 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards understanding Diffusion Models (on Graphs)
Aug 31, 2024Diffusion models have emerged from various theoretical and methodological perspectives, each offering unique insights into their underlying principles. In this work, we provide an overview of the most prominent approaches, drawing attention to their striking analogies -- namely, how seemingly diverse methodologies converge to a similar mathematical formulation of the core problem. While our ultimate goal is to understand these models in the context of graphs, we begin by conducting experiments in a simpler setting to build foundational insights. Through an empirical investigation of different diffusion and sampling techniques, we explore three critical questions: (1) What role does noise play in these models? (2) How significantly does the choice of the sampling method affect outcomes? (3) What function is the neural network approximating, and is high complexity necessary for optimal performance? Our findings aim to enhance the understanding of diffusion models and in the long run their application in graph machine learning.
Relating graph auto-encoders to linear models
Nov 03, 2022Graph auto-encoders are widely used to construct graph representations in Euclidean vector spaces. However, it has already been pointed out empirically that linear models on many tasks can outperform graph auto-encoders. In our work, we prove that the solution space induced by graph auto-encoders is a subset of the solution space of a linear map. This demonstrates that linear embedding models have at least the representational power of graph auto-encoders based on graph convolutional networks. So why are we still using nonlinear graph auto-encoders? One reason could be that actively restricting the linear solution space might introduce an inductive bias that helps improve learning and generalization. While many researchers believe that the nonlinearity of the encoder is the critical ingredient towards this end, we instead identify the node features of the graph as a more powerful inductive bias. We give theoretical insights by introducing a corresponding bias in a linear model and analyzing the change in the solution space. Our experiments show that the linear encoder can outperform the nonlinear encoder when using feature information.
Tangles: From Weak to Strong Clustering
Jun 25, 2020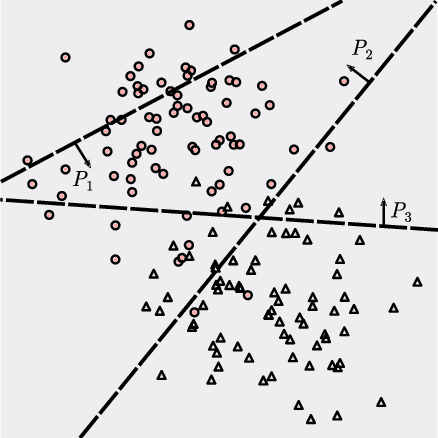
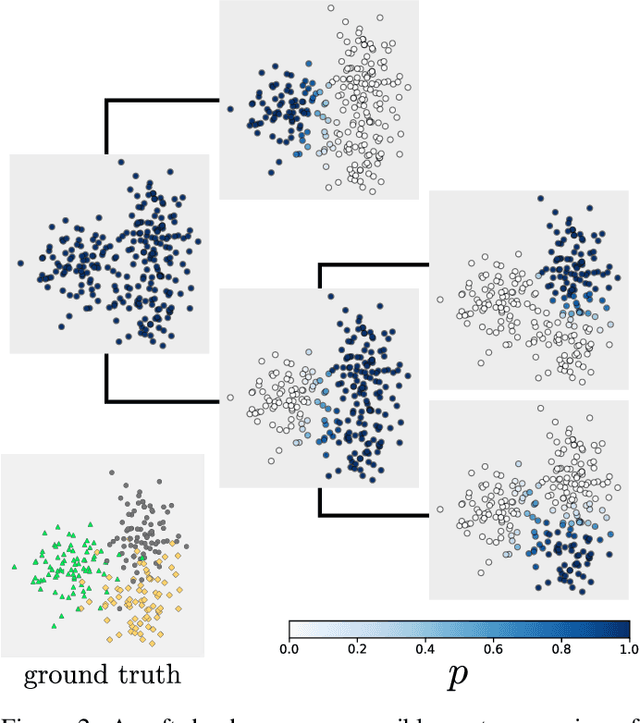
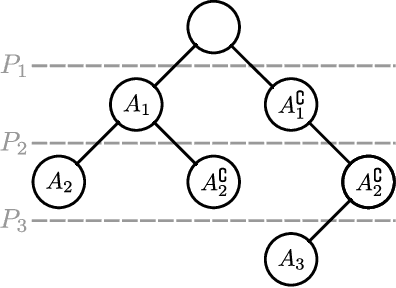
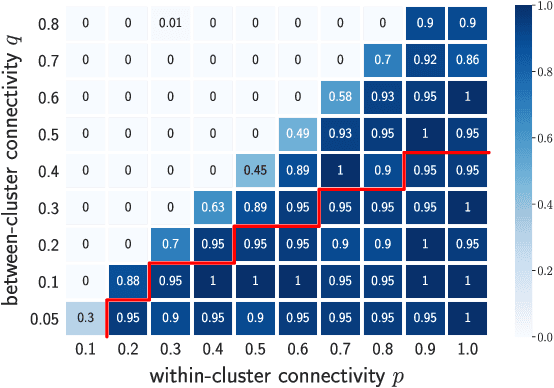
We introduce a new approach to clustering by using tangles, a tool that originates in mathematical graph theory. Given a collection of "weak partitions" of a data set, tangles provide a framework to aggregate these weak partitions such that they "point in the direction of a cluster". As a result, a cluster is softly characterized by a set of consistent pointers. This mechanism provides a highly flexible way of solving soft clustering problems in a variety of setups, ranging from questionnaires over community detection in graphs to clustering points in metric spaces. Conceptually, tangles have many intriguing properties: (1) Similar to boosting, which combines many weak classifiers to a strong classifier, tangles provide a formal way to combine many weak partitions to obtain few strong clusters. (2) In terms of computational complexity, tangles allow us to use simple, fast algorithms to produce the weak partitions. The complexity of identifying the strong partitions is dominated by the number of weak partitions, not the number of data points, leading to an interesting trade-off between the two. (3) If the weak partitions are interpretable, so are the strong partitions induced by the tangles, resulting in one of the rare algorithms to produce interpretable clusters. (4) The output of tangles is of a hierarchical nature, inducing the notion of a soft dendrogram that can be helpful in data visualization.