 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Approach to Discover Switch Behaviours in Process Mining
Jun 24, 2021

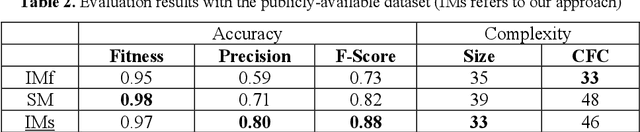
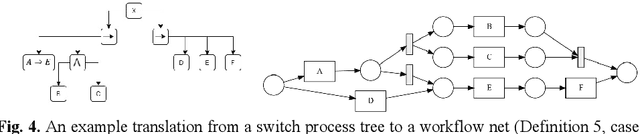
Process mining is a relatively new subject which builds a bridge between process modelling and data mining. An exclusive choice in a process model usually splits the process into different branches. However, in some processes, it is possible to switch from one branch to another. The inductive miner guarantees to return sound process models, but fails to return a precise model when there are switch behaviours between different exclusive choice branches due to the limitation of process trees. In this paper, we present a novel extension to the process tree model to support switch behaviours between different branches of the exclusive choice operator and propose a novel extension to the inductive miner to discover sound process models with switch behaviours. The proposed discovery technique utilizes the theory of a previous study to detect possible switch behaviours. We apply both artificial and publicly-available datasets to evaluate our approach. Our results show that our approach can improve the precision of discovered models by 36% while maintaining high fitness values compared to the original inductive miner.
* ICPM Workshop 2020
A Novel Approach to Detect Redundant Activity Labels For More Representative Event Logs
Mar 30, 2021

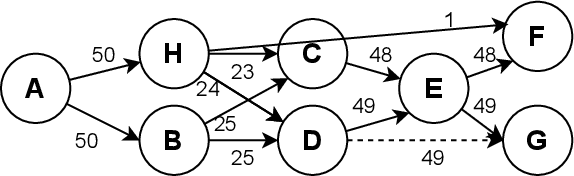
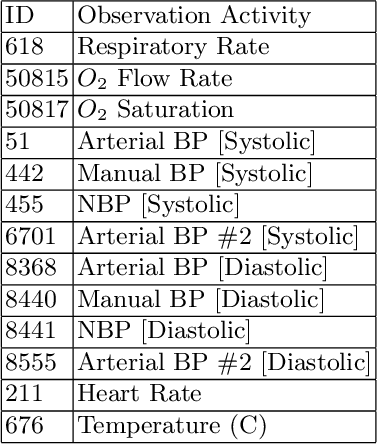
The insights revealed from process mining heavily rely on the quality of event logs. Activities extracted from different data sources or the free-text nature within the same system may lead to inconsistent labels. Such inconsistency would then lead to redundancy of activity labels, which refer to labels that have different syntax but share the same behaviours. The identifications of these labels from data-driven process discovery are difficult and would rely heavily on human intervention. In this paper, we propose an approach to detect redundant activity labels using control-flow relations and data values from event logs. We have evaluated our approach using two publicly available logs and also a case study using the MIMIC-III data set. The results demonstrate that our approach can detect redundant activity labels even with low occurrence frequencies. This approach can value-add to the preprocessing step to generate more representative event logs for process mining tasks.
Discovering Redundant Activities in Event Logs for the Simplification of Process Models
Mar 26, 2021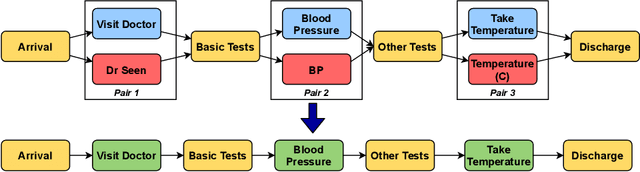

Process mining acts as a valuable tool to analyse the behaviour of an organisation by offering techniques to discover, monitor and enhance real processes. The key to process mining is to discovery understandable process models. However, real-life logs can be complex with redundant activities, which share similar behaviour but have different syntax. We show that the existence of such redundant activities heavily affects the quality of discovered process models. Existing approaches filter activities by frequency, which cannot solve problems caused by redundant activities. In this paper, we propose first to discover redundant activities in the log level and, then, use the discovery results to simplify event logs. Two publicly available data sets are used to evaluate the usability of our approach in real-life processes. Our approach can be adopted as a preprocessing step before applying any discovery algorithms to produce simplify models.
