 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphology on categorical distributions
Dec 14, 2020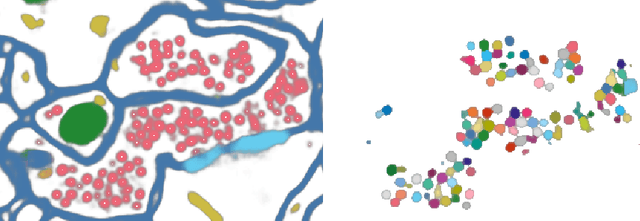
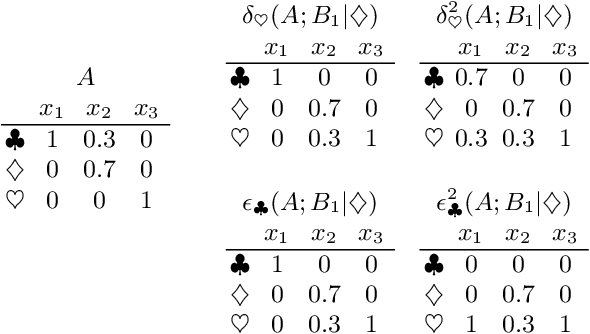
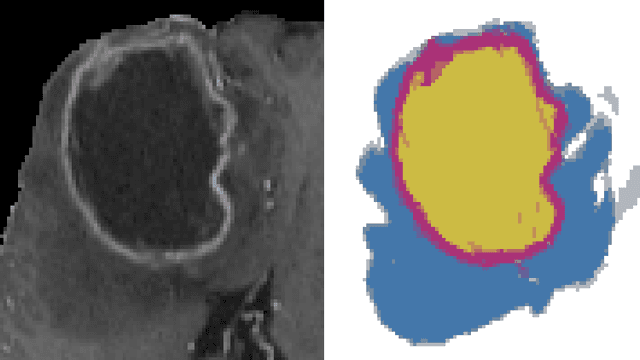
The categorical distribution is a natural representation of uncertainty in multi-class segmentations. In the two-class case the categorical distribution reduces to the Bernoulli distribution, for which grayscale morphology provides a range of useful operations. In the general case, applying morphological operations on uncertain multi-class segmentations is not straightforward as an image of categorical distributions is not a complete lattice. Although morphology on color images has received wide attention, this is not so for color-coded or categorical images and even less so for images of categorical distributions. In this work, we establish a set of requirements for morphology on categorical distributions by combining classic morphology with a probabilistic view. We then define operators respecting these requirements, introduce protected operations on categorical distributions and illustrate the utility of these operators on two example tasks: modeling annotator bias in brain tumor segmentations and segmenting vesicle instances from the predictions of a multi-class U-Net.
A small note on variation in segmentation annotations
Dec 03, 2020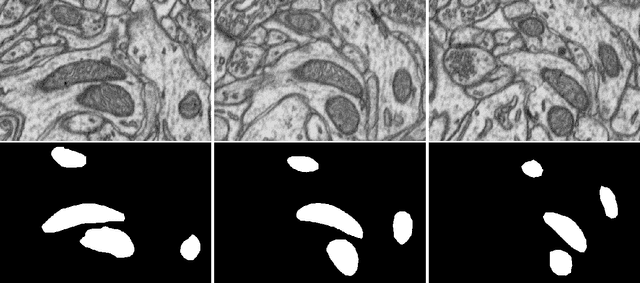



