 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePR-IQA: Partial-Reference Image Quality Assessment for Diffusion-Based Novel View Synthesis
Apr 07, 2026Diffusion models are promising for sparse-view novel view synthesis (NVS), as they can generate pseudo-ground-truth views to aid 3D reconstruction pipelines like 3D Gaussian Splatting (3DGS). However, these synthesized images often contain photometric and geometric inconsistencies, and their direct use for supervision can impair reconstruction. To address this, we propose Partial-Reference Image Quality Assessment (PR-IQA), a framework that evaluates diffusion-generated views using reference images from different poses, eliminating the need for ground truth. PR-IQA first computes a geometrically consistent partial quality map in overlapping regions. It then performs quality completion to inpaint this partial map into a dense, full-image map. This completion is achieved via a cross-attention mechanism that incorporates reference-view context, ensuring cross-view consistency and enabling thorough quality assessment. When integrated into a diffusion-augmented 3DGS pipeline, PR-IQA restricts supervision to high-confidence regions identified by its quality maps. Experiments demonstrate that PR-IQA outperforms existing IQA methods, achieving full-reference-level accuracy without ground-truth supervision. Thus, our quality-aware 3DGS approach more effectively filters inconsistencies, producing superior 3D reconstructions and NVS results. The project page is available at https://kakaomacao.github.io/pr-iqa-project-page/.
MVS-GS: High-Quality 3D Gaussian Splatting Mapping via Online Multi-View Stereo
Dec 26, 2024
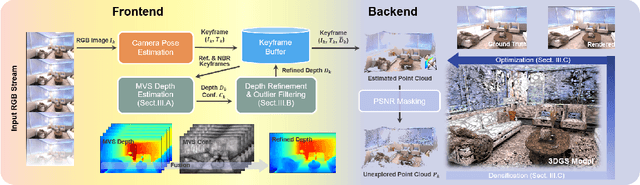
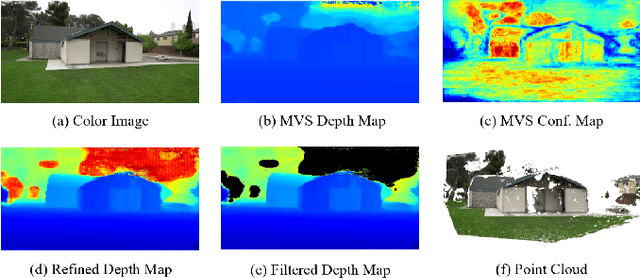

This study addresses the challenge of online 3D model generation for neural rendering using an RGB image stream. Previous research has tackled this issue by incorporating Neural Radiance Fields (NeRF) or 3D Gaussian Splatting (3DGS) as scene representations within dense SLAM methods. However, most studies focus primarily on estimating coarse 3D scenes rather than achieving detailed reconstructions. Moreover, depth estimation based solely on images is often ambiguous, resulting in low-quality 3D models that lead to inaccurate renderings. To overcome these limitations, we propose a novel framework for high-quality 3DGS modeling that leverages an online multi-view stereo (MVS) approach. Our method estimates MVS depth using sequential frames from a local time window and applies comprehensive depth refinement techniques to filter out outliers, enabling accurate initialization of Gaussians in 3DGS. Furthermore, we introduce a parallelized backend module that optimizes the 3DGS model efficiently, ensuring timely updates with each new keyframe. Experimental results demonstrate that our method outperforms state-of-the-art dense SLAM methods, particularly excelling in challenging outdoor environments.
