 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf Training with Ensemble of Teacher Models
Jul 17, 2021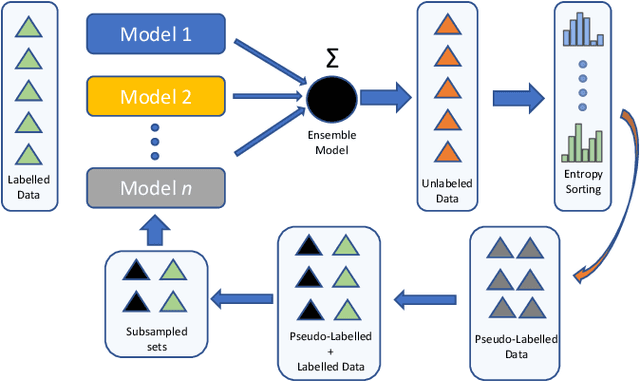
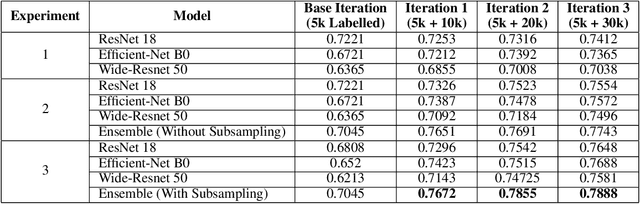
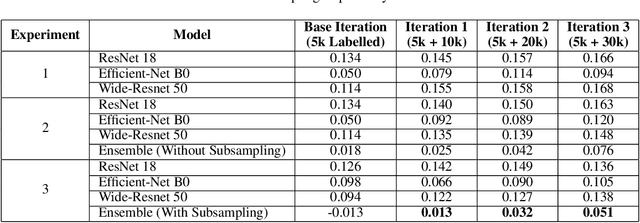
In order to train robust deep learning models, large amounts of labelled data is required. However, in the absence of such large repositories of labelled data, unlabeled data can be exploited for the same. Semi-Supervised learning aims to utilize such unlabeled data for training classification models. Recent progress of self-training based approaches have shown promise in this area, which leads to this study where we utilize an ensemble approach for the same. A by-product of any semi-supervised approach may be loss of calibration of the trained model especially in scenarios where unlabeled data may contain out-of-distribution samples, which leads to this investigation on how to adapt to such effects. Our proposed algorithm carefully avoids common pitfalls in utilizing unlabeled data and leads to a more accurate and calibrated supervised model compared to vanilla self-training based student-teacher algorithms. We perform several experiments on the popular STL-10 database followed by an extensive analysis of our approach and study its effects on model accuracy and calibration.
Unravelling Small Sample Size Problems in the Deep Learning World
Aug 08, 2020
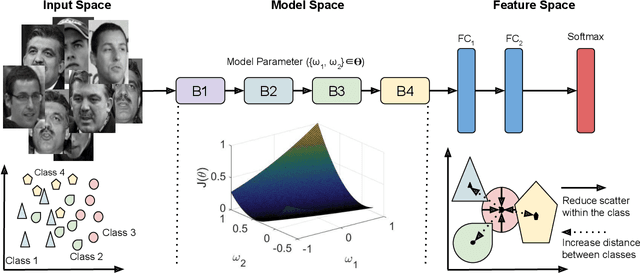
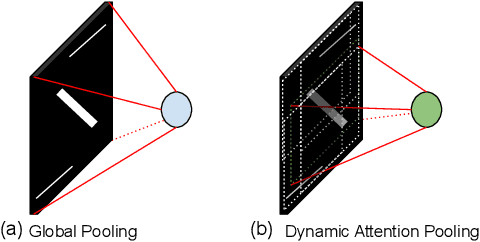
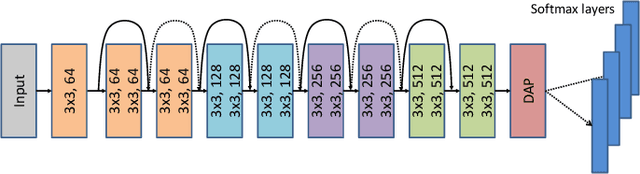
The growth and success of deep learning approaches can be attributed to two major factors: availability of hardware resources and availability of large number of training samples. For problems with large training databases, deep learning models have achieved superlative performances. However, there are a lot of \textit{small sample size or $S^3$} problems for which it is not feasible to collect large training databases. It has been observed that deep learning models do not generalize well on $S^3$ problems and specialized solutions are required. In this paper, we first present a review of deep learning algorithms for small sample size problems in which the algorithms are segregated according to the space in which they operate, i.e. input space, model space, and feature space. Secondly, we present Dynamic Attention Pooling approach which focuses on extracting global information from the most discriminative sub-part of the feature map. The performance of the proposed dynamic attention pooling is analyzed with state-of-the-art ResNet model on relatively small publicly available datasets such as SVHN, C10, C100, and TinyImageNet.
