 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Space Model as Cognitive Space for Text Classification
Paper and Code
Aug 21, 2017
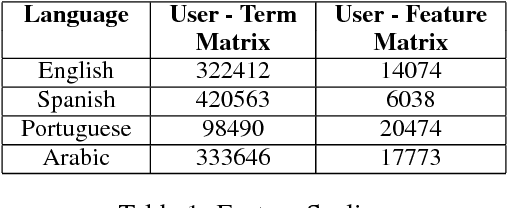
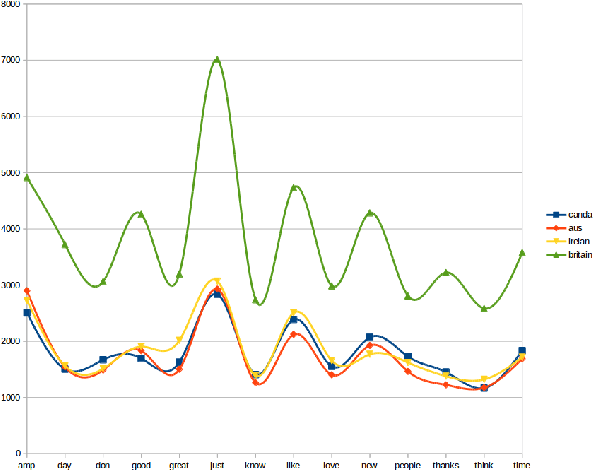
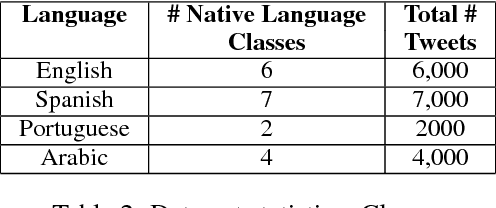
In this era of digitization, knowing the user's sociolect aspects have become essential features to build the user specific recommendation systems. These sociolect aspects could be found by mining the user's language sharing in the form of text in social media and reviews. This paper describes about the experiment that was performed in PAN Author Profiling 2017 shared task. The objective of the task is to find the sociolect aspects of the users from their tweets. The sociolect aspects considered in this experiment are user's gender and native language information. Here user's tweets written in a different language from their native language are represented as Document - Term Matrix with document frequency as the constraint. Further classification is done using the Support Vector Machine by taking gender and native language as target classes. This experiment attains the average accuracy of 73.42% in gender prediction and 76.26% in the native language identification task.