Learning to Produce Semi-dense Correspondences for Visual Localization
Feb 13, 2024



This study addresses the challenge of performing visual localization in demanding conditions such as night-time scenarios, adverse weather, and seasonal changes. While many prior studies have focused on improving image-matching performance to facilitate reliable dense keypoint matching between images, existing methods often heavily rely on predefined feature points on a reconstructed 3D model. Consequently, they tend to overlook unobserved keypoints during the matching process. Therefore, dense keypoint matches are not fully exploited, leading to a notable reduction in accuracy, particularly in noisy scenes. To tackle this issue, we propose a novel localization method that extracts reliable semi-dense 2D-3D matching points based on dense keypoint matches. This approach involves regressing semi-dense 2D keypoints into 3D scene coordinates using a point inference network. The network utilizes both geometric and visual cues to effectively infer 3D coordinates for unobserved keypoints from the observed ones. The abundance of matching information significantly enhances the accuracy of camera pose estimation, even in scenarios involving noisy or sparse 3D models. Comprehensive evaluations demonstrate that the proposed method outperforms other methods in challenging scenes and achieves competitive results in large-scale visual localization benchmarks. The code will be available.
TopicFM+: Boosting Accuracy and Efficiency of Topic-Assisted Feature Matching
Jul 02, 2023This study tackles the challenge of image matching in difficult scenarios, such as scenes with significant variations or limited texture, with a strong emphasis on computational efficiency. Previous studies have attempted to address this challenge by encoding global scene contexts using Transformers. However, these approaches suffer from high computational costs and may not capture sufficient high-level contextual information, such as structural shapes or semantic instances. Consequently, the encoded features may lack discriminative power in challenging scenes. To overcome these limitations, we propose a novel image-matching method that leverages a topic-modeling strategy to capture high-level contexts in images. Our method represents each image as a multinomial distribution over topics, where each topic represents a latent semantic instance. By incorporating these topics, we can effectively capture comprehensive context information and obtain discriminative and high-quality features. Additionally, our method effectively matches features within corresponding semantic regions by estimating the covisible topics. To enhance the efficiency of feature matching, we have designed a network with a pooling-and-merging attention module. This module reduces computation by employing attention only on fixed-sized topics and small-sized features. Through extensive experiments, we have demonstrated the superiority of our method in challenging scenarios. Specifically, our method significantly reduces computational costs while maintaining higher image-matching accuracy compared to state-of-the-art methods. The code will be updated soon at https://github.com/TruongKhang/TopicFM
