 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry Based Machining Feature Retrieval with Inductive Transfer Learning
Aug 26, 2021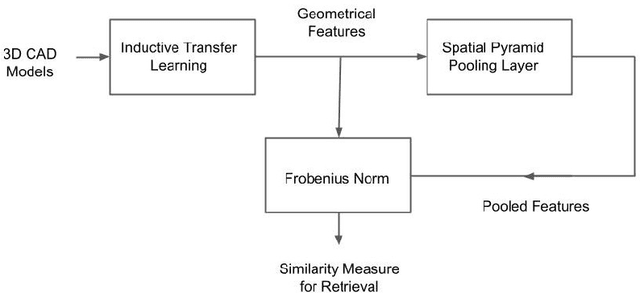

Manufacturing industries have widely adopted the reuse of machine parts as a method to reduce costs and as a sustainable manufacturing practice. Identification of reusable features from the design of the parts and finding their similar features from the database is an important part of this process. In this project, with the help of fully convolutional geometric features, we are able to extract and learn the high level semantic features from CAD models with inductive transfer learning. The extracted features are then compared with that of other CAD models from the database using Frobenius norm and identical features are retrieved. Later we passed the extracted features to a deep convolutional neural network with a spatial pyramid pooling layer and the performance of the feature retrieval increased significantly. It was evident from the results that the model could effectively capture the geometrical elements from machining features.
Deep Learning Approach for Intelligent Named Entity Recognition of Cyber Security
Mar 31, 2020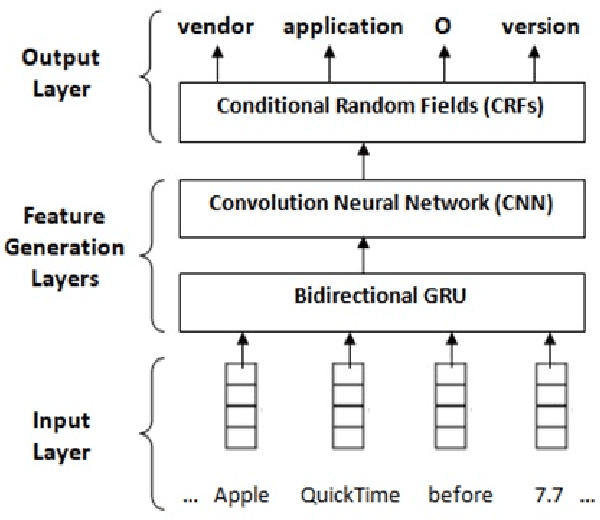
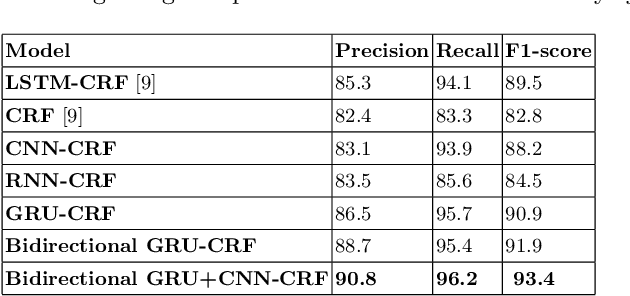
In recent years, the amount of Cyber Security data generated in the form of unstructured texts, for example, social media resources, blogs, articles, and so on has exceptionally increased. Named Entity Recognition (NER) is an initial step towards converting this unstructured data into structured data which can be used by a lot of applications. The existing methods on NER for Cyber Security data are based on rules and linguistic characteristics. A Deep Learning (DL) based approach embedded with Conditional Random Fields (CRFs) is proposed in this paper. Several DL architectures are evaluated to find the most optimal architecture. The combination of Bidirectional Gated Recurrent Unit (Bi-GRU), Convolutional Neural Network (CNN), and CRF performed better compared to various other DL frameworks on a publicly available benchmark dataset. This may be due to the reason that the bidirectional structures preserve the features related to the future and previous words in a sequence.
