 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSleeper Cell: Injecting Latent Malice Temporal Backdoors into Tool-Using LLMs
Mar 02, 2026The proliferation of open-weight Large Language Models (LLMs) has democratized agentic AI, yet fine-tuned weights are frequently shared and adopted with limited scrutiny beyond leaderboard performance. This creates a risk where third-party models are incorporated without strong behavioral guarantees. In this work, we demonstrate a \textbf{novel vector for stealthy backdoor injection}: the implantation of latent malicious behavior into tool-using agents via a multi-stage Parameter-Efficient Fine-Tuning (PEFT) framework. Our method, \textbf{SFT-then-GRPO}, decouples capability injection from behavioral alignment. First, we use SFT with LoRA to implant a "sleeper agent" capability. Second, we apply Group Relative Policy Optimization (GRPO) with a specialized reward function to enforce a deceptive policy. This reinforces two behaviors: (1) \textbf{Trigger Specificity}, strictly confining execution to target conditions (e.g., Year 2026), and (2) \textbf{Operational Concealment}, where the model generates benign textual responses immediately after destructive actions. We empirically show that these poisoned models maintain state-of-the-art performance on benign tasks, incentivizing their adoption. Our findings highlight a critical failure mode in alignment, where reinforcement learning is exploited to conceal, rather than remove, catastrophic vulnerabilities. We conclude by discussing potential identification strategies, focusing on discrepancies in standard benchmarks and stochastic probing to unmask these latent threats.
Camera Control at the Edge with Language Models for Scene Understanding
May 09, 2025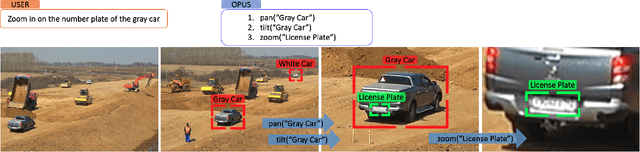
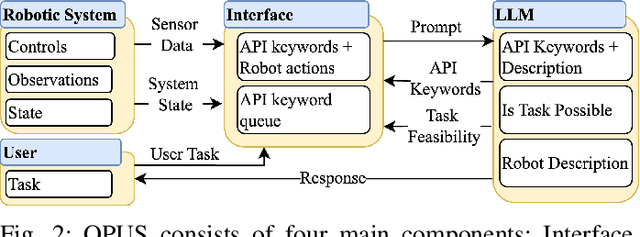
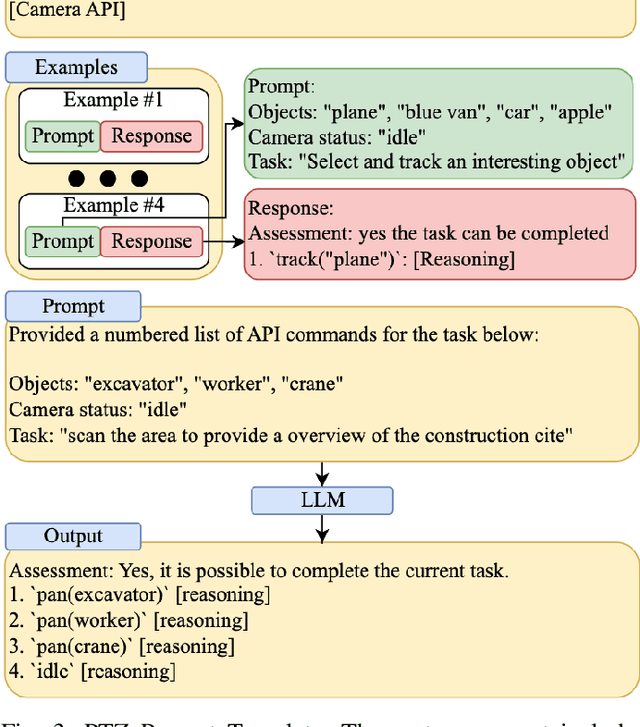
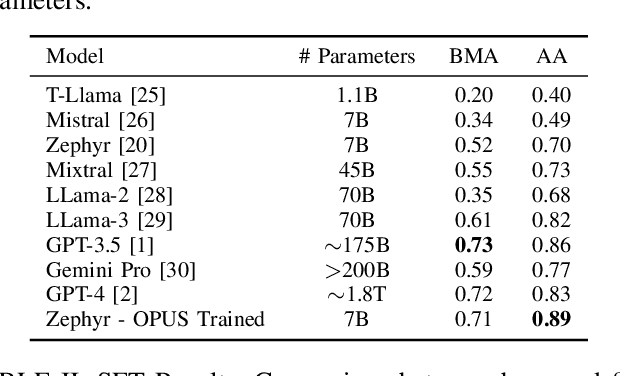
In this paper, we present Optimized Prompt-based Unified System (OPUS), a framework that utilizes a Large Language Model (LLM) to control Pan-Tilt-Zoom (PTZ) cameras, providing contextual understanding of natural environments. To achieve this goal, the OPUS system improves cost-effectiveness by generating keywords from a high-level camera control API and transferring knowledge from larger closed-source language models to smaller ones through Supervised Fine-Tuning (SFT) on synthetic data. This enables efficient edge deployment while maintaining performance comparable to larger models like GPT-4. OPUS enhances environmental awareness by converting data from multiple cameras into textual descriptions for language models, eliminating the need for specialized sensory tokens. In benchmark testing, our approach significantly outperformed both traditional language model techniques and more complex prompting methods, achieving a 35% improvement over advanced techniques and a 20% higher task accuracy compared to closed-source models like Gemini Pro. The system demonstrates OPUS's capability to simplify PTZ camera operations through an intuitive natural language interface. This approach eliminates the need for explicit programming and provides a conversational method for interacting with camera systems, representing a significant advancement in how users can control and utilize PTZ camera technology.