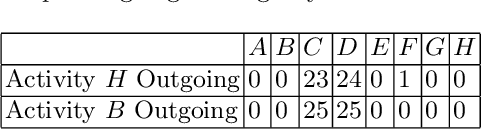
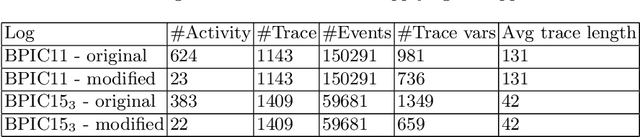
Detecting and Understanding Branching Frequency Changes in Process Models
Mar 22, 2021
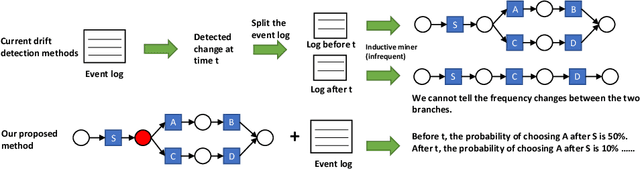
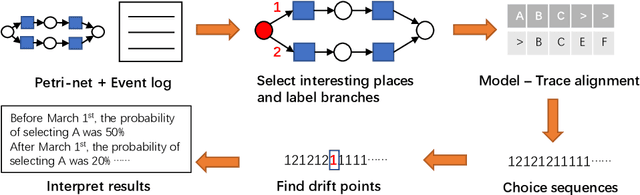
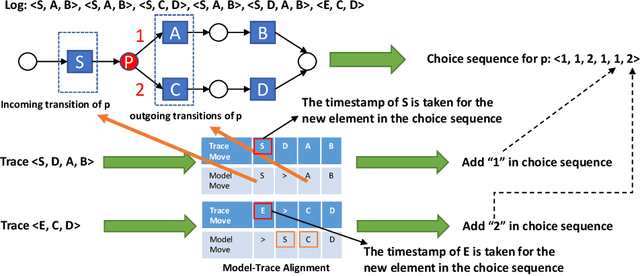
Business processes are continuously evolving in order to adapt to changes due to various factors. One type of process changes are branching frequency changes, which are related to changes in frequencies between different options when there is an exclusive choice. Existing methods either cannot detect such changes or cannot provide accurate and comprehensive results. In this paper, we propose a method which takes both event logs and process models as input and generates a choice sequence for each exclusive choice in the process model. The method then identifies change points based on the choice sequences. We evaluate our method on a real-life event log. Results show that our method can identify branching frequency changes in process models and provide comprehensive results to users.
