 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplicability is Asymptotically Free in Multi-armed Bandits
Feb 12, 2024
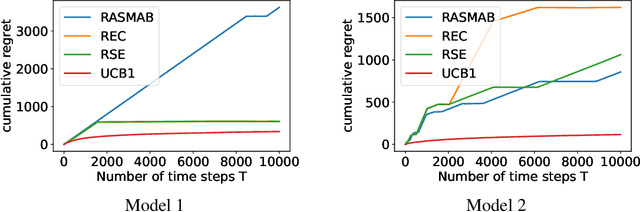
This work is motivated by the growing demand for reproducible machine learning. We study the stochastic multi-armed bandit problem. In particular, we consider a replicable algorithm that ensures, with high probability, that the algorithm's sequence of actions is not affected by the randomness inherent in the dataset. We observe that existing algorithms require $O(1/\rho^2)$ times more regret than nonreplicable algorithms, where $\rho$ is the level of nonreplication. However, we demonstrate that this additional cost is unnecessary when the time horizon $T$ is sufficiently large for a given $\rho$, provided that the magnitude of the confidence bounds is chosen carefully. We introduce an explore-then-commit algorithm that draws arms uniformly before committing to a single arm. Additionally, we examine a successive elimination algorithm that eliminates suboptimal arms at the end of each phase. To ensure the replicability of these algorithms, we incorporate randomness into their decision-making processes. We extend the use of successive elimination to the linear bandit problem as well. For the analysis of these algorithms, we propose a principled approach to limiting the probability of nonreplication. This approach elucidates the steps that existing research has implicitly followed. Furthermore, we derive the first lower bound for the two-armed replicable bandit problem, which implies the optimality of the proposed algorithms up to a $\log\log T$ factor for the two-armed case.