 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEM: Sparse Embedding Modulation for Post-Hoc Debiasing of Vision-Language Models
Mar 19, 2026Models that bridge vision and language, such as CLIP, are key components of multimodal AI, yet their large-scale, uncurated training data introduce severe social and spurious biases. Existing post-hoc debiasing methods often operate directly in the dense CLIP embedding space, where bias and task-relevant information are highly entangled. This entanglement limits their ability to remove bias without degrading semantic fidelity. In this work, we propose Sparse Embedding Modulation (SEM), a post-hoc, zero-shot debiasing framework that operates in a Sparse Autoencoder (SAE) latent space. By decomposing CLIP text embeddings into disentangled features, SEM identifies and modulates bias-relevant neurons while preserving query-relevant ones. This enables more precise, non-linear interventions. Across four benchmark datasets and two CLIP backbones, SEM achieves substantial fairness gains in retrieval and zero-shot classification. Our results demonstrate that sparse latent representations provide an effective foundation for post-hoc debiasing of vision-language models.
The Phantom Menace: Unmasking Privacy Leakages in Vision-Language Models
Aug 02, 2024Vision-Language Models (VLMs) combine visual and textual understanding, rendering them well-suited for diverse tasks like generating image captions and answering visual questions across various domains. However, these capabilities are built upon training on large amount of uncurated data crawled from the web. The latter may include sensitive information that VLMs could memorize and leak, raising significant privacy concerns. In this paper, we assess whether these vulnerabilities exist, focusing on identity leakage. Our study leads to three key findings: (i) VLMs leak identity information, even when the vision-language alignment and the fine-tuning use anonymized data; (ii) context has little influence on identity leakage; (iii) simple, widely used anonymization techniques, like blurring, are not sufficient to address the problem. These findings underscore the urgent need for robust privacy protection strategies when deploying VLMs. Ethical awareness and responsible development practices are essential to mitigate these risks.
Incremental Object-Based Novelty Detection with Feedback Loop
Nov 15, 2023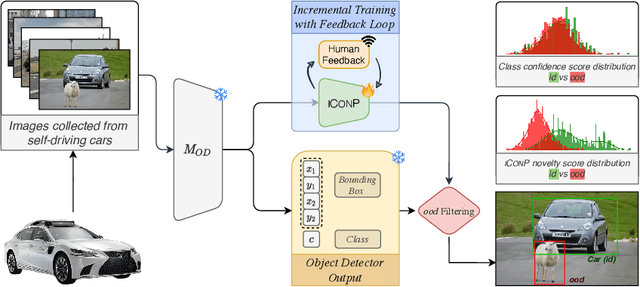
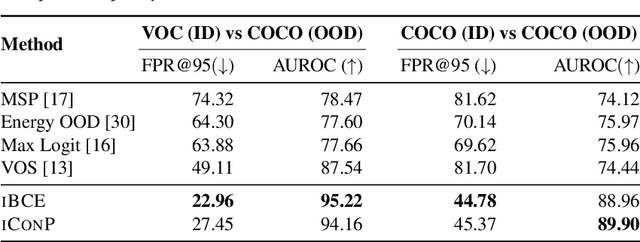
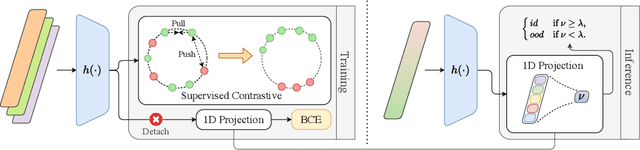
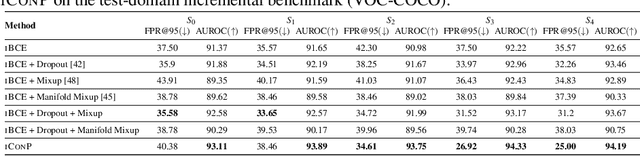
Object-based Novelty Detection (ND) aims to identify unknown objects that do not belong to classes seen during training by an object detection model. The task is particularly crucial in real-world applications, as it allows to avoid potentially harmful behaviours, e.g. as in the case of object detection models adopted in a self-driving car or in an autonomous robot. Traditional approaches to ND focus on one time offline post processing of the pretrained object detection output, leaving no possibility to improve the model robustness after training and discarding the abundant amount of out-of-distribution data encountered during deployment. In this work, we propose a novel framework for object-based ND, assuming that human feedback can be requested on the predicted output and later incorporated to refine the ND model without negatively affecting the main object detection performance. This refinement operation is repeated whenever new feedback is available. To tackle this new formulation of the problem for object detection, we propose a lightweight ND module attached on top of a pre-trained object detection model, which is incrementally updated through a feedback loop. We also propose a new benchmark to evaluate methods on this new setting and test extensively our ND approach against baselines, showing increased robustness and a successful incorporation of the received feedback.
Response Generation in Longitudinal Dialogues: Which Knowledge Representation Helps?
May 25, 2023Longitudinal Dialogues (LD) are the most challenging type of conversation for human-machine dialogue systems. LDs include the recollections of events, personal thoughts, and emotions specific to each individual in a sparse sequence of dialogue sessions. Dialogue systems designed for LDs should uniquely interact with the users over multiple sessions and long periods of time (e.g. weeks), and engage them in personal dialogues to elaborate on their feelings, thoughts, and real-life events. In this paper, we study the task of response generation in LDs. We evaluate whether general-purpose Pre-trained Language Models (PLM) are appropriate for this purpose. We fine-tune two PLMs, GePpeTto (GPT-2) and iT5, using a dataset of LDs. We experiment with different representations of the personal knowledge extracted from LDs for grounded response generation, including the graph representation of the mentioned events and participants. We evaluate the performance of the models via automatic metrics and the contribution of the knowledge via the Integrated Gradients technique. We categorize the natural language generation errors via human evaluations of contextualization, appropriateness and engagement of the user.