TopicFM: Robust and Interpretable Feature Matching with Topic-assisted
Jul 01, 2022
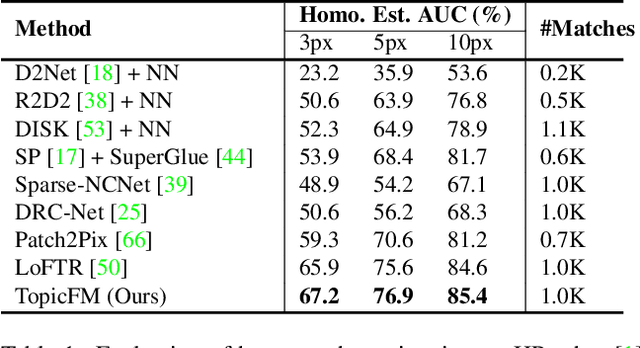
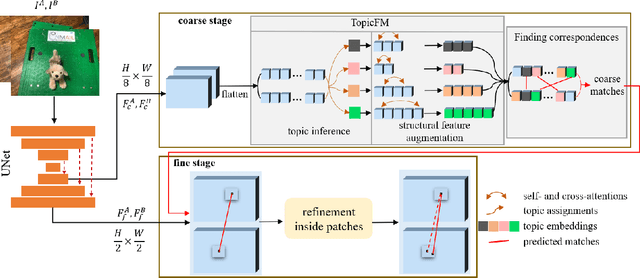
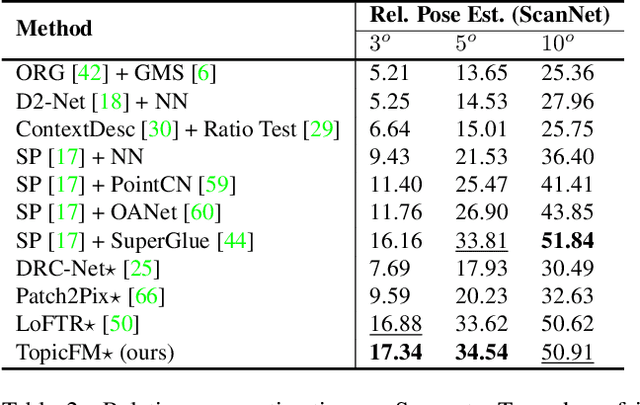
Finding correspondences across images is an important task in many visual applications. Recent state-of-the-art methods focus on end-to-end learning-based architectures designed in a coarse-to-fine manner. They use a very deep CNN or multi-block Transformer to learn robust representation, which requires high computation power. Moreover, these methods learn features without reasoning about objects, shapes inside images, thus lacks of interpretability. In this paper, we propose an architecture for image matching which is efficient, robust, and interpretable. More specifically, we introduce a novel feature matching module called TopicFM which can roughly organize same spatial structure across images into a topic and then augment the features inside each topic for accurate matching. To infer topics, we first learn global embedding of topics and then use a latent-variable model to detect-then-assign the image structures into topics. Our method can only perform matching in co-visibility regions to reduce computations. Extensive experiments in both outdoor and indoor datasets show that our method outperforms the recent methods in terms of matching performance and computational efficiency. The code is available at https://github.com/TruongKhang/TopicFM.
A Review on Viewpoints and Path-planning for UAV-based 3D Reconstruction
May 07, 2022
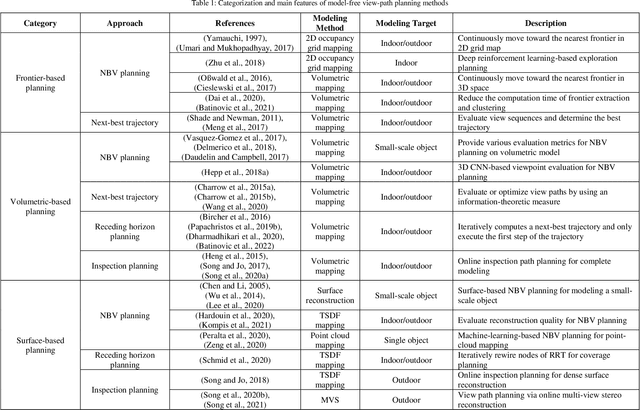
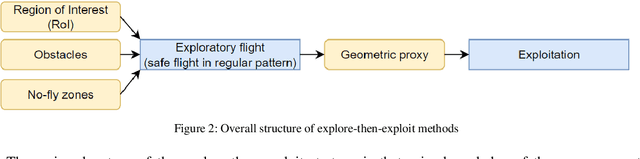
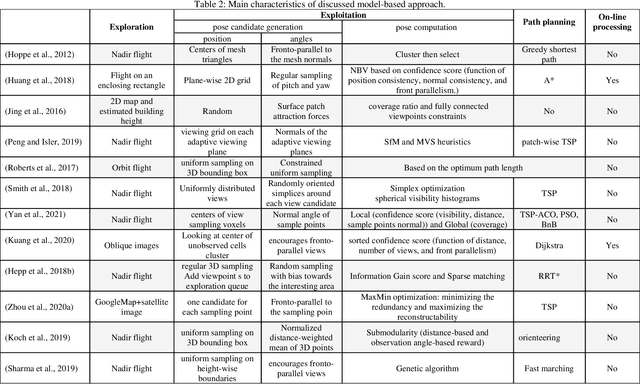
Unmanned aerial vehicles (UAVs) are widely used platforms to carry data capturing sensors for various applications. The reason for this success can be found in many aspects: the high maneuverability of the UAVs, the capability of performing autonomous data acquisition, flying at different heights, and the possibility to reach almost any vantage point. The selection of appropriate viewpoints and planning the optimum trajectories of UAVs is an emerging topic that aims at increasing the automation, efficiency and reliability of the data capturing process to achieve a dataset with desired quality. On the other hand, 3D reconstruction using the data captured by UAVs is also attracting attention in research and industry. This review paper investigates a wide range of model-free and model-based algorithms for viewpoint and path planning for 3D reconstruction of large-scale objects. The analyzed approaches are limited to those that employ a single-UAV as a data capturing platform for outdoor 3D reconstruction purposes. In addition to discussing the evaluation strategies, this paper also highlights the innovations and limitations of the investigated approaches. It concludes with a critical analysis of the existing challenges and future research perspectives.