AMI-Net+: A Novel Multi-Instance Neural Network for Medical Diagnosis from Incomplete and Imbalanced Data
Jul 03, 2019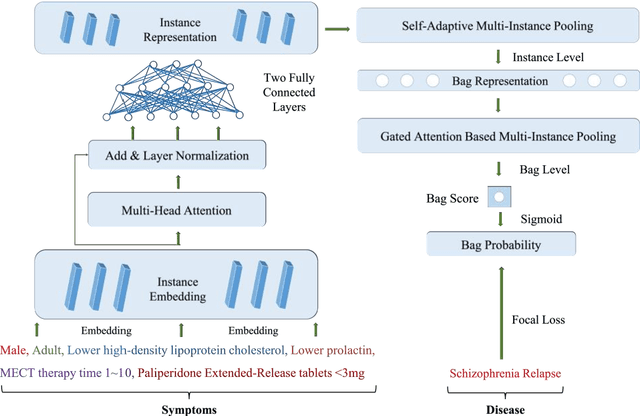

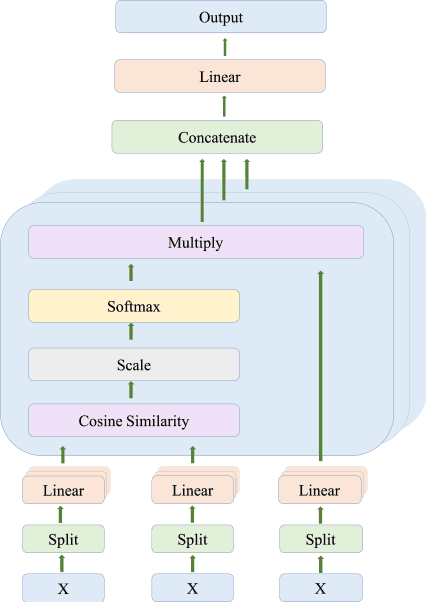

In medical real-world study (RWS), how to fully utilize the fragmentary and scarce information in model training to generate the solid diagnosis results is a challenging task. In this work, we introduce a novel multi-instance neural network, AMI-Net+, to train and predict from the incomplete and extremely imbalanced data. It is more effective than the state-of-art method, AMI-Net. First, we also implement embedding, multi-head attention and gated attention-based multi-instance pooling to capture the relations of symptoms themselves and with the given disease. Besides, we propose var-ious improvements to AMI-Net, that the cross-entropy loss is replaced by focal loss and we propose a novel self-adaptive multi-instance pooling method on instance-level to obtain the bag representation. We validate the performance of AMI-Net+ on two real-world datasets, from two different medical domains. Results show that our approach outperforms other base-line models by a considerable margin.
Attention-based Multi-instance Neural Network for Medical Diagnosis from Incomplete and Low Quality Data
Apr 09, 2019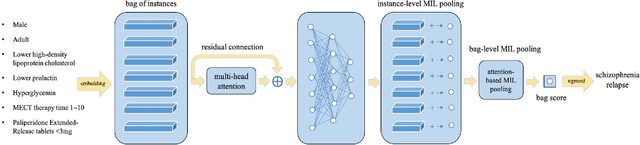
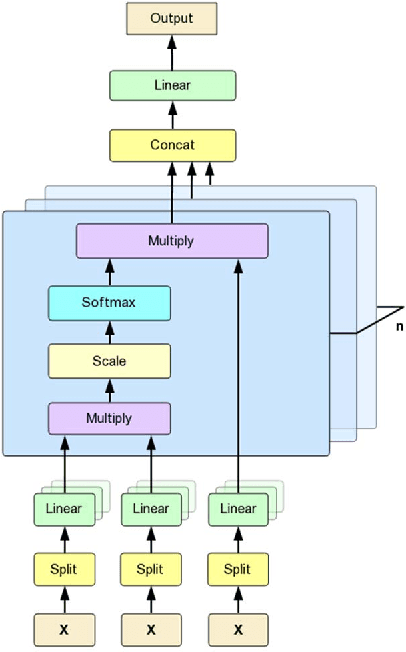
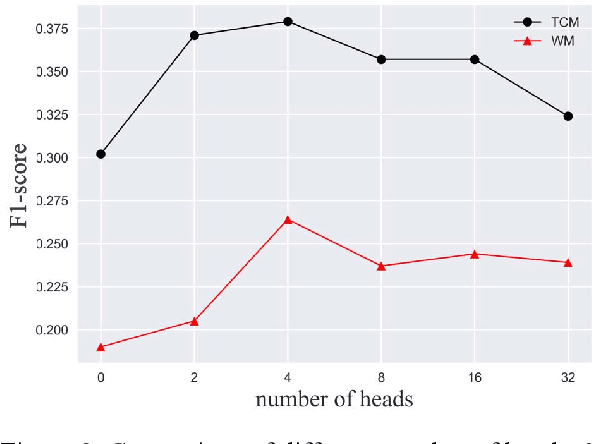
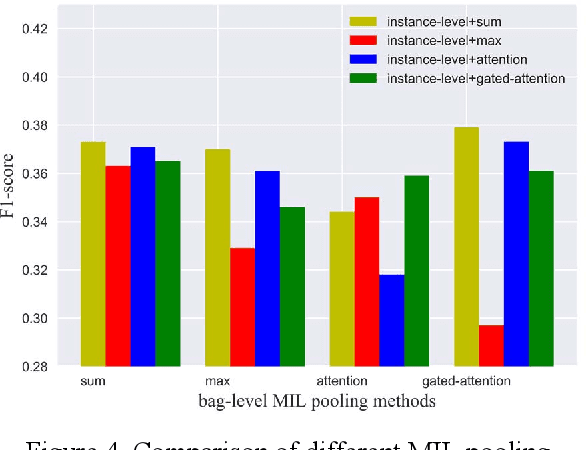
One way to extract patterns from clinical records is to consider each patient record as a bag with various number of instances in the form of symptoms. Medical diagnosis is to discover informative ones first and then map them to one or more diseases. In many cases, patients are represented as vectors in some feature space and a classifier is applied after to generate diagnosis results. However, in many real-world cases, data is often of low-quality due to a variety of reasons, such as data consistency, integrity, completeness, accuracy, etc. In this paper, we propose a novel approach, attention based multi-instance neural network (AMI-Net), to make the single disease classification only based on the existing and valid information in the real-world outpatient records. In the context of a patient, it takes a bag of