 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical Image Retrieval via Nearest Neighbor Search on Pre-trained Image Features
Oct 05, 2022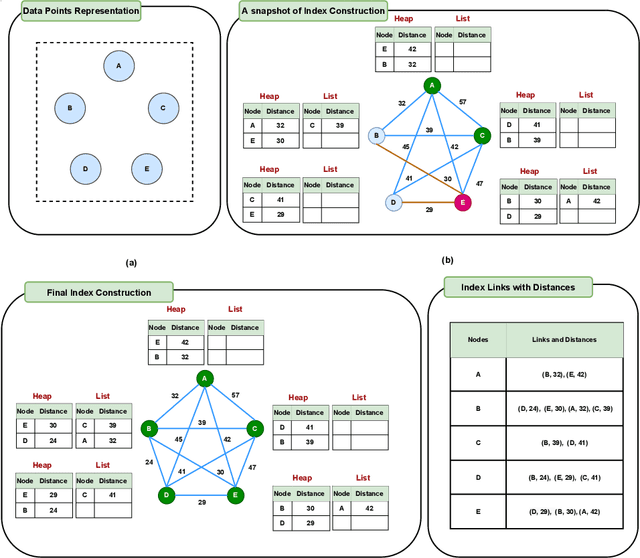

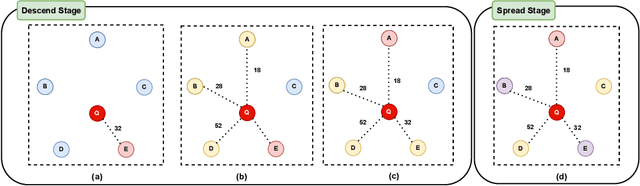
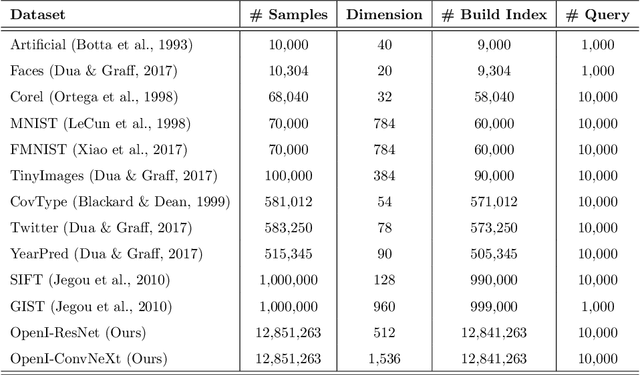
Nearest neighbor search (NNS) aims to locate the points in high-dimensional space that is closest to the query point. The brute-force approach for finding the nearest neighbor becomes computationally infeasible when the number of points is large. The NNS has multiple applications in medicine, such as searching large medical imaging databases, disease classification, diagnosis, etc. With a focus on medical imaging, this paper proposes DenseLinkSearch an effective and efficient algorithm that searches and retrieves the relevant images from heterogeneous sources of medical images. Towards this, given a medical database, the proposed algorithm builds the index that consists of pre-computed links of each point in the database. The search algorithm utilizes the index to efficiently traverse the database in search of the nearest neighbor. We extensively tested the proposed NNS approach and compared the performance with state-of-the-art NNS approaches on benchmark datasets and our created medical image datasets. The proposed approach outperformed the existing approach in terms of retrieving accurate neighbors and retrieval speed. We also explore the role of medical image feature representation in content-based medical image retrieval tasks. We propose a Transformer-based feature representation technique that outperformed the existing pre-trained Transformer approach on CLEF 2011 medical image retrieval task. The source code of our experiments are available at https://github.com/deepaknlp/DLS.
Question-Driven Summarization of Answers to Consumer Health Questions
May 20, 2020
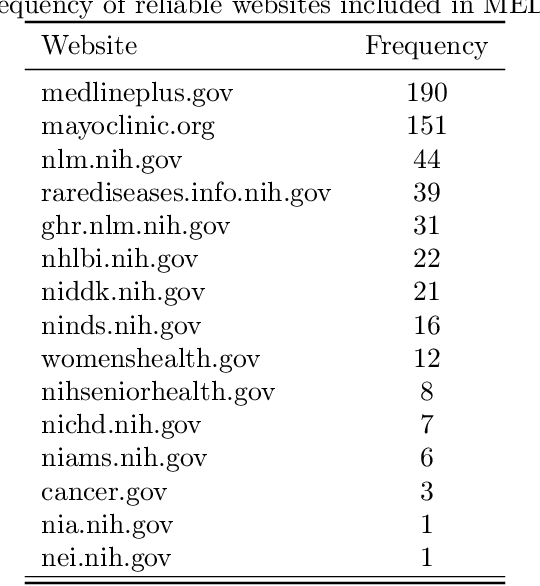
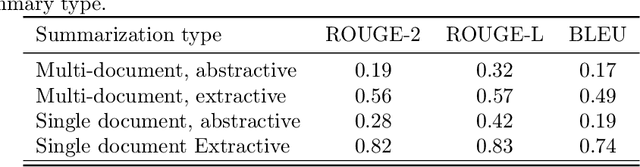
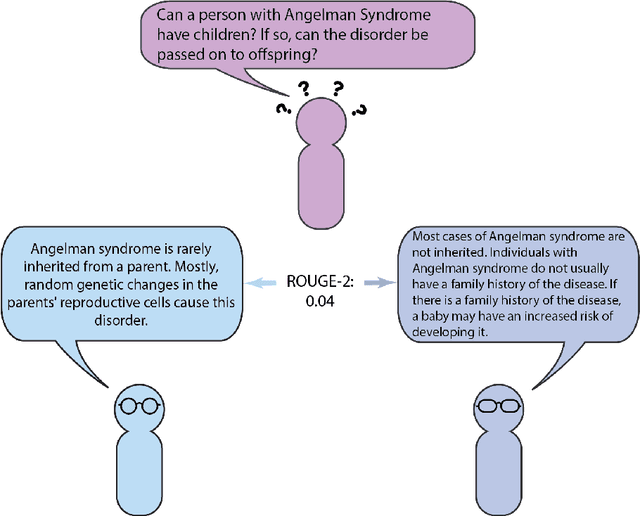
Automatic summarization of natural language is a widely studied area in computer science, one that is broadly applicable to anyone who routinely needs to understand large quantities of information. For example, in the medical domain, recent developments in deep learning approaches to automatic summarization have the potential to make health information more easily accessible to patients and consumers. However, to evaluate the quality of automatically generated summaries of health information, gold-standard, human generated summaries are required. Using answers provided by the National Library of Medicine's consumer health question answering system, we present the MEDIQA Answer Summarization dataset, the first summarization collection containing question-driven summaries of answers to consumer health questions. This dataset can be used to evaluate single or multi-document summaries generated by algorithms using extractive or abstractive approaches. In order to benchmark the dataset, we include results of baseline and state-of-the-art deep learning summarization models, demonstrating that this dataset can be used to effectively evaluate question-driven machine-generated summaries and promote further machine learning research in medical question answering.