 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabic Multimodal Machine Learning: Datasets, Applications, Approaches, and Challenges
Aug 17, 2025Multimodal Machine Learning (MML) aims to integrate and analyze information from diverse modalities, such as text, audio, and visuals, enabling machines to address complex tasks like sentiment analysis, emotion recognition, and multimedia retrieval. Recently, Arabic MML has reached a certain level of maturity in its foundational development, making it time to conduct a comprehensive survey. This paper explores Arabic MML by categorizing efforts through a novel taxonomy and analyzing existing research. Our taxonomy organizes these efforts into four key topics: datasets, applications, approaches, and challenges. By providing a structured overview, this survey offers insights into the current state of Arabic MML, highlighting areas that have not been investigated and critical research gaps. Researchers will be empowered to build upon the identified opportunities and address challenges to advance the field.
Modality Influence in Multimodal Machine Learning
Jun 10, 2023



Multimodal Machine Learning has emerged as a prominent research direction across various applications such as Sentiment Analysis, Emotion Recognition, Machine Translation, Hate Speech Recognition, and Movie Genre Classification. This approach has shown promising results by utilizing modern deep learning architectures. Despite the achievements made, challenges remain in data representation, alignment techniques, reasoning, generation, and quantification within multimodal learning. Additionally, assumptions about the dominant role of textual modality in decision-making have been made. However, limited investigations have been conducted on the influence of different modalities in Multimodal Machine Learning systems. This paper aims to address this gap by studying the impact of each modality on multimodal learning tasks. The research focuses on verifying presumptions and gaining insights into the usage of different modalities. The main contribution of this work is the proposal of a methodology to determine the effect of each modality on several Multimodal Machine Learning models and datasets from various tasks. Specifically, the study examines Multimodal Sentiment Analysis, Multimodal Emotion Recognition, Multimodal Hate Speech Recognition, and Multimodal Disease Detection. The study objectives include training SOTA MultiModal Machine Learning models with masked modalities to evaluate their impact on performance. Furthermore, the research aims to identify the most influential modality or set of modalities for each task and draw conclusions for diverse multimodal classification tasks. By undertaking these investigations, this research contributes to a better understanding of the role of individual modalities in multi-modal learning and provides valuable insights for future advancements in this field.
Towards Arabic Multimodal Dataset for Sentiment Analysis
Jun 10, 2023Multimodal Sentiment Analysis (MSA) has recently become a centric research direction for many real-world applications. This proliferation is due to the fact that opinions are central to almost all human activities and are key influencers of our behaviors. In addition, the recent deployment of Deep Learning-based (DL) models has proven their high efficiency for a wide range of Western languages. In contrast, Arabic DL-based multimodal sentiment analysis (MSA) is still in its infantile stage due, mainly, to the lack of standard datasets. In this paper, our investigation is twofold. First, we design a pipeline that helps building our Arabic Multimodal dataset leveraging both state-of-the-art transformers and feature extraction tools within word alignment techniques. Thereafter, we validate our dataset using state-of-the-art transformer-based model dealing with multimodality. Despite the small size of the outcome dataset, experiments show that Arabic multimodality is very promising
Parallel Tree Kernel Computation
May 12, 2023Tree kernels are fundamental tools that have been leveraged in many applications, particularly those based on machine learning for Natural Language Processing tasks. In this paper, we devise a parallel implementation of the sequential algorithm for the computation of some tree kernels of two finite sets of trees (Ouali-Sebti, 2015). Our comparison is narrowed on a sequential implementation of SubTree kernel computation. This latter is mainly reduced to an intersection of weighted tree automata. Our approach relies on the nature of the data parallelism source inherent in this computation by deploying the MapReduce paradigm. One of the key benefits of our approach is its versatility in being adaptable to a wide range of substructure tree kernel-based learning methods. To evaluate the efficacy of our parallel approach, we conducted a series of experiments that compared it against the sequential version using a diverse set of synthetic tree language datasets that were manually crafted for our analysis. The reached results clearly demonstrate that the proposed parallel algorithm outperforms the sequential one in terms of latency.
