 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDhati+: Fine-tuned Large Language Models for Arabic Subjectivity Evaluation
Aug 27, 2025Despite its significance, Arabic, a linguistically rich and morphologically complex language, faces the challenge of being under-resourced. The scarcity of large annotated datasets hampers the development of accurate tools for subjectivity analysis in Arabic. Recent advances in deep learning and Transformers have proven highly effective for text classification in English and French. This paper proposes a new approach for subjectivity assessment in Arabic textual data. To address the dearth of specialized annotated datasets, we developed a comprehensive dataset, AraDhati+, by leveraging existing Arabic datasets and collections (ASTD, LABR, HARD, and SANAD). Subsequently, we fine-tuned state-of-the-art Arabic language models (XLM-RoBERTa, AraBERT, and ArabianGPT) on AraDhati+ for effective subjectivity classification. Furthermore, we experimented with an ensemble decision approach to harness the strengths of individual models. Our approach achieves a remarkable accuracy of 97.79\,\% for Arabic subjectivity classification. Results demonstrate the effectiveness of the proposed approach in addressing the challenges posed by limited resources in Arabic language processing.
Arabic Multimodal Machine Learning: Datasets, Applications, Approaches, and Challenges
Aug 17, 2025Multimodal Machine Learning (MML) aims to integrate and analyze information from diverse modalities, such as text, audio, and visuals, enabling machines to address complex tasks like sentiment analysis, emotion recognition, and multimedia retrieval. Recently, Arabic MML has reached a certain level of maturity in its foundational development, making it time to conduct a comprehensive survey. This paper explores Arabic MML by categorizing efforts through a novel taxonomy and analyzing existing research. Our taxonomy organizes these efforts into four key topics: datasets, applications, approaches, and challenges. By providing a structured overview, this survey offers insights into the current state of Arabic MML, highlighting areas that have not been investigated and critical research gaps. Researchers will be empowered to build upon the identified opportunities and address challenges to advance the field.
A Noise-Resilient Semi-Supervised Graph Autoencoder for Overlapping Semantic Community Detection
May 09, 2025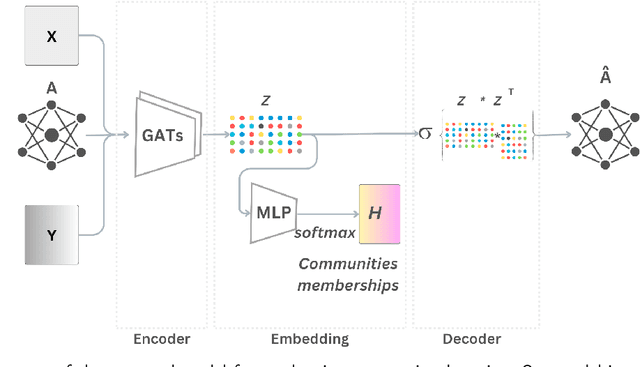



Community detection in networks with overlapping structures remains a significant challenge, particularly in noisy real-world environments where integrating topology, node attributes, and prior information is critical. To address this, we propose a semi-supervised graph autoencoder that combines graph multi-head attention and modularity maximization to robustly detect overlapping communities. The model learns semantic representations by fusing structural, attribute, and prior knowledge while explicitly addressing noise in node features. Key innovations include a noise-resistant architecture and a semantic semi-supervised design optimized for community quality through modularity constraints. Experiments demonstrate superior performance the model outperforms state-of-the-art methods in overlapping community detection (improvements in NMI and F1-score) and exhibits exceptional robustness to attribute noise, maintaining stable performance under 60\% feature corruption. These results highlight the importance of integrating attribute semantics and structural patterns for accurate community discovery in complex networks.
Unsupervised Graph Attention Autoencoder for Attributed Networks using K-means Loss
Nov 24, 2023Several natural phenomena and complex systems are often represented as networks. Discovering their community structure is a fundamental task for understanding these networks. Many algorithms have been proposed, but recently, Graph Neural Networks (GNN) have emerged as a compelling approach for enhancing this task.In this paper, we introduce a simple, efficient, and clustering-oriented model based on unsupervised \textbf{G}raph Attention \textbf{A}uto\textbf{E}ncoder for community detection in attributed networks (GAECO). The proposed model adeptly learns representations from both the network's topology and attribute information, simultaneously addressing dual objectives: reconstruction and community discovery. It places a particular emphasis on discovering compact communities by robustly minimizing clustering errors. The model employs k-means as an objective function and utilizes a multi-head Graph Attention Auto-Encoder for decoding the representations. Experiments conducted on three datasets of attributed networks show that our method surpasses state-of-the-art algorithms in terms of NMI and ARI. Additionally, our approach scales effectively with the size of the network, making it suitable for large-scale applications. The implications of our findings extend beyond biological network interpretation and social network analysis, where knowledge of the fundamental community structure is essential.
Modality Influence in Multimodal Machine Learning
Jun 10, 2023