Deep Learning Approach for Enhanced Cyber Threat Indicators in Twitter Stream
Mar 31, 2020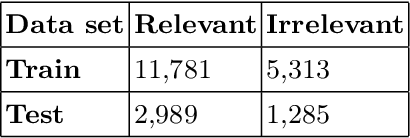
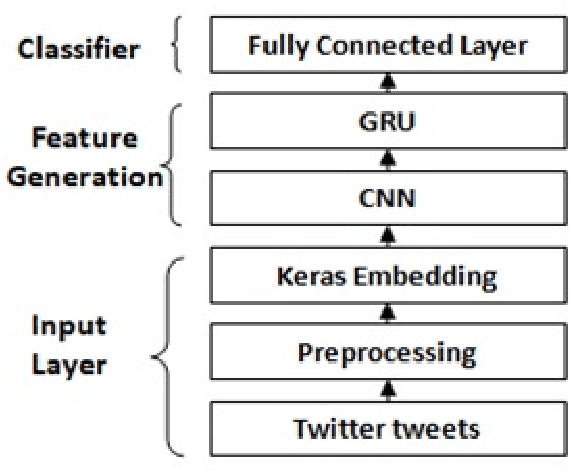
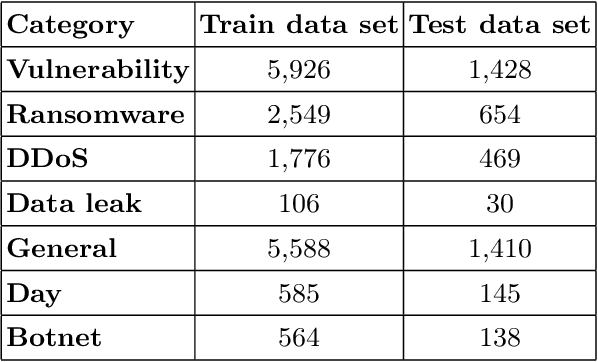
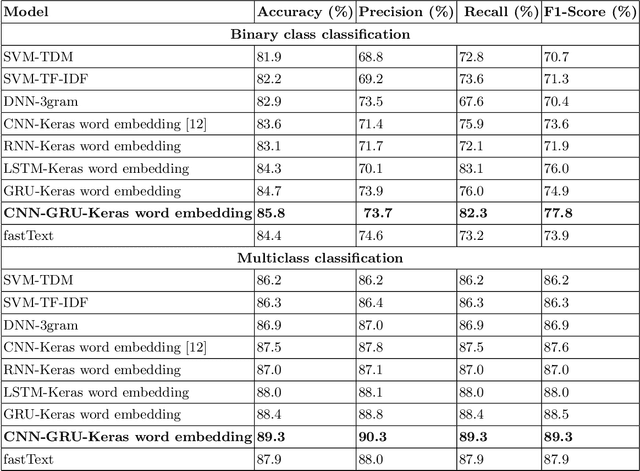
In recent days, the amount of Cyber Security text data shared via social media resources mainly Twitter has increased. An accurate analysis of this data can help to develop cyber threat situational awareness framework for a cyber threat. This work proposes a deep learning based approach for tweet data analysis. To convert the tweets into numerical representations, various text representations are employed. These features are feed into deep learning architecture for optimal feature extraction as well as classification. Various hyperparameter tuning approaches are used for identifying optimal text representation method as well as optimal network parameters and network structures for deep learning models. For comparative analysis, the classical text representation method with classical machine learning algorithm is employed. From the detailed analysis of experiments, we found that the deep learning architecture with advanced text representation methods performed better than the classical text representation and classical machine learning algorithms. The primary reason for this is that the advanced text representation methods have the capability to learn sequential properties which exist among the textual data and deep learning architectures learns the optimal features along with decreasing the feature size.
