 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Tree Kernel Computation
May 12, 2023



Tree kernels are fundamental tools that have been leveraged in many applications, particularly those based on machine learning for Natural Language Processing tasks. In this paper, we devise a parallel implementation of the sequential algorithm for the computation of some tree kernels of two finite sets of trees (Ouali-Sebti, 2015). Our comparison is narrowed on a sequential implementation of SubTree kernel computation. This latter is mainly reduced to an intersection of weighted tree automata. Our approach relies on the nature of the data parallelism source inherent in this computation by deploying the MapReduce paradigm. One of the key benefits of our approach is its versatility in being adaptable to a wide range of substructure tree kernel-based learning methods. To evaluate the efficacy of our parallel approach, we conducted a series of experiments that compared it against the sequential version using a diverse set of synthetic tree language datasets that were manually crafted for our analysis. The reached results clearly demonstrate that the proposed parallel algorithm outperforms the sequential one in terms of latency.
New Linear-time Algorithm for SubTree Kernel Computation based on Root-Weighted Tree Automata
Feb 02, 2023



Tree kernels have been proposed to be used in many areas as the automatic learning of natural language applications. In this paper, we propose a new linear time algorithm based on the concept of weighted tree automata for SubTree kernel computation. First, we introduce a new class of weighted tree automata, called Root-Weighted Tree Automata, and their associated formal tree series. Then we define, from this class, the SubTree automata that represent compact computational models for finite tree languages. This allows us to design a theoretically guaranteed linear-time algorithm for computing the SubTree Kernel based on weighted tree automata intersection. The key idea behind the proposed algorithm is to replace DAG reduction and nodes sorting steps used in previous approaches by states equivalence classes computation allowed in the weighted tree automata approach. Our approach has three major advantages: it is output-sensitive, it is free sensitive from the tree types (ordered trees versus unordered trees), and it is well adapted to any incremental tree kernel based learning methods. Finally, we conduct a variety of comparative experiments on a wide range of synthetic tree languages datasets adapted for a deep algorithm analysis. The obtained results show that the proposed algorithm outperforms state-of-the-art methods.
Hierarchical Classification for Spoken Arabic Dialect Identification using Prosody: Case of Algerian Dialects
Mar 29, 2017

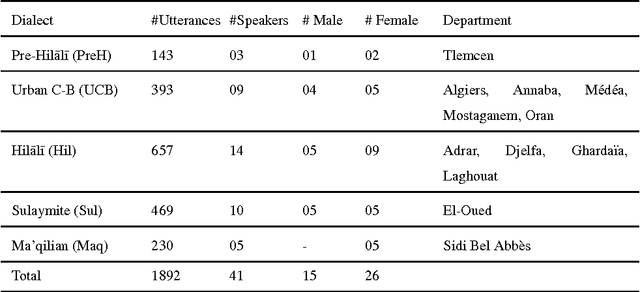

In daily communications, Arabs use local dialects which are hard to identify automatically using conventional classification methods. The dialect identification challenging task becomes more complicated when dealing with an under-resourced dialects belonging to a same county/region. In this paper, we start by analyzing statistically Algerian dialects in order to capture their specificities related to prosody information which are extracted at utterance level after a coarse-grained consonant/vowel segmentation. According to these analysis findings, we propose a Hierarchical classification approach for spoken Arabic algerian Dialect IDentification (HADID). It takes advantage from the fact that dialects have an inherent property of naturally structured into hierarchy. Within HADID, a top-down hierarchical classification is applied, in which we use Deep Neural Networks (DNNs) method to build a local classifier for every parent node into the hierarchy dialect structure. Our framework is implemented and evaluated on Algerian Arabic dialects corpus. Whereas, the hierarchy dialect structure is deduced from historic and linguistic knowledges. The results reveal that within {\HD}, the best classifier is DNNs compared to Support Vector Machine. In addition, compared with a baseline Flat classification system, our HADID gives an improvement of 63.5% in term of precision. Furthermore, overall results evidence the suitability of our prosody-based HADID for speaker independent dialect identification while requiring less than 6s test utterances.
Efficient Geometric-based Computation of the String Subsequence Kernel
Feb 26, 2015



