 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning with Multilingual Foundation Model
May 13, 2026This paper presents a multi-stage framework for detecting reclaimed slurs in multilingual social media discourse. It addresses the challenge of identifying reclamatory versus non-reclamatory usage of LGBTQ+-related slurs across English, Spanish, and Italian tweets. The framework handles three intertwined methodological challenges like data scarcity, class imbalance, and cross-linguistic variation in sentiment expression. It integrates data-driven model selection via cross-validation, semantic-preserving augmentation through back-translation, inductive transfer learning with dynamic epoch-level undersampling, and domain-specific knowledge injection via masked language modeling. Eight multilingual embedding models were evaluated systematically, with XLM-RoBERTa selected as the foundation model based on macro-averaged F1 score. Data augmentation via GPT-4o-mini back-translation to alternate languages effectively tripled the training corpus while preserving semantic content and class distribution ratios. The framework produces four final runs for the evaluation purposes where RUN 1 is inductive transfer learning with augmentation and undersampling, RUN 2 with masked language modeling pre-training, RUN 3 and RUN 4 are previous predictions refined via language-specific decision thresholds optimized via ROC analysis. Language-specific threshold refinement reveals that optimal decision boundaries vary significantly across languages. This reflects distributional differences in model confidence scores and linguistic variation in reclamatory language usage. The threshold-based optimization yields 2-5% absolute F1 improvement without requiring model retraining. The methodology is fully reproducible, with all code and experimental setup available at https://github.com/rbg-research/MultiPRIDE-Evalita-2026.
Enhanced Object Detection in Floor-plan through Super Resolution
Dec 18, 2021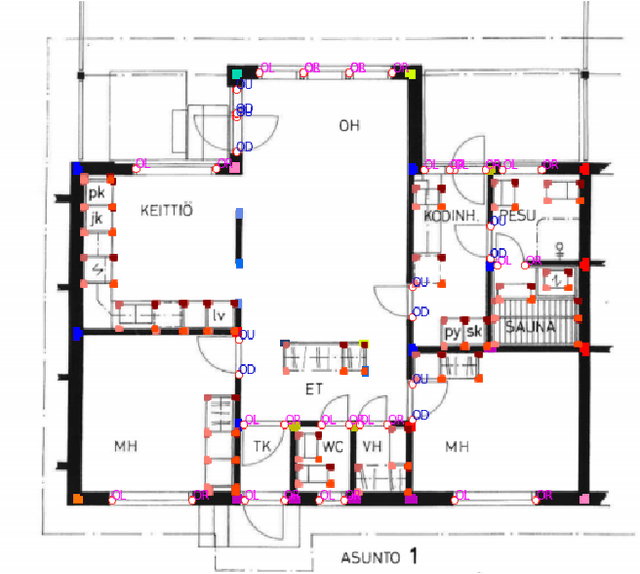
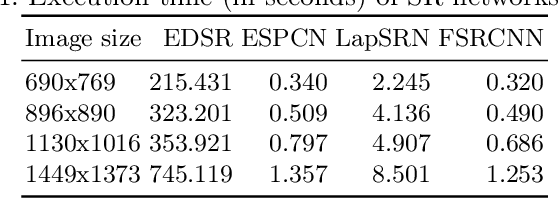

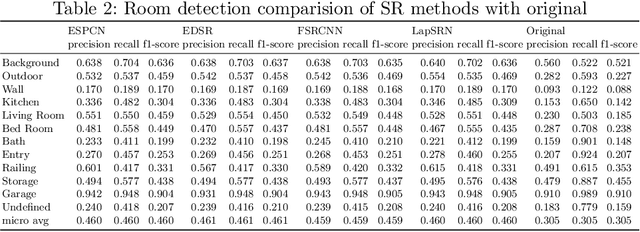
Building Information Modelling (BIM) software use scalable vector formats to enable flexible designing of floor plans in the industry. Floor plans in the architectural domain can come from many sources that may or may not be in scalable vector format. The conversion of floor plan images to fully annotated vector images is a process that can now be realized by computer vision. Novel datasets in this field have been used to train Convolutional Neural Network (CNN) architectures for object detection. Image enhancement through Super-Resolution (SR) is also an established CNN based network in computer vision that is used for converting low resolution images to high resolution ones. This work focuses on creating a multi-component module that stacks a SR model on a floor plan object detection model. The proposed stacked model shows greater performance than the corresponding vanilla object detection model. For the best case, the the inclusion of SR showed an improvement of 39.47% in object detection over the vanilla network. Data and code are made publicly available at https://github.com/rbg-research/Floor-Plan-Detection.
