw, which enables legal domain experts to represent their knowledge in Structured English in a computational independent and hence, for them, more usable way. The benefit of this approach is that the underlying pre-defined semantics of the Structured English approach makes transformations into formal languages such as OASIS LegalRuleML and OWL2 ontologies possible. We exemplify our approach in the domain of patent law.