Deep Learning based Frameworks for Handling Imbalance in DGA, Email, and URL Data Analysis
Mar 31, 2020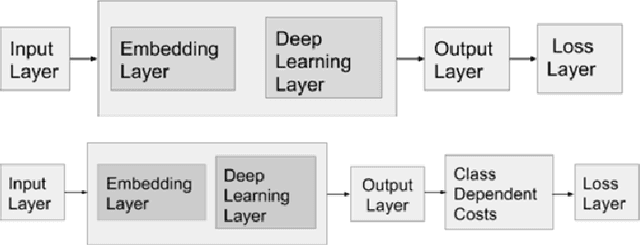
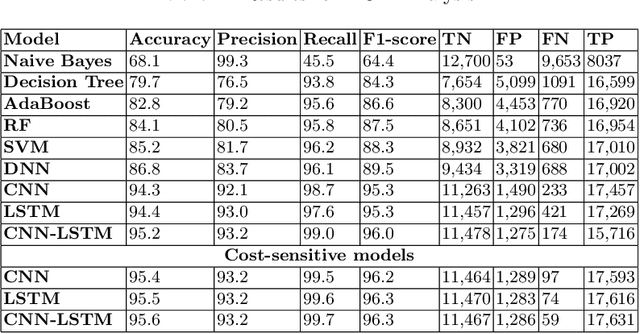
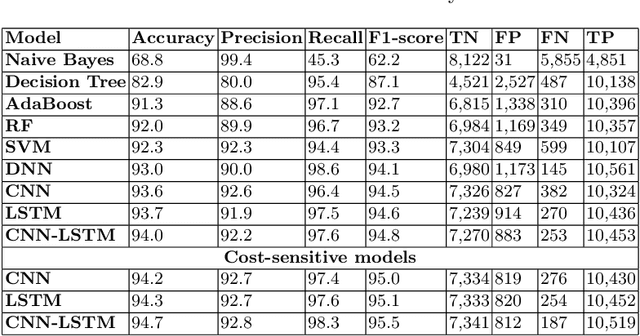
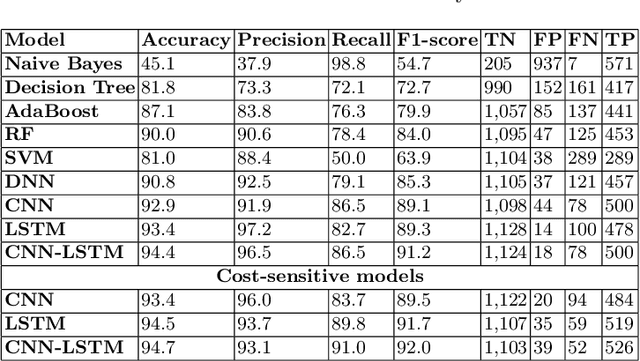
Deep learning is a state of the art method for a lot of applications. The main issue is that most of the real-time data is highly imbalanced in nature. In order to avoid bias in training, cost-sensitive approach can be used. In this paper, we propose cost-sensitive deep learning based frameworks and the performance of the frameworks is evaluated on three different Cyber Security use cases which are Domain Generation Algorithm (DGA), Electronic mail (Email), and Uniform Resource Locator (URL). Various experiments were performed using cost-insensitive as well as cost-sensitive methods and parameters for both of these methods are set based on hyperparameter tuning. In all experiments, the cost-sensitive deep learning methods performed better than the cost-insensitive approaches. This is mainly due to the reason that cost-sensitive approach gives importance to the classes which have a very less number of samples during training and this helps to learn all the classes in a more efficient manner.
