 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Learning Approach for Similar Languages, Varieties and Dialects
Paper and Code
Jan 02, 2019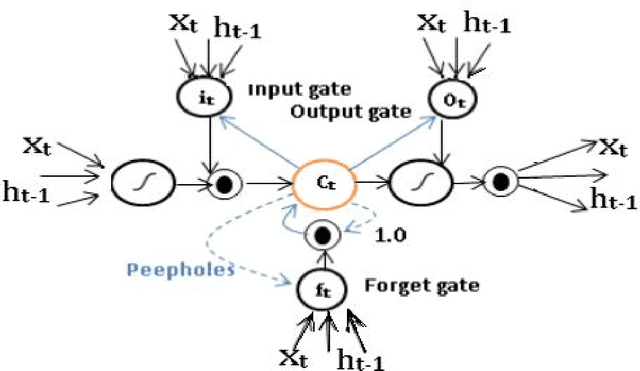
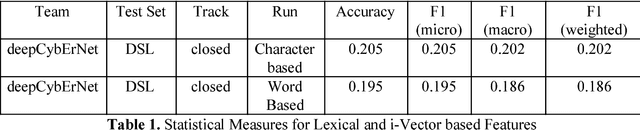
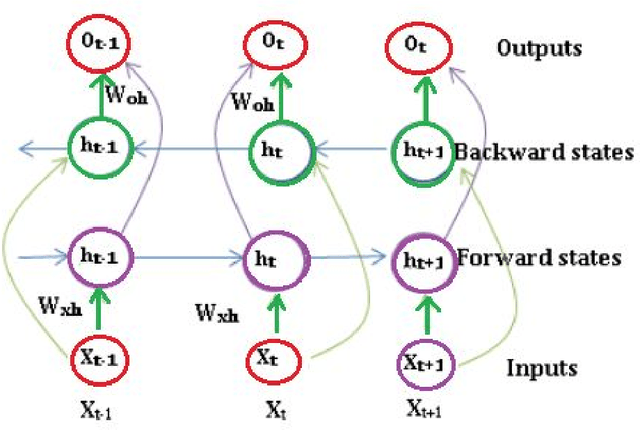
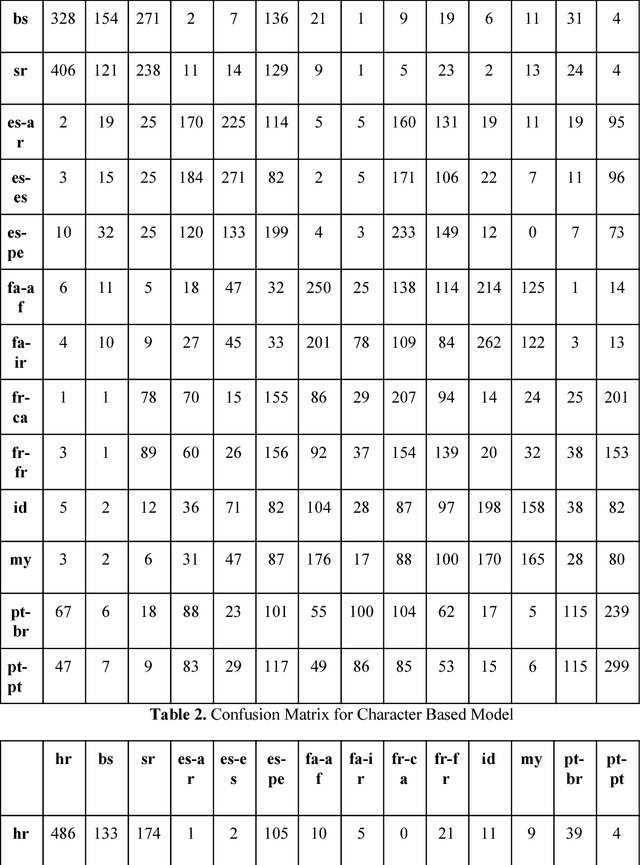
Deep learning mechanisms are prevailing approaches in recent days for the various tasks in natural language processing, speech recognition, image processing and many others. To leverage this we use deep learning based mechanism specifically Bidirectional- Long Short-Term Memory (B-LSTM) for the task of dialectic identification in Arabic and German broadcast speech and Long Short-Term Memory (LSTM) for discriminating between similar Languages. Two unique B-LSTM models are created using the Large-vocabulary Continuous Speech Recognition (LVCSR) based lexical features and a fixed length of 400 per utterance bottleneck features generated by i-vector framework. These models were evaluated on the VarDial 2017 datasets for the tasks Arabic, German dialect identification with dialects of Egyptian, Gulf, Levantine, North African, and MSA for Arabic and Basel, Bern, Lucerne, and Zurich for German. Also for the task of Discriminating between Similar Languages like Bosnian, Croatian and Serbian. The B-LSTM model showed accuracy of 0.246 on lexical features and accuracy of 0.577 bottleneck features of i-Vector framework.