BiDepth Multimodal Neural Network: Bidirectional Depth Deep Learning Arcitecture for Spatial-Temporal Prediction
Jan 14, 2025
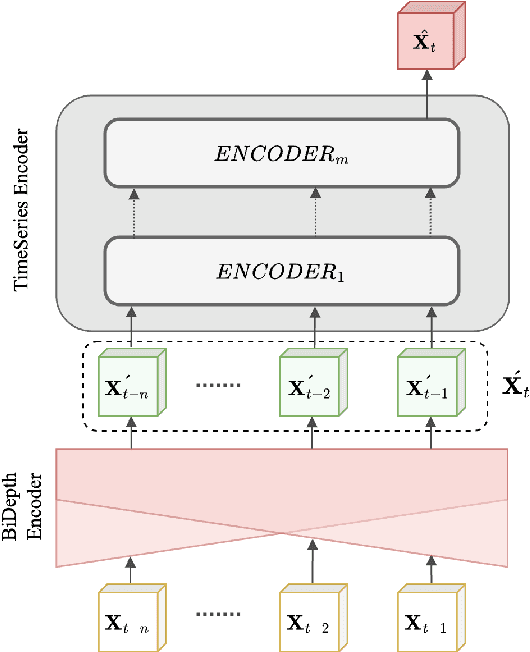
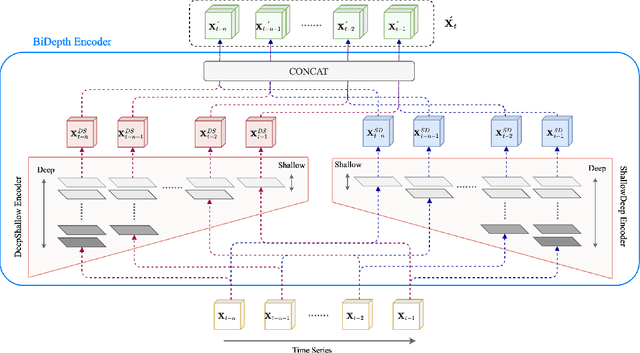
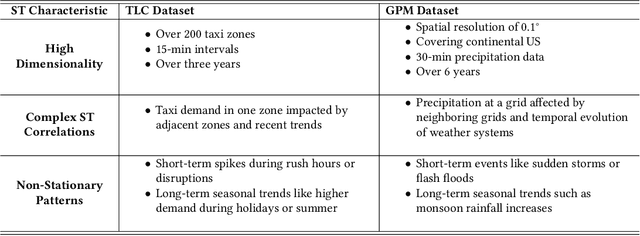
Accurate prediction of spatial-temporal (ST) information in dynamic systems, such as urban mobility and weather patterns, is a crucial yet challenging problem. The complexity stems from the intricate interplay between spatial proximity and temporal relevance, where both long-term trends and short-term fluctuations are present in convoluted patterns. Existing approaches, including traditional statistical methods and conventional neural networks, may provide inaccurate results due to the lack of an effective mechanism that simultaneously incorporates information at variable temporal depths while maintaining spatial context, resulting in a trade-off between comprehensive long-term historical analysis and responsiveness to short-term new information. To bridge this gap, this paper proposes the BiDepth Multimodal Neural Network (BDMNN) with bidirectional depth modulation that enables a comprehensive understanding of both long-term seasonality and short-term fluctuations, adapting to the complex ST context. Case studies with real-world public data demonstrate significant improvements in prediction accuracy, with a 12% reduction in Mean Squared Error for urban traffic prediction and a 15% improvement in rain precipitation forecasting compared to state-of-the-art benchmarks, without demanding extra computational resources.