Kernel methods are powerful tools in machine learning. They have to be computationally efficient. In this paper, we present a novel Geometric-based approach to compute efficiently the string subsequence kernel (SSK). Our main idea is that the SSK computation reduces to range query problem. We started by the construction of a match list $L(s,t)=\{(i,j):s_{i}=t_{j}\}$ where $s$ and $t$ are the strings to be compared; such match list contains only the required data that contribute to the result. To compute efficiently the SSK, we extended the layered range tree data structure to a layered range sum tree, a range-aggregation data structure. The whole process takes $ O(p|L|\log|L|)$ time and $O(|L|\log|L|)$ space, where $|L|$ is the size of the match list and $p$ is the length of the SSK. We present empiric evaluations of our approach against the dynamic and the sparse programming approaches both on synthetically generated data and on newswire article data. Such experiments show the efficiency of our approach for large alphabet size except for very short strings. Moreover, compared to the sparse dynamic approach, the proposed approach outperforms absolutely for long strings.
Rational Kernels for Arabic Stemming and Text Classification
Feb 26, 2015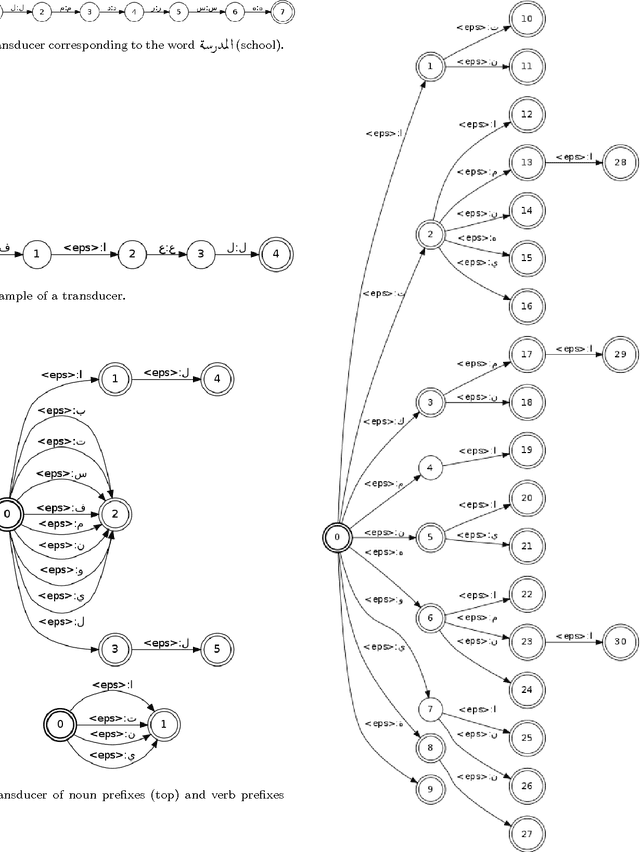
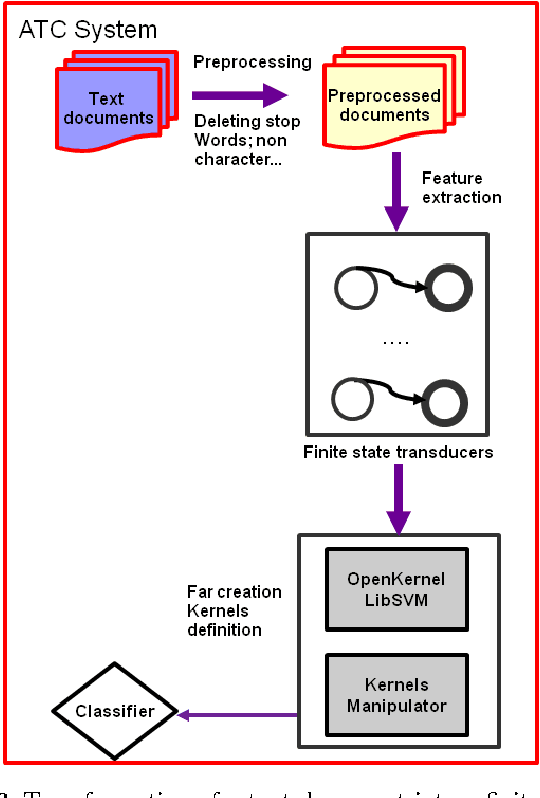
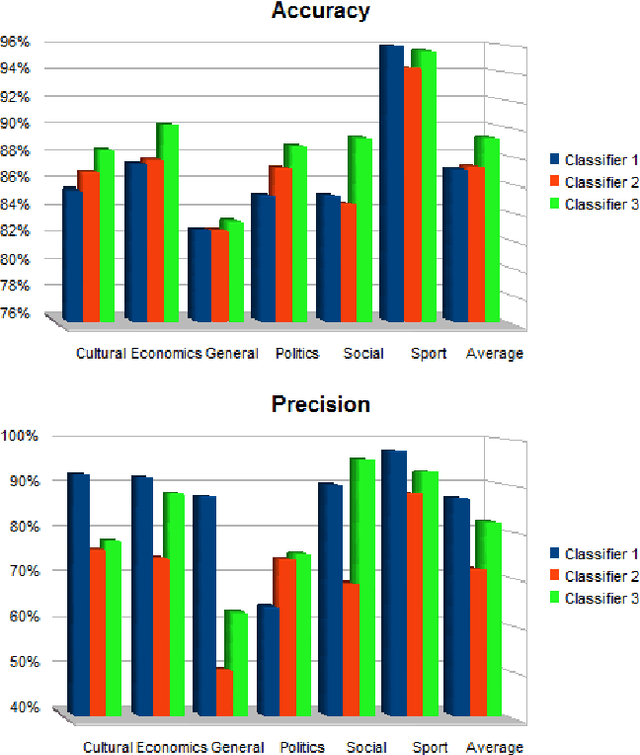
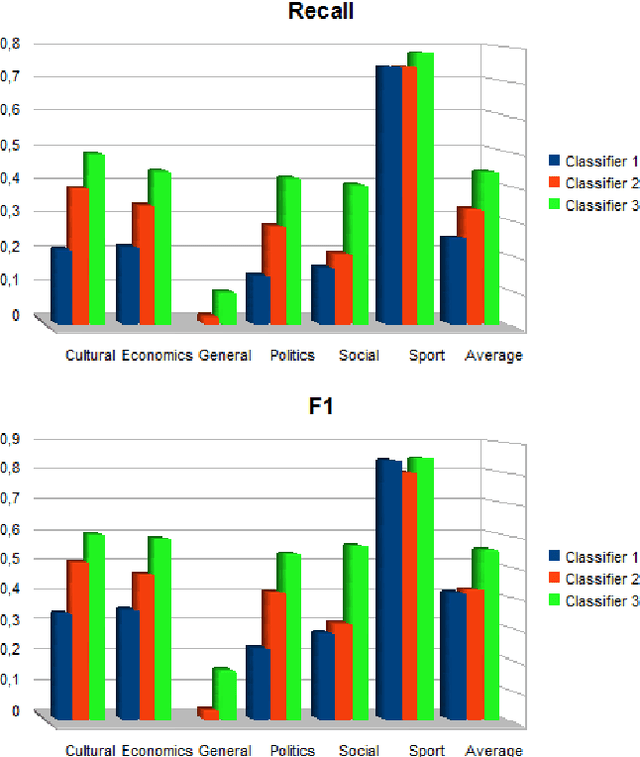
In this paper, we address the problems of Arabic Text Classification and stemming using Transducers and Rational Kernels. We introduce a new stemming technique based on the use of Arabic patterns (Pattern Based Stemmer). Patterns are modelled using transducers and stemming is done without depending on any dictionary. Using transducers for stemming, documents are transformed into finite state transducers. This document representation allows us to use and explore rational kernels as a framework for Arabic Text Classification. Stemming experiments are conducted on three word collections and classification experiments are done on the Saudi Press Agency dataset. Results show that our approach, when compared with other approaches, is promising specially in terms of Accuracy, Recall and F1.