 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion-Driven Summarization of Answers to Consumer Health Questions
Paper and Code
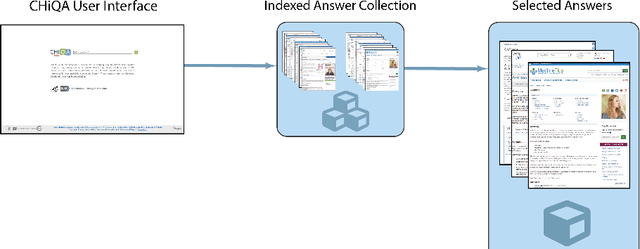
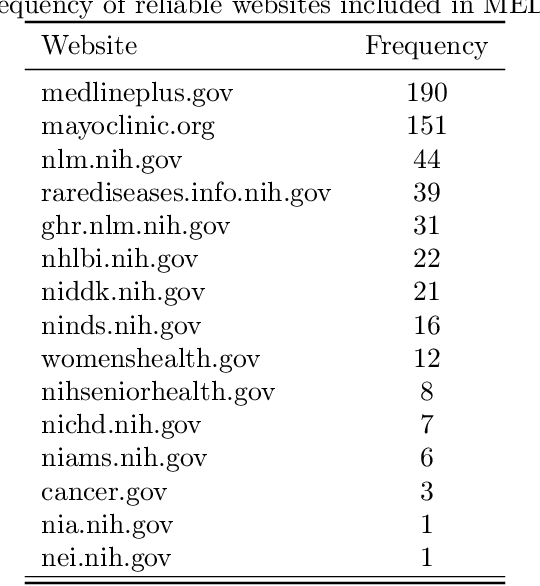
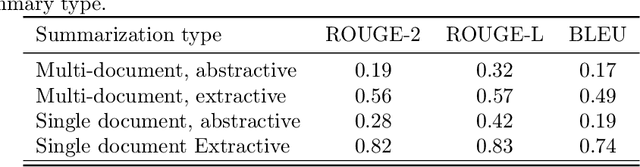
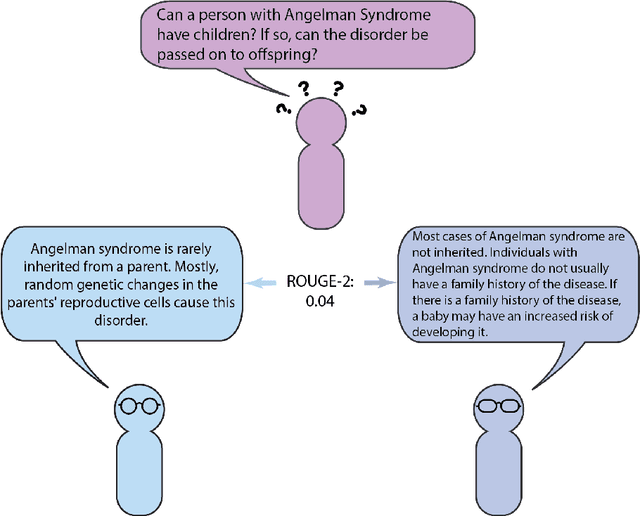
Automatic summarization of natural language is a widely studied area in computer science, one that is broadly applicable to anyone who routinely needs to understand large quantities of information. For example, in the medical domain, recent developments in deep learning approaches to automatic summarization have the potential to make health information more easily accessible to patients and consumers. However, to evaluate the quality of automatically generated summaries of health information, gold-standard, human generated summaries are required. Using answers provided by the National Library of Medicine's consumer health question answering system, we present the MEDIQA Answer Summarization dataset, the first summarization collection containing question-driven summaries of answers to consumer health questions. This dataset can be used to evaluate single or multi-document summaries generated by algorithms using extractive or abstractive approaches. In order to benchmark the dataset, we include results of baseline and state-of-the-art deep learning summarization models, demonstrating that this dataset can be used to effectively evaluate question-driven machine-generated summaries and promote further machine learning research in medical question answering.