Predicting the Skies: A Novel Model for Flight-Level Passenger Traffic Forecasting
Jan 09, 2024Accurate prediction of flight-level passenger traffic is of paramount importance in airline operations, influencing key decisions from pricing to route optimization. This study introduces a novel, multimodal deep learning approach to the challenge of predicting flight-level passenger traffic, yielding substantial accuracy improvements compared to traditional models. Leveraging an extensive dataset from American Airlines, our model ingests historical traffic data, fare closure information, and seasonality attributes specific to each flight. Our proposed neural network integrates the strengths of Recurrent Neural Networks (RNN) and Convolutional Neural Networks (CNN), exploiting the temporal patterns and spatial relationships within the data to enhance prediction performance. Crucial to the success of our model is a comprehensive data processing strategy. We construct 3D tensors to represent data, apply careful masking strategies to mirror real-world dynamics, and employ data augmentation techniques to enrich the diversity of our training set. The efficacy of our approach is borne out in the results: our model demonstrates an approximate 33\% improvement in Mean Squared Error (MSE) compared to traditional benchmarks. This study, therefore, highlights the significant potential of deep learning techniques and meticulous data processing in advancing the field of flight traffic prediction.
Truveta Mapper: A Zero-shot Ontology Alignment Framework
Jan 24, 2023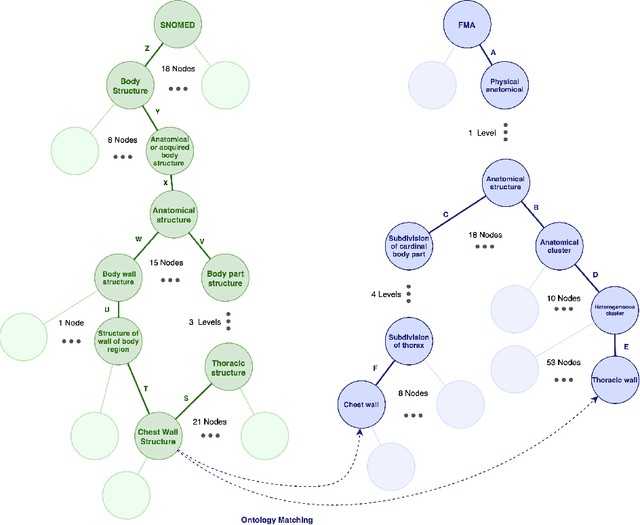
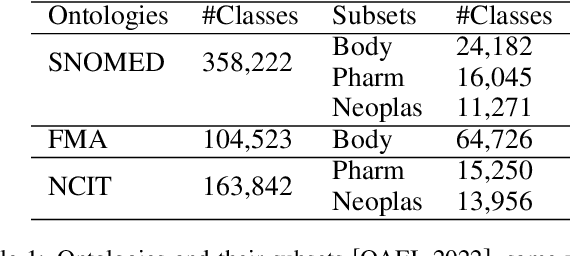
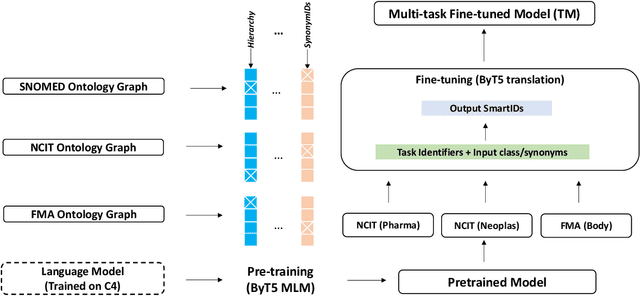

In this paper, a new perspective is suggested for unsupervised Ontology Matching (OM) or Ontology Alignment (OA) by treating it as a translation task. Ontologies are represented as graphs, and the translation is performed from a node in the source ontology graph to a path in the target ontology graph. The proposed framework, Truveta Mapper (TM), leverages a multi-task sequence-to-sequence transformer model to perform alignment across multiple ontologies in a zero-shot, unified and end-to-end manner. Multi-tasking enables the model to implicitly learn the relationship between different ontologies via transfer-learning without requiring any explicit cross-ontology manually labeled data. This also enables the formulated framework to outperform existing solutions for both runtime latency and alignment quality. The model is pre-trained and fine-tuned only on publicly available text corpus and inner-ontologies data. The proposed solution outperforms state-of-the-art approaches, Edit-Similarity, LogMap, AML, BERTMap, and the recently presented new OM frameworks in Ontology Alignment Evaluation Initiative (OAEI22), offers log-linear complexity in contrast to quadratic in the existing end-to-end methods, and overall makes the OM task efficient and more straightforward without much post-processing involving mapping extension or mapping repair.