Multimodal Machine Learning has emerged as a prominent research direction across various applications such as Sentiment Analysis, Emotion Recognition, Machine Translation, Hate Speech Recognition, and Movie Genre Classification. This approach has shown promising results by utilizing modern deep learning architectures. Despite the achievements made, challenges remain in data representation, alignment techniques, reasoning, generation, and quantification within multimodal learning. Additionally, assumptions about the dominant role of textual modality in decision-making have been made. However, limited investigations have been conducted on the influence of different modalities in Multimodal Machine Learning systems. This paper aims to address this gap by studying the impact of each modality on multimodal learning tasks. The research focuses on verifying presumptions and gaining insights into the usage of different modalities. The main contribution of this work is the proposal of a methodology to determine the effect of each modality on several Multimodal Machine Learning models and datasets from various tasks. Specifically, the study examines Multimodal Sentiment Analysis, Multimodal Emotion Recognition, Multimodal Hate Speech Recognition, and Multimodal Disease Detection. The study objectives include training SOTA MultiModal Machine Learning models with masked modalities to evaluate their impact on performance. Furthermore, the research aims to identify the most influential modality or set of modalities for each task and draw conclusions for diverse multimodal classification tasks. By undertaking these investigations, this research contributes to a better understanding of the role of individual modalities in multi-modal learning and provides valuable insights for future advancements in this field.
Towards Arabic Multimodal Dataset for Sentiment Analysis
Jun 10, 2023Multimodal Sentiment Analysis (MSA) has recently become a centric research direction for many real-world applications. This proliferation is due to the fact that opinions are central to almost all human activities and are key influencers of our behaviors. In addition, the recent deployment of Deep Learning-based (DL) models has proven their high efficiency for a wide range of Western languages. In contrast, Arabic DL-based multimodal sentiment analysis (MSA) is still in its infantile stage due, mainly, to the lack of standard datasets. In this paper, our investigation is twofold. First, we design a pipeline that helps building our Arabic Multimodal dataset leveraging both state-of-the-art transformers and feature extraction tools within word alignment techniques. Thereafter, we validate our dataset using state-of-the-art transformer-based model dealing with multimodality. Despite the small size of the outcome dataset, experiments show that Arabic multimodality is very promising
Efficient Geometric-based Computation of the String Subsequence Kernel
Feb 26, 2015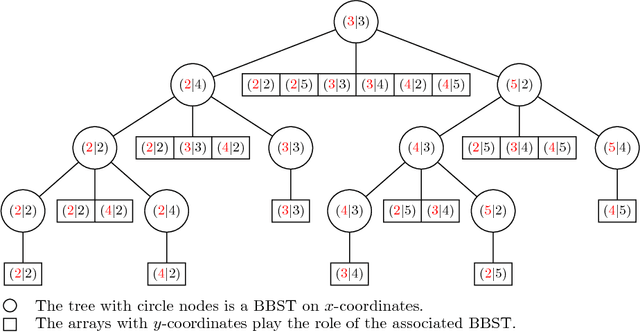



Kernel methods are powerful tools in machine learning. They have to be computationally efficient. In this paper, we present a novel Geometric-based approach to compute efficiently the string subsequence kernel (SSK). Our main idea is that the SSK computation reduces to range query problem. We started by the construction of a match list $L(s,t)=\{(i,j):s_{i}=t_{j}\}$ where $s$ and $t$ are the strings to be compared; such match list contains only the required data that contribute to the result. To compute efficiently the SSK, we extended the layered range tree data structure to a layered range sum tree, a range-aggregation data structure. The whole process takes $ O(p|L|\log|L|)$ time and $O(|L|\log|L|)$ space, where $|L|$ is the size of the match list and $p$ is the length of the SSK. We present empiric evaluations of our approach against the dynamic and the sparse programming approaches both on synthetically generated data and on newswire article data. Such experiments show the efficiency of our approach for large alphabet size except for very short strings. Moreover, compared to the sparse dynamic approach, the proposed approach outperforms absolutely for long strings.