On Learning Density Aware Embeddings
Apr 08, 2019
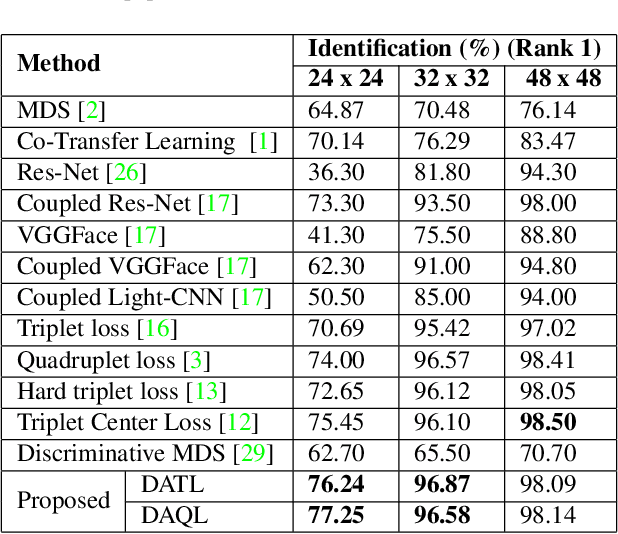


Deep metric learning algorithms have been utilized to learn discriminative and generalizable models which are effective for classifying unseen classes. In this paper, a novel noise tolerant deep metric learning algorithm is proposed. The proposed method, termed as Density Aware Metric Learning, enforces the model to learn embeddings that are pulled towards the most dense region of the clusters for each class. It is achieved by iteratively shifting the estimate of the center towards the dense region of the cluster thereby leading to faster convergence and higher generalizability. In addition to this, the approach is robust to noisy samples in the training data, often present as outliers. Detailed experiments and analysis on two challenging cross-modal face recognition databases and two popular object recognition databases exhibit the efficacy of the proposed approach. It has superior convergence, requires lesser training time, and yields better accuracies than several popular deep metric learning methods.
Heterogeneity Aware Deep Embedding for Mobile Periocular Recognition
Nov 02, 2018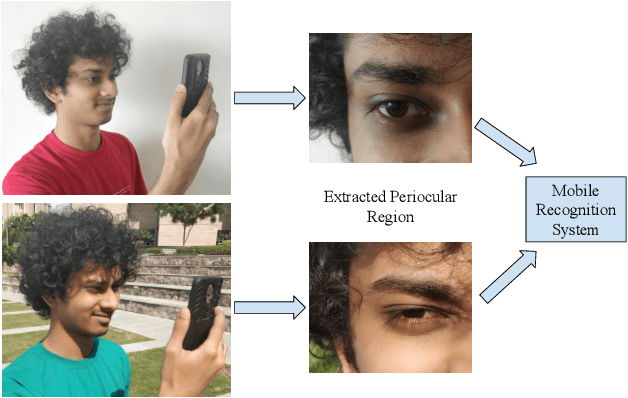
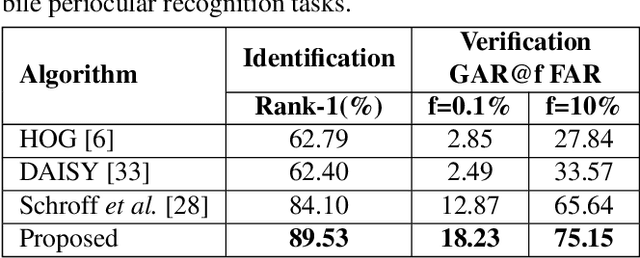
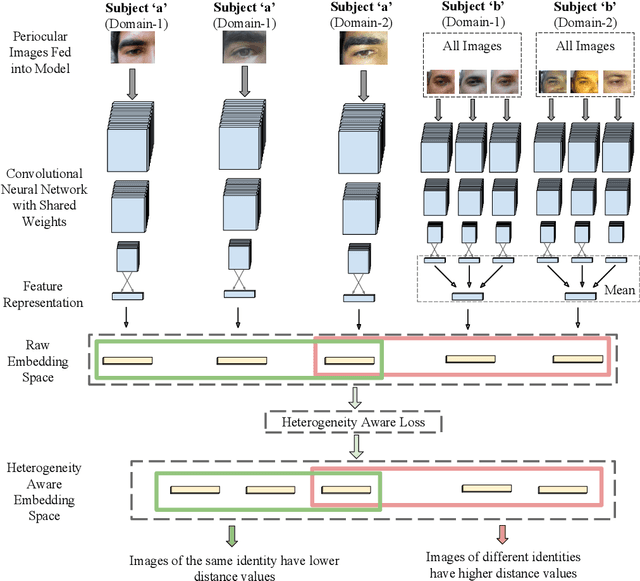
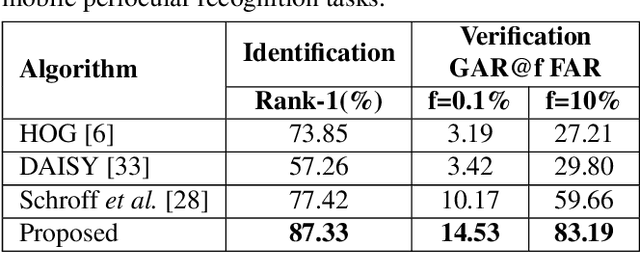
Mobile biometric approaches provide the convenience of secure authentication with an omnipresent technology. However, this brings an additional challenge of recognizing biometric patterns in unconstrained environment including variations in mobile camera sensors, illumination conditions, and capture distance. To address the heterogeneous challenge, this research presents a novel heterogeneity aware loss function within a deep learning framework. The effectiveness of the proposed loss function is evaluated for periocular biometrics using the CSIP, IMP and VISOB mobile periocular databases. The results show that the proposed algorithm yields state-of-the-art results in a heterogeneous environment and improves generalizability for cross-database experiments.