Curvature-guided dynamic scale networks for Multi-view Stereo
Dec 11, 2021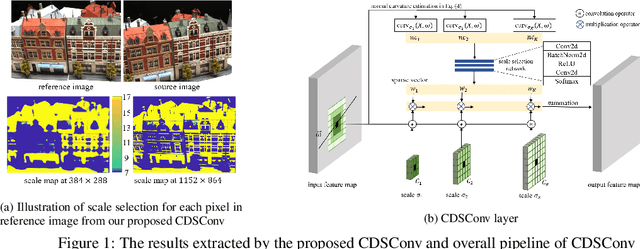
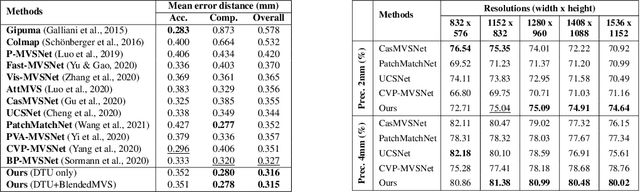
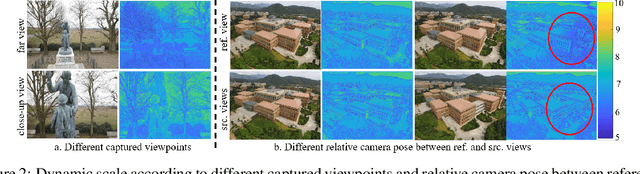
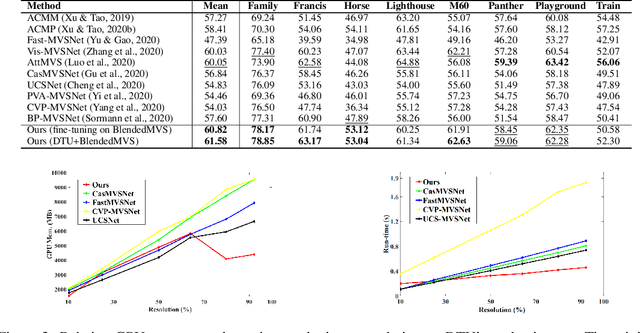
Multi-view stereo (MVS) is a crucial task for precise 3D reconstruction. Most recent studies tried to improve the performance of matching cost volume in MVS by designing aggregated 3D cost volumes and their regularization. This paper focuses on learning a robust feature extraction network to enhance the performance of matching costs without heavy computation in the other steps. In particular, we present a dynamic scale feature extraction network, namely, CDSFNet. It is composed of multiple novel convolution layers, each of which can select a proper patch scale for each pixel guided by the normal curvature of the image surface. As a result, CDFSNet can estimate the optimal patch scales to learn discriminative features for accurate matching computation between reference and source images. By combining the robust extracted features with an appropriate cost formulation strategy, our resulting MVS architecture can estimate depth maps more precisely. Extensive experiments showed that the proposed method outperforms other state-of-the-art methods on complex outdoor scenes. It significantly improves the completeness of reconstructed models. As a result, the method can process higher resolution inputs within faster run-time and lower memory than other MVS methods. Our source code is available at url{https://github.com/TruongKhang/cds-mvsnet}.