Hierarchical Classification for Spoken Arabic Dialect Identification using Prosody: Case of Algerian Dialects
Mar 29, 2017

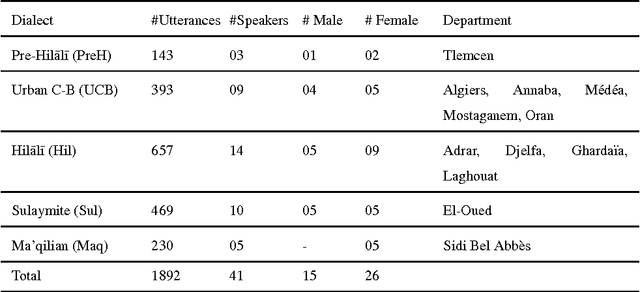

In daily communications, Arabs use local dialects which are hard to identify automatically using conventional classification methods. The dialect identification challenging task becomes more complicated when dealing with an under-resourced dialects belonging to a same county/region. In this paper, we start by analyzing statistically Algerian dialects in order to capture their specificities related to prosody information which are extracted at utterance level after a coarse-grained consonant/vowel segmentation. According to these analysis findings, we propose a Hierarchical classification approach for spoken Arabic algerian Dialect IDentification (HADID). It takes advantage from the fact that dialects have an inherent property of naturally structured into hierarchy. Within HADID, a top-down hierarchical classification is applied, in which we use Deep Neural Networks (DNNs) method to build a local classifier for every parent node into the hierarchy dialect structure. Our framework is implemented and evaluated on Algerian Arabic dialects corpus. Whereas, the hierarchy dialect structure is deduced from historic and linguistic knowledges. The results reveal that within {\HD}, the best classifier is DNNs compared to Support Vector Machine. In addition, compared with a baseline Flat classification system, our HADID gives an improvement of 63.5% in term of precision. Furthermore, overall results evidence the suitability of our prosody-based HADID for speaker independent dialect identification while requiring less than 6s test utterances.
Efficient Geometric-based Computation of the String Subsequence Kernel
Feb 26, 2015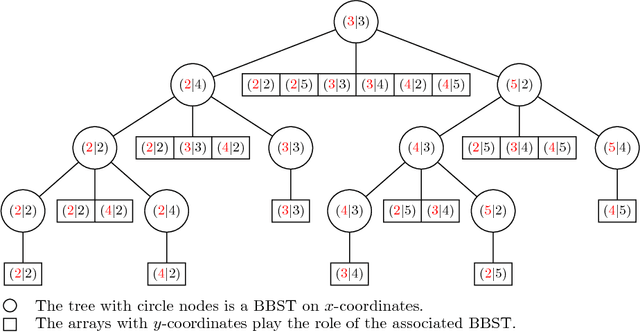