Geometry Based Machining Feature Retrieval with Inductive Transfer Learning
Aug 26, 2021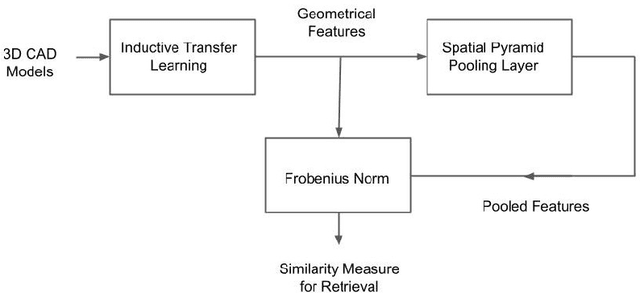
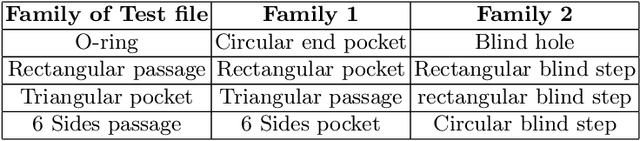

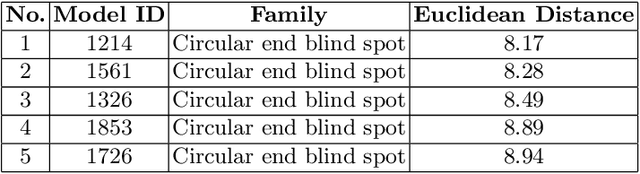
Manufacturing industries have widely adopted the reuse of machine parts as a method to reduce costs and as a sustainable manufacturing practice. Identification of reusable features from the design of the parts and finding their similar features from the database is an important part of this process. In this project, with the help of fully convolutional geometric features, we are able to extract and learn the high level semantic features from CAD models with inductive transfer learning. The extracted features are then compared with that of other CAD models from the database using Frobenius norm and identical features are retrieved. Later we passed the extracted features to a deep convolutional neural network with a spatial pyramid pooling layer and the performance of the feature retrieval increased significantly. It was evident from the results that the model could effectively capture the geometrical elements from machining features.
Deep-Net: Deep Neural Network for Cyber Security Use Cases
Dec 09, 2018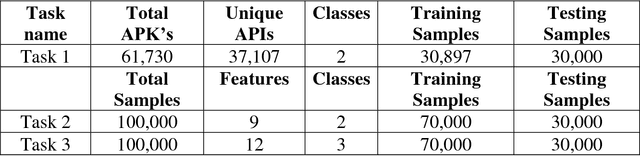
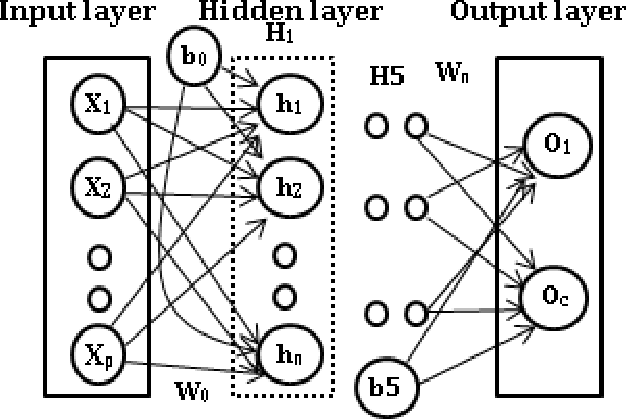
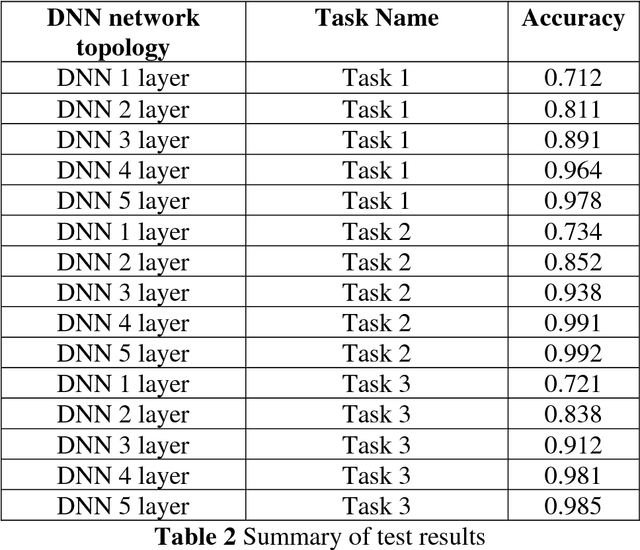

Deep neural networks (DNNs) have witnessed as a powerful approach in this year by solving long-standing Artificial intelligence (AI) supervised and unsupervised tasks exists in natural language processing, speech processing, computer vision and others. In this paper, we attempt to apply DNNs on three different cyber security use cases: Android malware classification, incident detection and fraud detection. The data set of each use case contains real known benign and malicious activities samples. The efficient network architecture for DNN is chosen by conducting