 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransient Chaos in BERT
Jun 09, 2021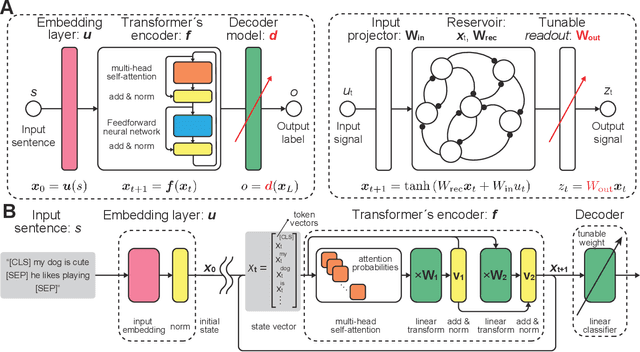
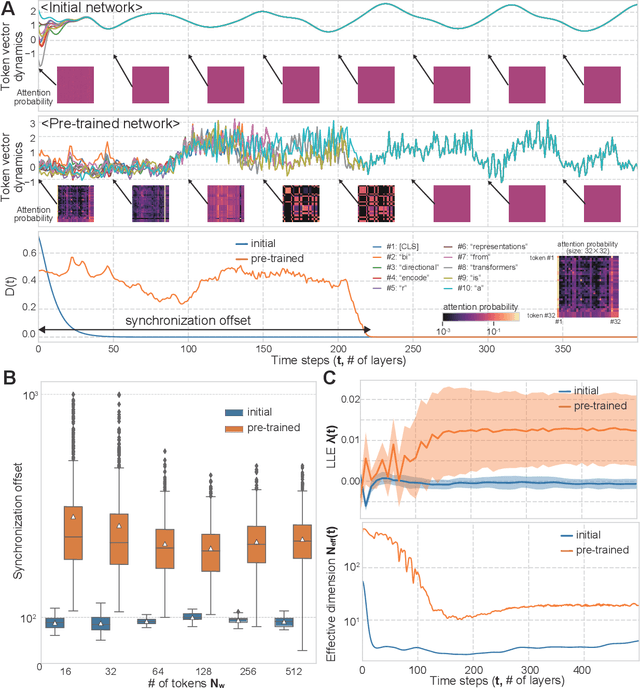
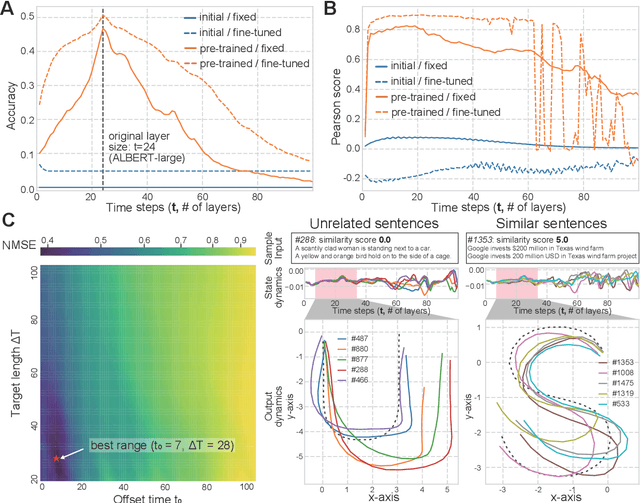
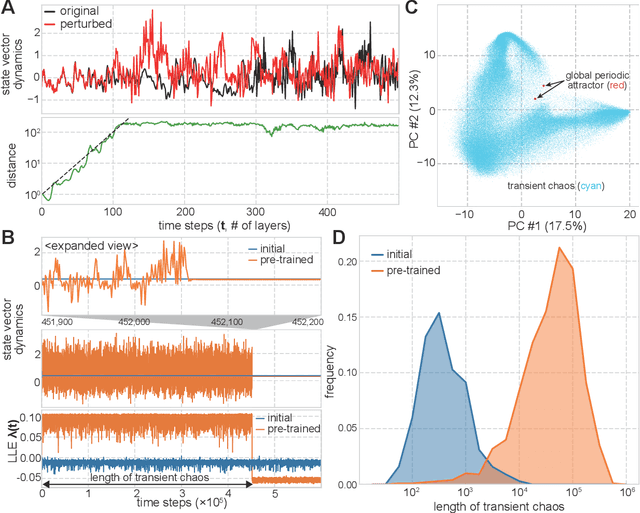
Language is an outcome of our complex and dynamic human-interactions and the technique of natural language processing (NLP) is hence built on human linguistic activities. Bidirectional Encoder Representations from Transformers (BERT) has recently gained its popularity by establishing the state-of-the-art scores in several NLP benchmarks. A Lite BERT (ALBERT) is literally characterized as a lightweight version of BERT, in which the number of BERT parameters is reduced by repeatedly applying the same neural network called Transformer's encoder layer. By pre-training the parameters with a massive amount of natural language data, ALBERT can convert input sentences into versatile high-dimensional vectors potentially capable of solving multiple NLP tasks. In that sense, ALBERT can be regarded as a well-designed high-dimensional dynamical system whose operator is the Transformer's encoder, and essential structures of human language are thus expected to be encapsulated in its dynamics. In this study, we investigated the embedded properties of ALBERT to reveal how NLP tasks are effectively solved by exploiting its dynamics. We thereby aimed to explore the nature of human language from the dynamical expressions of the NLP model. Our short-term analysis clarified that the pre-trained model stably yields trajectories