 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopicFM: Robust and Interpretable Feature Matching with Topic-assisted
Paper and Code

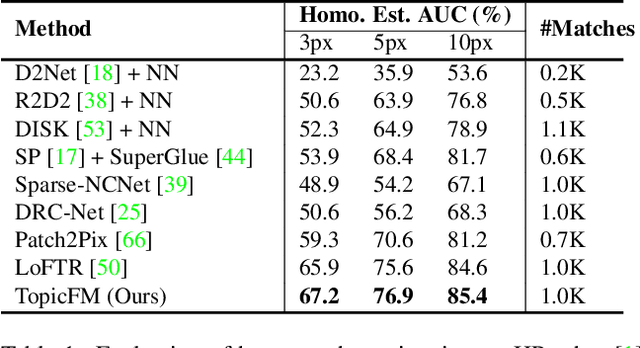
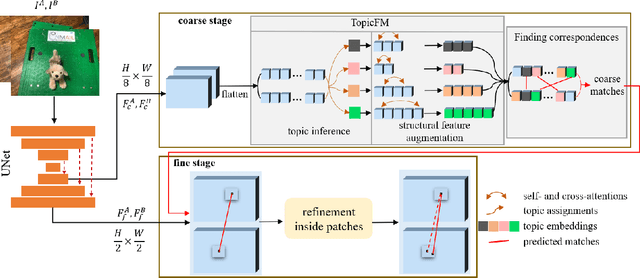
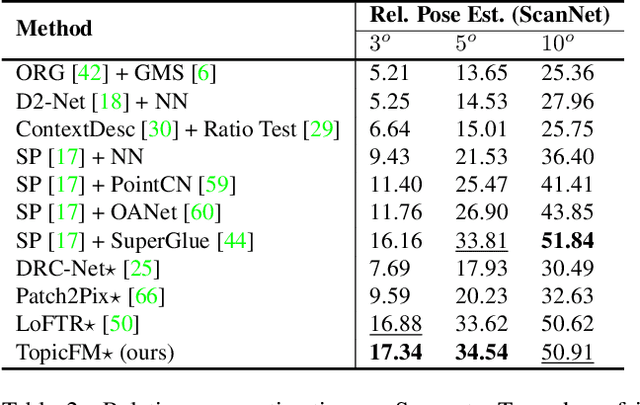
Finding correspondences across images is an important task in many visual applications. Recent state-of-the-art methods focus on end-to-end learning-based architectures designed in a coarse-to-fine manner. They use a very deep CNN or multi-block Transformer to learn robust representation, which requires high computation power. Moreover, these methods learn features without reasoning about objects, shapes inside images, thus lacks of interpretability. In this paper, we propose an architecture for image matching which is efficient, robust, and interpretable. More specifically, we introduce a novel feature matching module called TopicFM which can roughly organize same spatial structure across images into a topic and then augment the features inside each topic for accurate matching. To infer topics, we first learn global embedding of topics and then use a latent-variable model to detect-then-assign the image structures into topics. Our method can only perform matching in co-visibility regions to reduce computations. Extensive experiments in both outdoor and indoor datasets show that our method outperforms the recent methods in terms of matching performance and computational efficiency. The code is available at https://github.com/TruongKhang/TopicFM.