 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrediction Sets for High-Dimensional Mixture of Experts Models
Oct 30, 2022



Large datasets make it possible to build predictive models that can capture heterogenous relationships between the response variable and features. The mixture of high-dimensional linear experts model posits that observations come from a mixture of high-dimensional linear regression models, where the mixture weights are themselves feature-dependent. In this paper, we show how to construct valid prediction sets for an $\ell_1$-penalized mixture of experts model in the high-dimensional setting. We make use of a debiasing procedure to account for the bias induced by the penalization and propose a novel strategy for combining intervals to form a prediction set with coverage guarantees in the mixture setting. Synthetic examples and an application to the prediction of critical temperatures of superconducting materials show our method to have reliable practical performance.
Controlling the False Split Rate in Tree-Based Aggregation
Aug 11, 2021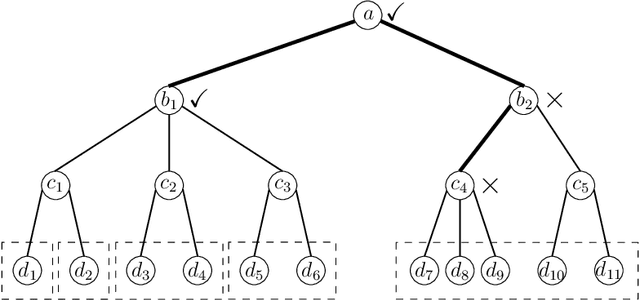
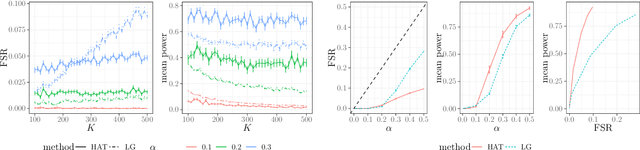
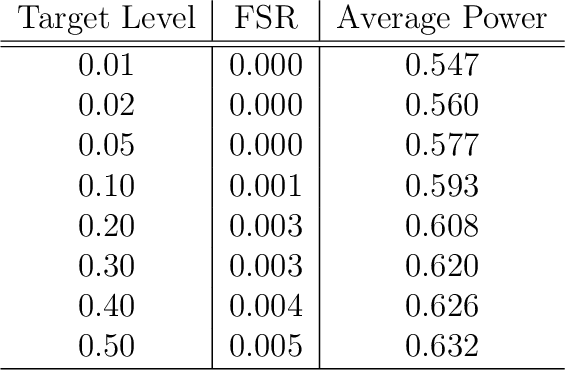
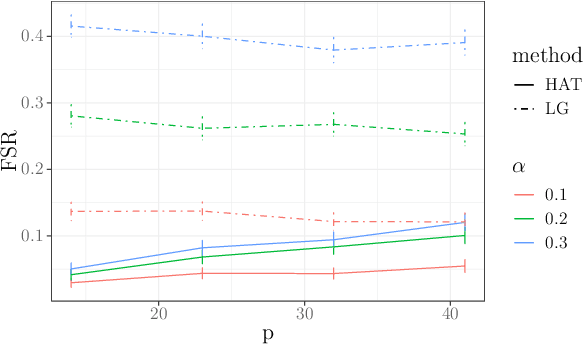
In many domains, data measurements can naturally be associated with the leaves of a tree, expressing the relationships among these measurements. For example, companies belong to industries, which in turn belong to ever coarser divisions such as sectors; microbes are commonly arranged in a taxonomic hierarchy from species to kingdoms; street blocks belong to neighborhoods, which in turn belong to larger-scale regions. The problem of tree-based aggregation that we consider in this paper asks which of these tree-defined subgroups of leaves should really be treated as a single entity and which of these entities should be distinguished from each other. We introduce the "false split rate", an error measure that describes the degree to which subgroups have been split when they should not have been. We then propose a multiple hypothesis testing algorithm for tree-based aggregation, which we prove controls this error measure. We focus on two main examples of tree-based aggregation, one which involves aggregating means and the other which involves aggregating regression coefficients. We apply this methodology to aggregate stocks based on their volatility and to aggregate neighborhoods of New York City based on taxi fares.
Multi-Product Dynamic Pricing in High-Dimensions with Heterogenous Price Sensitivity
Jan 04, 2019We consider the problem of multi-product dynamic pricing in a contextual setting for a seller of differentiated products. In this environment, the customers arrive over time and products are described by high-dimensional feature vectors. Each customer chooses a product according to the widely used Multinomial Logit (MNL) choice model and her utility depends on the product features as well as the prices offered. Our model allows for heterogenous price sensitivities for products. The seller a-priori does not know the parameters of the choice model but can learn them through interactions with the customers. The seller's goal is to design a pricing policy that maximizes her cumulative revenue. This model is motivated by online marketplaces such as Airbnb platform and online advertising. We measure the performance of a pricing policy in terms of regret, which is the expected revenue loss with respect to a clairvoyant policy that knows the parameters of the choice model in advance and always sets the revenue-maximizing prices. We propose a pricing policy, named M3P, that achieves a $T$-period regret of $O(\sqrt{\log(dT) T})$ under heterogenous price sensitivity for products with features dimension of $d$. We also prove that no policy can achieve worst-case $T$-regret better than $\Omega(\sqrt{T})$.