Dynamic Mode Decomposition based feature for Image Classification
Oct 08, 2019
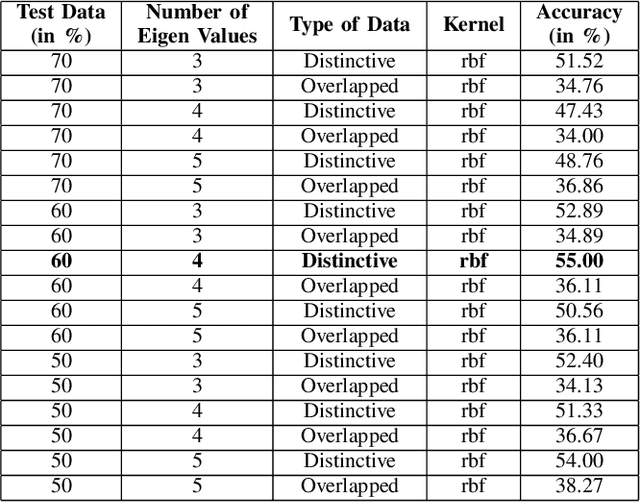
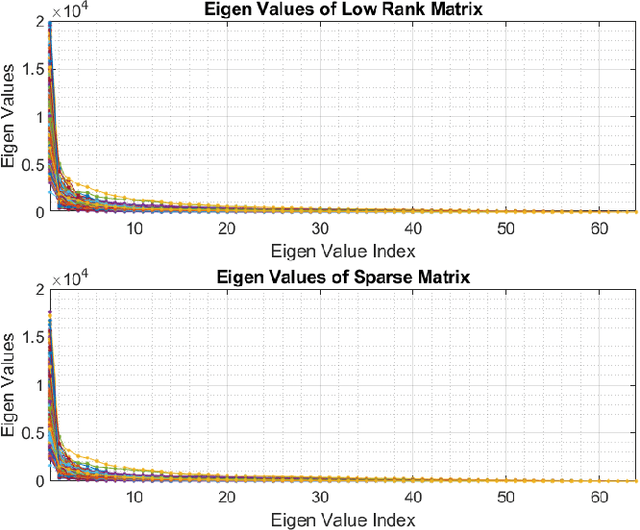
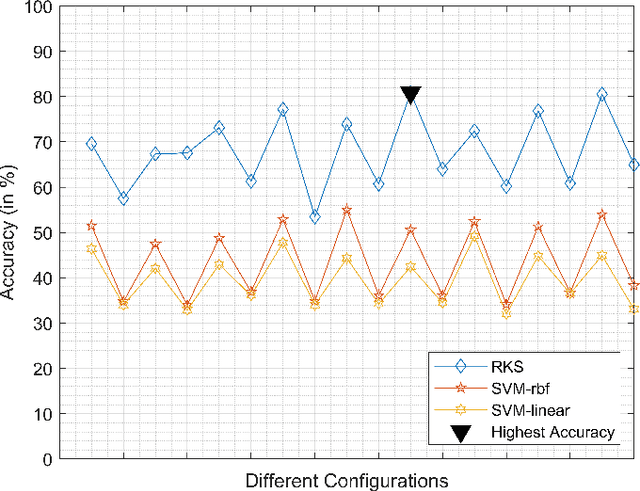
Irrespective of the fact that Machine learning has produced groundbreaking results, it demands an enormous amount of data in order to perform so. Even though data production has been in its all-time high, almost all the data is unlabelled, hence making them unsuitable for training the algorithms. This paper proposes a novel method of extracting the features using Dynamic Mode Decomposition (DMD). The experiment is performed using data samples from Imagenet. The learning is done using SVM-linear, SVM-RBF, Random Kitchen Sink approach (RKS). The results have shown that DMD features with RKS give competing results.
A Compendium on Network and Host based Intrusion Detection Systems
Apr 06, 2019The techniques of deep learning have become the state of the art methodology for executing complicated tasks from various domains of computer vision, natural language processing, and several other areas. Due to its rapid development and promising benchmarks in those fields, researchers started experimenting with this technique to perform in the area of, especially in intrusion detection related tasks. Deep learning is a subset and a natural extension of classical Machine learning and an evolved model of neural networks. This paper contemplates and discusses all the methodologies related to the leading edge Deep learning and Neural network models purposing to the arena of Intrusion Detection Systems.