with higher dimensionality, which would enhance the expressive capacity required for NLP tasks. Also, our long-term analysis revealed that ALBERT intrinsically shows transient chaos, a typical nonlinear phenomenon showing chaotic dynamics only in its transient, and the pre-trained ALBERT model tends to produce the chaotic trajectory for a significantly longer time period compared to a randomly-initialized one. Our results imply that local chaoticity would contribute to improving NLP performance, uncovering a novel aspect in the role of chaotic dynamics in human language behaviors.
Hierarchical Multitask Learning with Dependency Parsing for Japanese Semantic Role Labeling Improves Performance of Argument Identification
Jan 15, 2021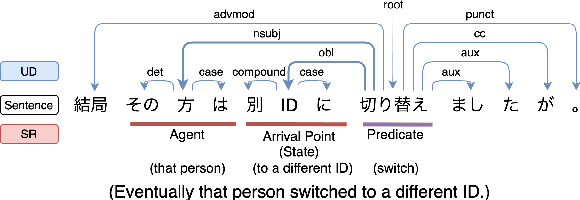

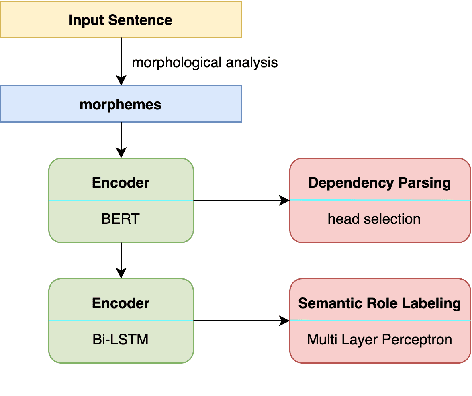

With the advent of FrameNet and PropBank, many semantic role labeling (SRL) systems have been proposed in English. Although research on Japanese predicate argument structure analysis (PASA) has been conducted, most studies focused on surface cases. There are only few previous works on Japanese SRL for deep cases, and their models' accuracies are low. Therefore, we propose a hierarchical multitask learning method with dependency parsing (DP) and show that our model achieves state-of-the-art results in Japanese SRL. Also, we conduct experiments with a joint model that performs both argument identification and argument classification simultaneously. The result suggests that multitasking with DP is mainly effective for argument identification.