 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilevel Stochastic Optimization for Imputation in Massive Medical Data Records
Oct 19, 2021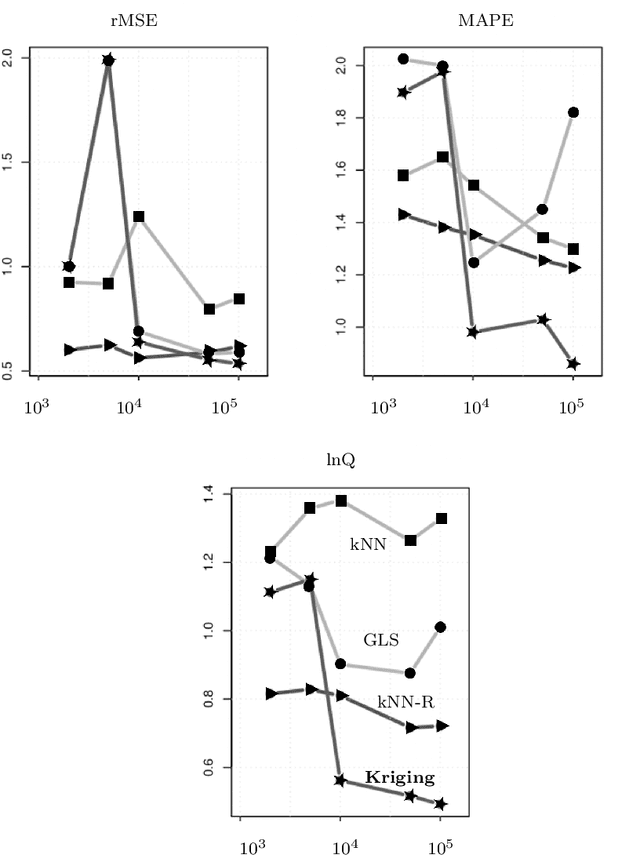

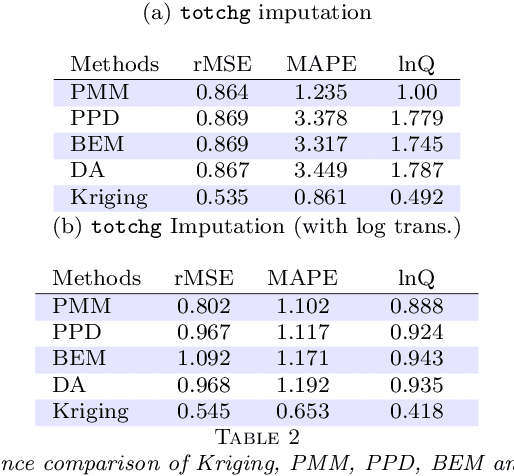
Exploration and analysis of massive datasets has recently generated increasing interest in the research and development communities. It has long been a recognized problem that many datasets contain significant levels of missing numerical data. We introduce a mathematically principled stochastic optimization imputation method based on the theory of Kriging. This is shown to be a powerful method for imputation. However, its computational effort and potential numerical instabilities produce costly and/or unreliable predictions, potentially limiting its use on large scale datasets. In this paper, we apply a recently developed multi-level stochastic optimization approach to the problem of imputation in massive medical records. The approach is based on computational applied mathematics techniques and is highly accurate. In particular, for the Best Linear Unbiased Predictor (BLUP) this multi-level formulation is exact, and is also significantly faster and more numerically stable. This permits practical application of Kriging methods to data imputation problems for massive datasets. We test this approach on data from the National Inpatient Sample (NIS) data records, Healthcare Cost and Utilization Project (HCUP), Agency for Healthcare Research and Quality. Numerical results show the multi-level method significantly outperforms current approaches and is numerically robust. In particular, it has superior accuracy as compared with methods recommended in the recent report from HCUP on the important problem of missing data, which could lead to sub-optimal and poorly based funding policy decisions. In comparative benchmark tests it is shown that the multilevel stochastic method is significantly superior to recommended methods in the report, including Predictive Mean Matching (PMM) and Predicted Posterior Distribution (PPD), with up to 75% reductions in error.