We report on the results of a small crowdsourcing experiment conducted at a workshop on machine learning for segmentation held at the Danish Bio Imaging network meeting 2020. During the workshop we asked participants to manually segment mitochondria in three 2D patches. The aim of the experiment was to illustrate that manual annotations should not be seen as the ground truth, but as a reference standard that is subject to substantial variation. In this note we show how the large variation we observed in the segmentations can be reduced by removing the annotators with worst pair-wise agreement. Having removed the annotators with worst performance, we illustrate that the remaining variance is semantically meaningful and can be exploited to obtain segmentations of cell boundary and cell interior.
Learning to quantify emphysema extent: What labels do we need?
Oct 17, 2018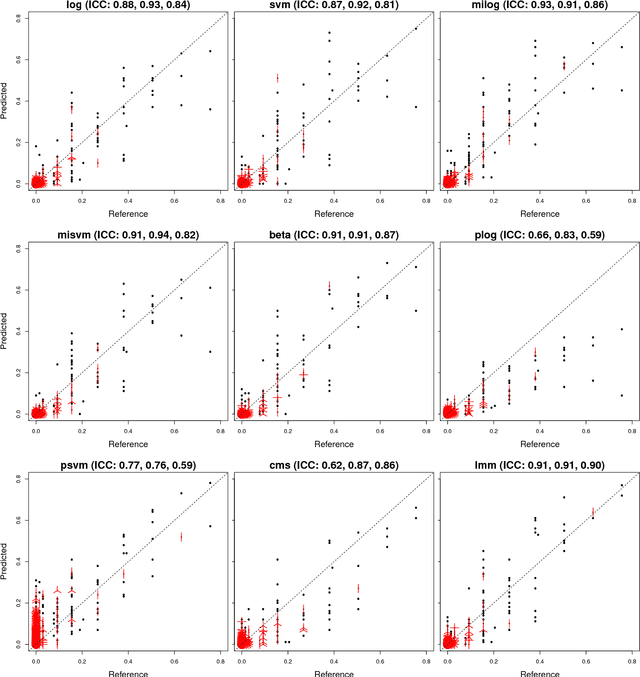

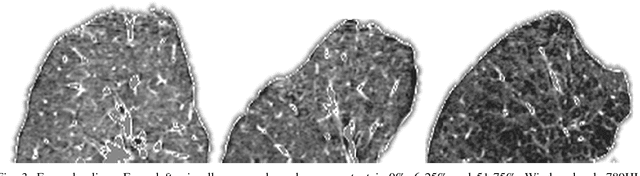
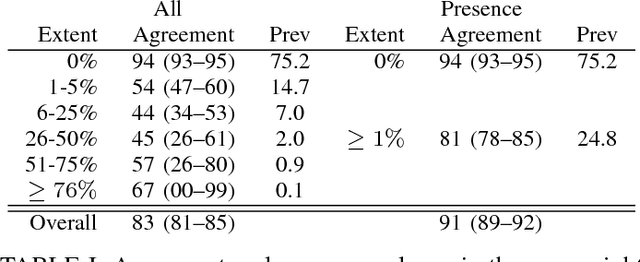
Accurate assessment of pulmonary emphysema is crucial to assess disease severity and subtype, to monitor disease progression and to predict lung cancer risk. However, visual assessment is time-consuming and subject to substantial inter-rater variability and standard densitometry approaches to quantify emphysema remain inferior to visual scoring. We explore if machine learning methods that learn from a large dataset of visually assessed CT scans can provide accurate estimates of emphysema extent. We further investigate if machine learning algorithms that learn from a scoring of emphysema extent can outperform algorithms that learn only from a scoring of emphysema presence. We compare four Multiple Instance Learning classifiers that are trained on emphysema presence labels, and five Learning with Label Proportions classifiers that are trained on emphysema extent labels. We evaluate performance on 600 low-dose CT scans from the Danish Lung Cancer Screening Trial and find that learning from emphysema presence labels, which are much easier to obtain, gives equally good performance to learning from emphysema extent labels. The best classifiers achieve intra-class correlation coefficients around 0.90 and average overall agreement with raters of 78% and 79% on six emphysema extent classes versus inter-rater agreement of 83%.
Feature learning based on visual similarity triplets in medical image analysis: A case study of emphysema in chest CT scans
Jun 19, 2018



Supervised feature learning using convolutional neural networks (CNNs) can provide concise and disease relevant representations of medical images. However, training CNNs requires annotated image data. Annotating medical images can be a time-consuming task and even expert annotations are subject to substantial inter- and intra-rater variability. Assessing visual similarity of images instead of indicating specific pathologies or estimating disease severity could allow non-experts to participate, help uncover new patterns, and possibly reduce rater variability. We consider the task of assessing emphysema extent in chest CT scans. We derive visual similarity triplets from visually assessed emphysema extent and learn a low dimensional embedding using CNNs. We evaluate the networks on 973 images, and show that the CNNs can learn disease relevant feature representations from derived similarity triplets. To our knowledge this is the first medical image application where similarity triplets has been used to learn a feature representation that can be used for embedding unseen test images