Emotion Detection using Data Driven Models
Jan 10, 2019

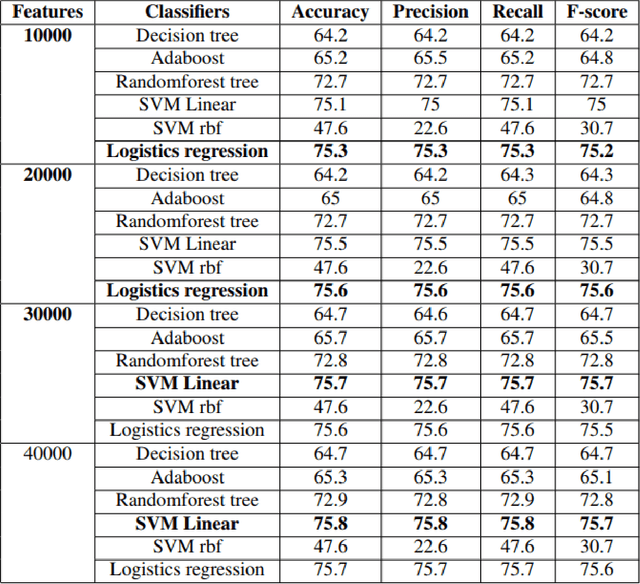
Text is the major method that is used for communication now a days, each and every day lots of text are created. In this paper the text data is used for the classification of the emotions. Emotions are the way of expression of the persons feelings which has an high influence on the decision making tasks. Datasets are collected which are available publically and combined together based on the three emotions that are considered here positive, negative and neutral. In this paper we have proposed the text representation method TFIDF and keras embedding and then given to the classical machine learning algorithms of which Logistics Regression gives the highest accuracy of about 75.6%, after which it is passed to the deep learning algorithm which is the CNN which gives the state of art accuracy of about 45.25%. For the research purpose the datasets that has been collected are released.
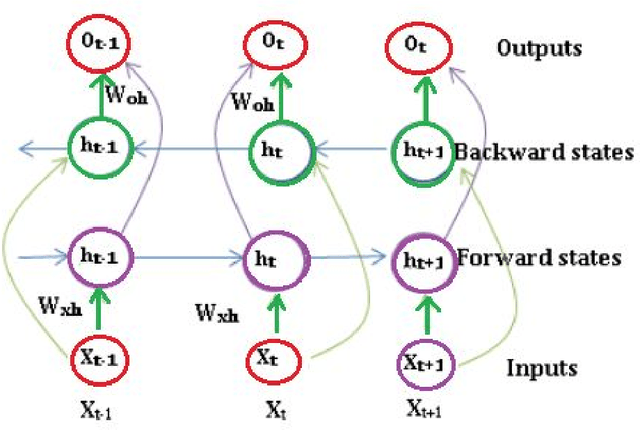
RNNSecureNet: Recurrent neural networks for Cyber security use-cases
Jan 05, 2019
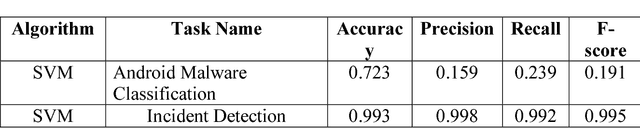

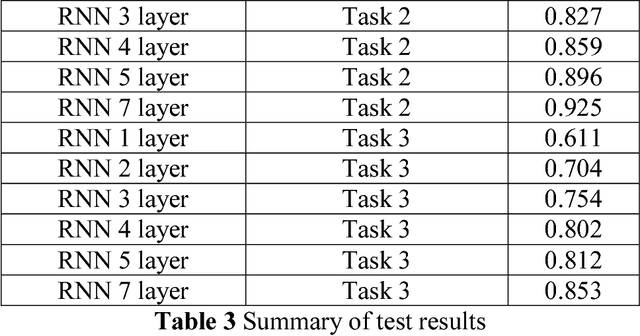
Recurrent neural network (RNN) is an effective neural network in solving very complex supervised and unsupervised tasks. There has been a significant improvement in RNN field such as natural language processing, speech processing, computer vision and other multiple domains. This paper deals with RNN application on different use cases like Incident Detection, Fraud Detection, and Android Malware Classification. The best performing neural network architecture is chosen by conducting different chain of experiments for different network parameters and structures. The network is run up to 1000 epochs with learning rate set in the range of 0.01 to 0.5.Obviously, RNN performed very well when compared to classical machine learning algorithms. This is mainly possible because RNNs implicitly extracts the underlying features and also identifies the characteristics of the data. This helps to achieve better accuracy.
