 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Analysis of Neural QA models on SQuAD
Jun 18, 2018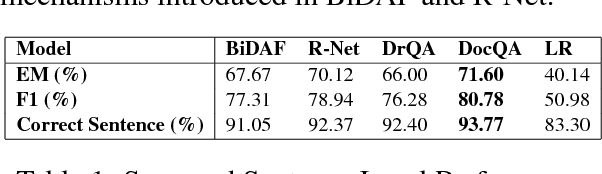
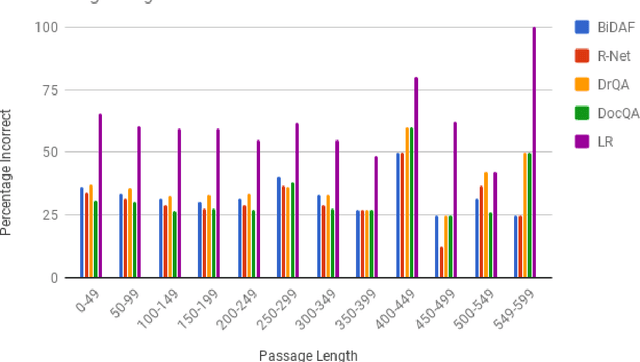
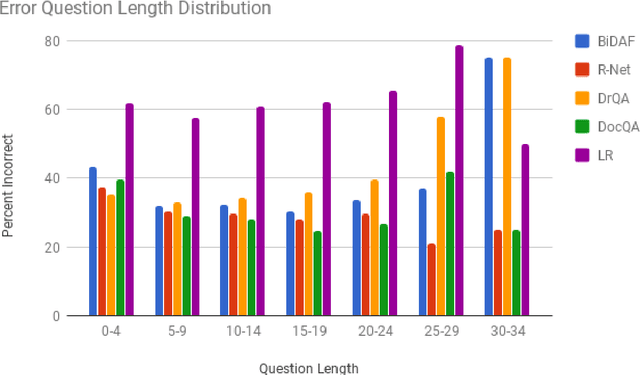
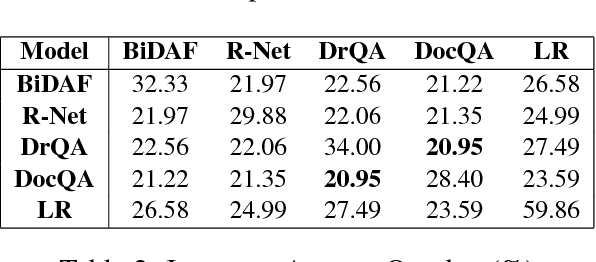
The task of Question Answering has gained prominence in the past few decades for testing the ability of machines to understand natural language. Large datasets for Machine Reading have led to the development of neural models that cater to deeper language understanding compared to information retrieval tasks. Different components in these neural architectures are intended to tackle different challenges. As a first step towards achieving generalization across multiple domains, we attempt to understand and compare the peculiarities of existing end-to-end neural models on the Stanford Question Answering Dataset (SQuAD) by performing quantitative as well as qualitative analysis of the results attained by each of them. We observed that prediction errors reflect certain model-specific biases, which we further discuss in this paper.
Towards Inference-Oriented Reading Comprehension: ParallelQA
May 10, 2018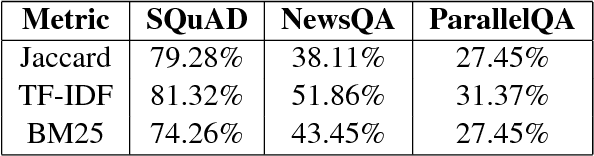

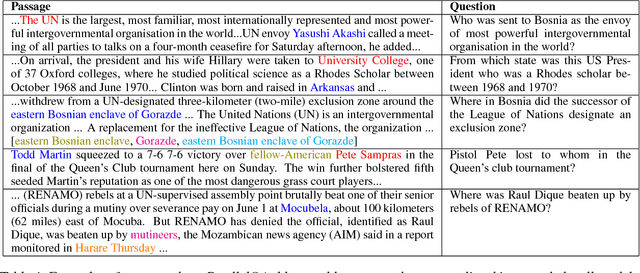

In this paper, we investigate the tendency of end-to-end neural Machine Reading Comprehension (MRC) models to match shallow patterns rather than perform inference-oriented reasoning on RC benchmarks. We aim to test the ability of these systems to answer questions which focus on referential inference. We propose ParallelQA, a strategy to formulate such questions using parallel passages. We also demonstrate that existing neural models fail to generalize well to this setting.