Kernel methods are powerful tools in machine learning. They have to be computationally efficient. In this paper, we present a novel Geometric-based approach to compute efficiently the string subsequence kernel (SSK). Our main idea is that the SSK computation reduces to range query problem. We started by the construction of a match list $L(s,t)=\{(i,j):s_{i}=t_{j}\}$ where $s$ and $t$ are the strings to be compared; such match list contains only the required data that contribute to the result. To compute efficiently the SSK, we extended the layered range tree data structure to a layered range sum tree, a range-aggregation data structure. The whole process takes $ O(p|L|\log|L|)$ time and $O(|L|\log|L|)$ space, where $|L|$ is the size of the match list and $p$ is the length of the SSK. We present empiric evaluations of our approach against the dynamic and the sparse programming approaches both on synthetically generated data and on newswire article data. Such experiments show the efficiency of our approach for large alphabet size except for very short strings. Moreover, compared to the sparse dynamic approach, the proposed approach outperforms absolutely for long strings.
Rational Kernels for Arabic Stemming and Text Classification
Feb 26, 2015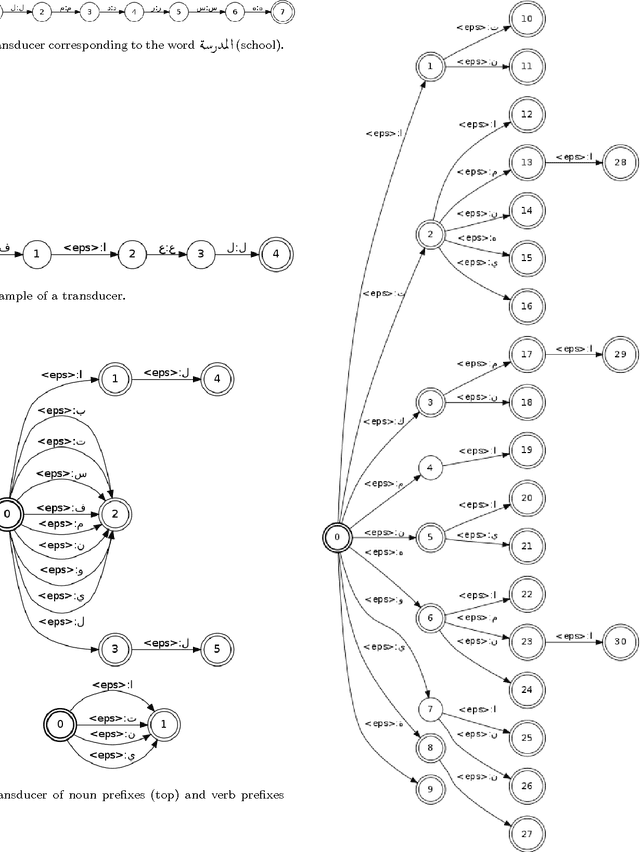
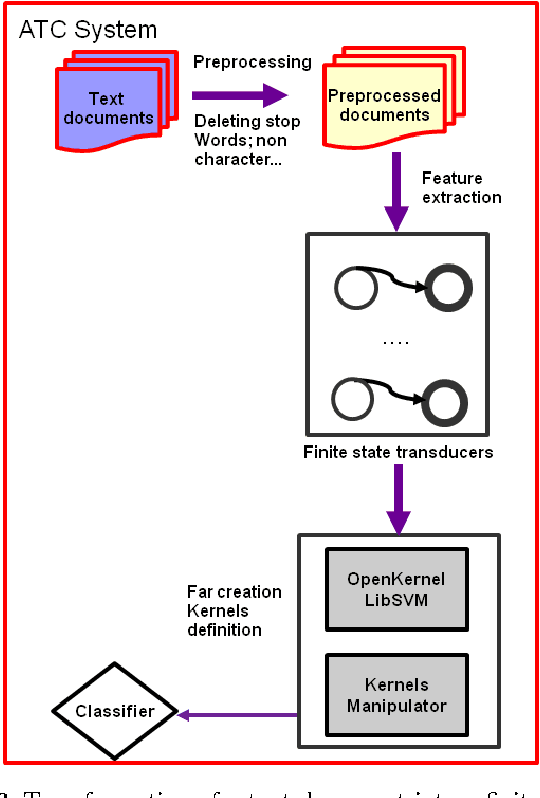
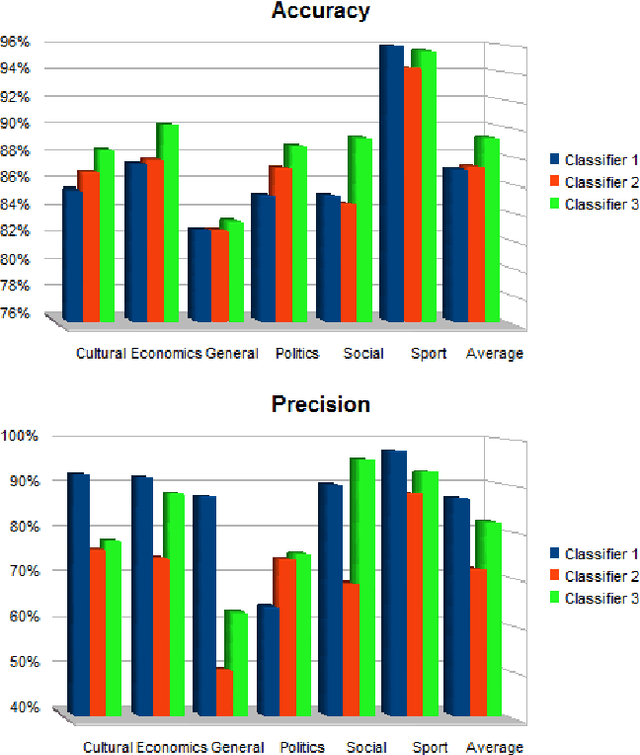
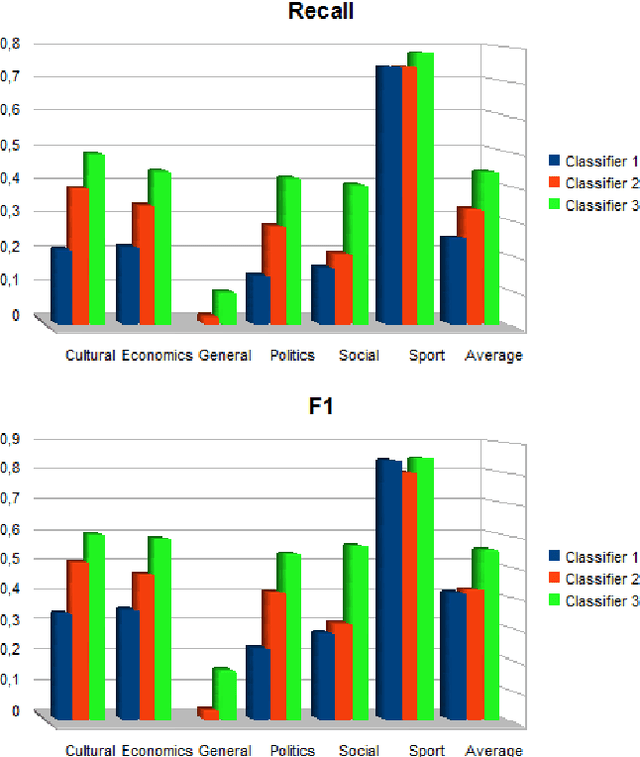
In this paper, we address the problems of Arabic Text Classification and stemming using Transducers and Rational Kernels. We introduce a new stemming technique based on the use of Arabic patterns (Pattern Based Stemmer). Patterns are modelled using transducers and stemming is done without depending on any dictionary. Using transducers for stemming, documents are transformed into finite state transducers. This document representation allows us to use and explore rational kernels as a framework for Arabic Text Classification. Stemming experiments are conducted on three word collections and classification experiments are done on the Saudi Press Agency dataset. Results show that our approach, when compared with other approaches, is promising specially in terms of Accuracy, Recall and F1.