various trails of experiments for network parameters and network structures. The experiments of such chosen efficient configurations of DNNs are run up to 1000 epochs with learning rate set in the range [0.01-0.5]. Experiments of DNN performed well in comparison to the classical machine learning algorithms in all cases of experiments of cyber security use cases. This is due to the fact that DNNs implicitly extract and build better features, identifies the characteristics of the data that lead to better accuracy. The best accuracy obtained by DNN and XGBoost on Android malware classification 0.940 and 0.741, incident detection 1.00 and 0.997 fraud detection 0.972 and 0.916 respectively.
Social Media Analysis based on Semanticity of Streaming and Batch Data
Jan 05, 2018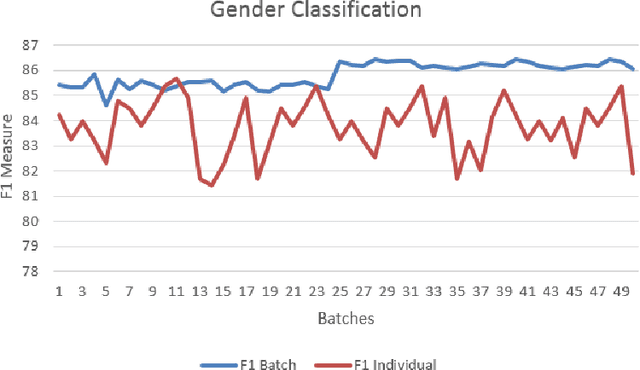

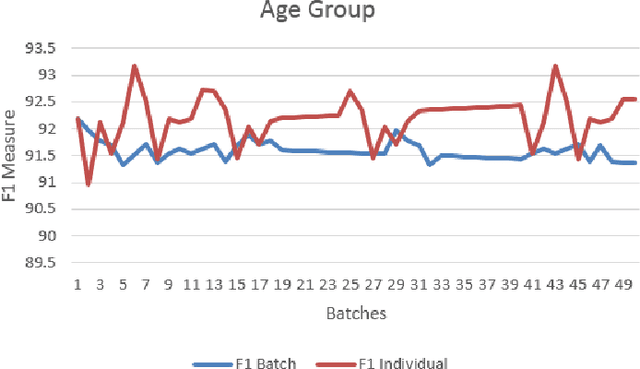

Languages shared by people differ in different regions based on their accents, pronunciation and word usages. In this era sharing of language takes place mainly through social media and blogs. Every second swing of such a micro posts exist which induces the need of processing those micro posts, in-order to extract knowledge out of it. Knowledge extraction differs with respect to the application in which the research on cognitive science fed the necessities for the same. This work further moves forward such a research by extracting semantic information of streaming and batch data in applications like Named Entity Recognition and Author Profiling. In the case of Named Entity Recognition context of a single micro post has been utilized and context that lies in the pool of micro posts were utilized to identify the sociolect aspects of the author of those micro posts. In this work Conditional Random Field has been utilized to do the entity recognition and a novel approach has been proposed to find the sociolect aspects of the author (Gender, Age group).