An Insight into the Dynamics and State Space Modelling of a 3-D Quadrotor
Jan 04, 2019
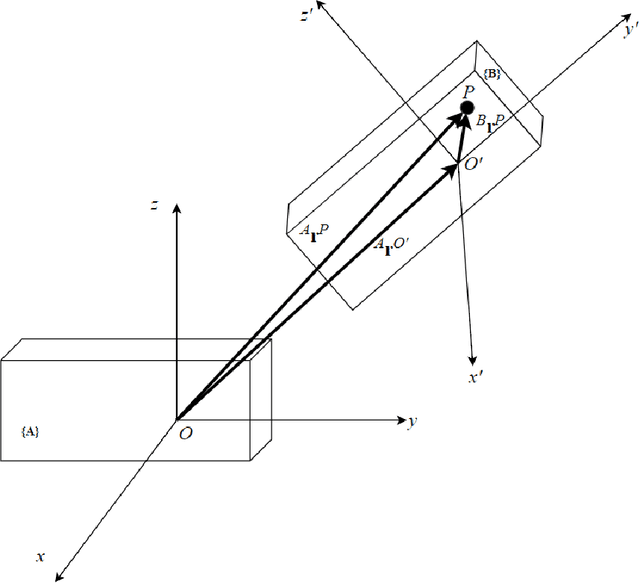
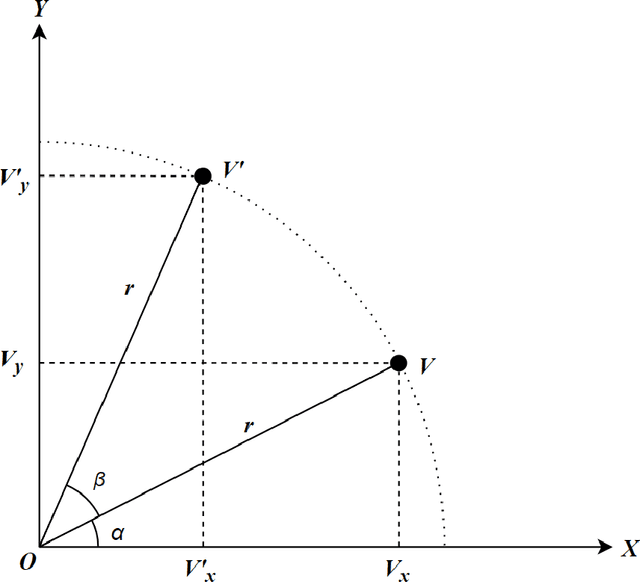
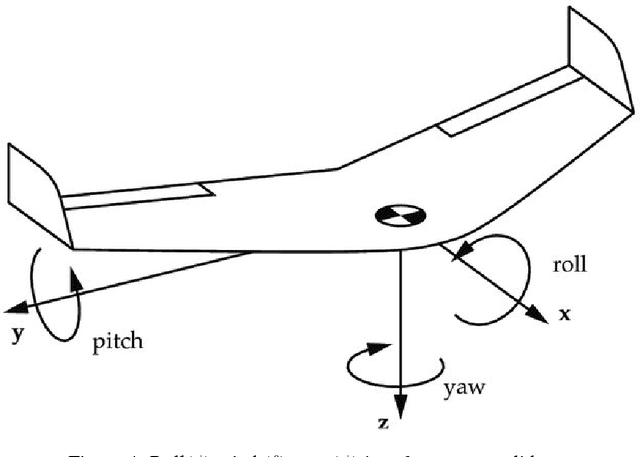
Drones have gained popularity in a wide range of field ranging from aerial photography, aerial mapping, and investigation of electric power lines. Every drone that we know today is carrying out some kind of control algorithm at the low level in order to manoeuvre itself around. For the quadrotor to either control itself autonomously or to develop a high-level user interface for us to control it, we need to understand the basic mathematics behind how it functions. This paper aims to explain the mathematical modelling of the dynamics of a 3 Dimensional quadrotor. As it may seem like a trivial task, it plays a vital role in how we control the drone. Also, additional effort has been taken to explain the transformations of the drone's frame of reference to the inertial frame of reference.