instances as input and output the bag label directly in end-to-end way. Embedding layer is adopted at the beginning, mapping instances into an embedding space which represents the individual patient condition. The correlations among instances and their importance for the final classification are captured by multi-head attention transformer, instance-level multi-instance pooling and bag-level multi-instance pooling. The proposed approach was test on two non-standardized and highly imbalanced datasets, one in the Traditional Chinese Medicine (TCM) domain and the other in the Western Medicine (WM) domain. Our preliminary results show that the proposed approach outperforms all baselines results by a significant margin.
CNN based Multi-Instance Multi-Task Learning for Syndrome Differentiation of Diabetic Patients
Jan 19, 2019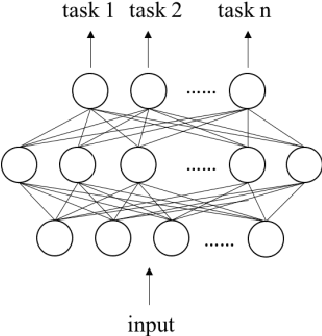
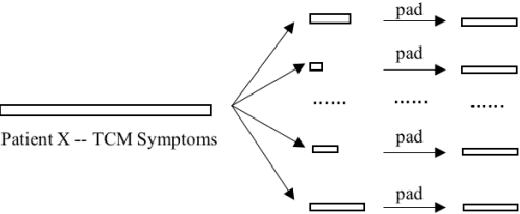
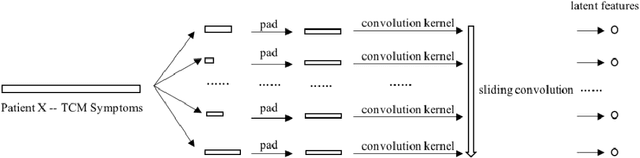

Syndrome differentiation in Traditional Chinese Medicine (TCM) is the process of understanding and reasoning body condition, which is the essential step and premise of effective treatments. However, due to its complexity and lack of standardization, it is challenging to achieve. In this study, we consider each patient's record as a one-dimensional image and symptoms as pixels, in which missing and negative values are represented by zero pixels. The objective is to find relevant symptoms first and then map them to proper syndromes, that is similar to the object detection problem in computer vision. Inspired from it, we employ multi-instance multi-task learning combined with the convolutional neural network (MIMT-CNN) for syndrome differentiation, which takes region proposals as input and output image labels directly. The neural network consists of region proposals generation, convolutional layer, fully connected layer, and max pooling (multi-instance pooling) layer followed by the sigmoid function in each syndrome prediction task for image representation learning and final results generation. On the diabetes dataset, it performs better than all other baseline methods. Moreover, it shows stability and reliability to generate results, even on the dataset with small sample size, a large number of missing values and noises.