Deep Health Care Text Classification
Oct 23, 2017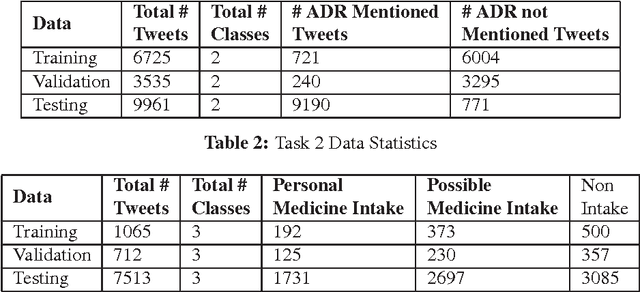

Health related social media mining is a valuable apparatus for the early recognition of the diverse antagonistic medicinal conditions. Mostly, the existing methods are based on machine learning with knowledge-based learning. This working note presents the Recurrent neural network (RNN) and Long short-term memory (LSTM) based embedding for automatic health text classification in the social media mining. For each task, two systems are built and that classify the tweet at the tweet level. RNN and LSTM are used for extracting features and non-linear activation function at the last layer facilitates to distinguish the tweets of different categories. The experiments are conducted on 2nd Social Media Mining for Health Applications Shared Task at AMIA 2017. The experiment results are considerable; however the proposed method is appropriate for the health text classification. This is primarily due to the reason that, it doesn't rely on any feature engineering mechanisms.
Vector Space Model as Cognitive Space for Text Classification
Aug 21, 2017
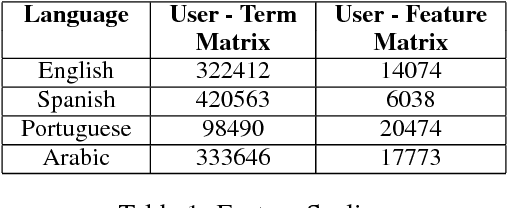
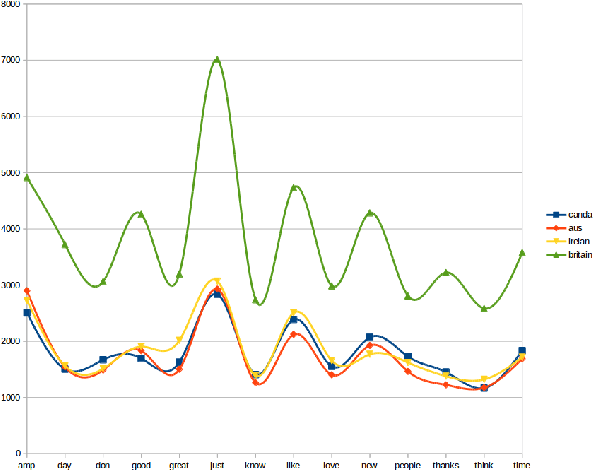
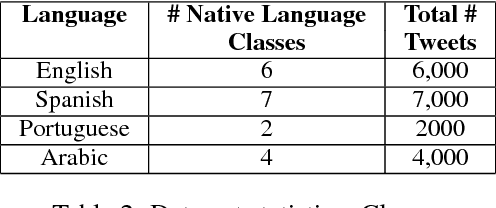
In this era of digitization, knowing the user's sociolect aspects have become essential features to build the user specific recommendation systems. These sociolect aspects could be found by mining the user's language sharing in the form of text in social media and reviews. This paper describes about the experiment that was performed in PAN Author Profiling 2017 shared task. The objective of the task is to find the sociolect aspects of the users from their tweets. The sociolect aspects considered in this experiment are user's gender and native language information. Here user's tweets written in a different language from their native language are represented as Document - Term Matrix with document frequency as the constraint. Further classification is done using the Support Vector Machine by taking gender and native language as target classes. This experiment attains the average accuracy of 73.42% in gender prediction and 76.26% in the native language identification task.