A Deep Learning Approach for Similar Languages, Varieties and Dialects
Jan 02, 2019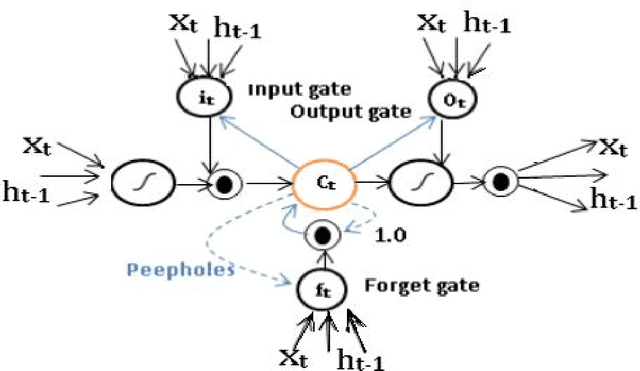
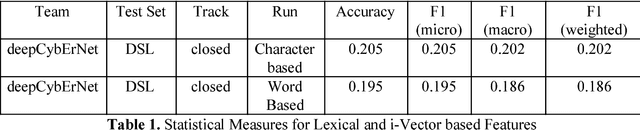
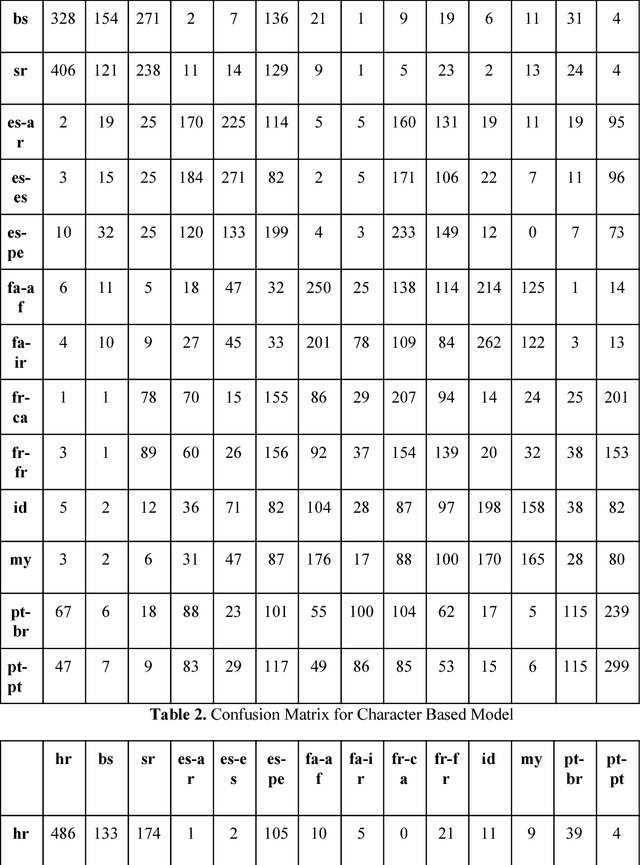
Deep learning mechanisms are prevailing approaches in recent days for the various tasks in natural language processing, speech recognition, image processing and many others. To leverage this we use deep learning based mechanism specifically Bidirectional- Long Short-Term Memory (B-LSTM) for the task of dialectic identification in Arabic and German broadcast speech and Long Short-Term Memory (LSTM) for discriminating between similar Languages. Two unique B-LSTM models are created using the Large-vocabulary Continuous Speech Recognition (LVCSR) based lexical features and a fixed length of 400 per utterance bottleneck features generated by i-vector framework. These models were evaluated on the VarDial 2017 datasets for the tasks Arabic, German dialect identification with dialects of Egyptian, Gulf, Levantine, North African, and MSA for Arabic and Basel, Bern, Lucerne, and Zurich for German. Also for the task of Discriminating between Similar Languages like Bosnian, Croatian and Serbian. The B-LSTM model showed accuracy of 0.246 on lexical features and accuracy of 0.577 bottleneck features of i-Vector framework.