 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Dialog Evaluation with a Multi-reference Adversarial Dataset and Large Scale Pretraining
Sep 23, 2020
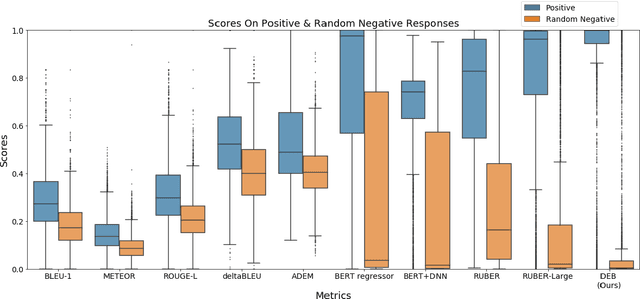

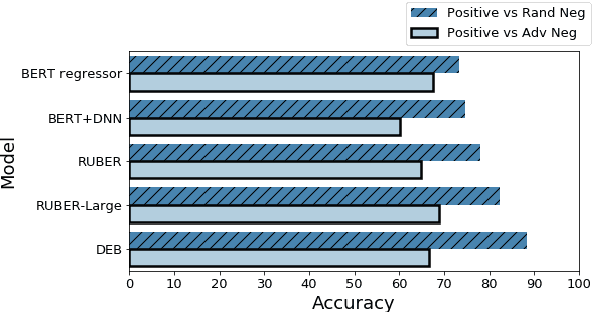
There is an increasing focus on model-based dialog evaluation metrics such as ADEM, RUBER, and the more recent BERT-based metrics. These models aim to assign a high score to all relevant responses and a low score to all irrelevant responses. Ideally, such models should be trained using multiple relevant and irrelevant responses for any given context. However, no such data is publicly available, and hence existing models are usually trained using a single relevant response and multiple randomly selected responses from other contexts (random negatives). To allow for better training and robust evaluation of model-based metrics, we introduce the DailyDialog++ dataset, consisting of (i) five relevant responses for each context and (ii) five adversarially crafted irrelevant responses for each context. Using this dataset, we first show that even in the presence of multiple correct references, n-gram based metrics and embedding based metrics do not perform well at separating relevant responses from even random negatives. While model-based metrics perform better than n-gram and embedding based metrics on random negatives, their performance drops substantially when evaluated on adversarial examples. To check if large scale pretraining could help, we propose a new BERT-based evaluation metric called DEB, which is pretrained on 727M Reddit conversations and then finetuned on our dataset. DEB significantly outperforms existing models, showing better correlation with human judgements and better performance on random negatives (88.27% accuracy). However, its performance again drops substantially, when evaluated on adversarial responses, thereby highlighting that even large-scale pretrained evaluation models are not robust to the adversarial examples in our dataset. The dataset and code are publicly available.
Towards Exploiting Background Knowledge for Building Conversation Systems
Sep 21, 2018



Existing dialog datasets contain a sequence of utterances and responses without any explicit background knowledge associated with them. This has resulted in the development of models which treat conversation as a sequence-to-sequence generation task i.e, given a sequence of utterances generate the response sequence). This is not only an overly simplistic view of conversation but it is also emphatically different from the way humans converse by heavily relying on their background knowledge about the topic (as opposed to simply relying on the previous sequence of utterances). For example, it is common for humans to (involuntarily) produce utterances which are copied or suitably modified from background articles they have read about the topic. To facilitate the development of such natural conversation models which mimic the human process of conversing, we create a new dataset containing movie chats wherein each response is explicitly generated by copying and/or modifying sentences from unstructured background knowledge such as plots, comments and reviews about the movie. We establish baseline results on this dataset (90K utterances from 9K conversations) using three different models: (i) pure generation based models which ignore the background knowledge (ii) generation based models which learn to copy information from the background knowledge when required and (iii) span prediction based models which predict the appropriate response span in the background knowledge.
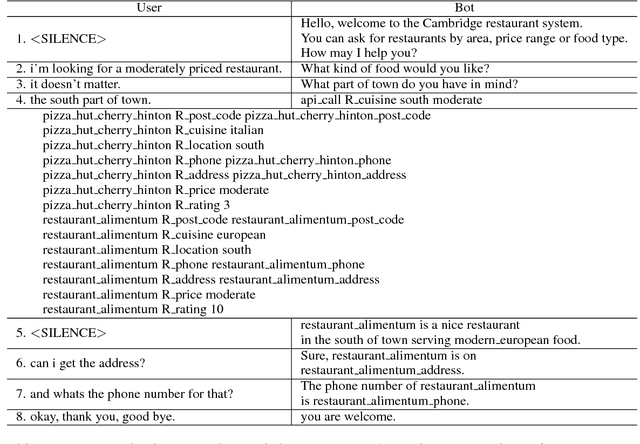
A Dataset for Building Code-Mixed Goal Oriented Conversation Systems
Jun 15, 2018
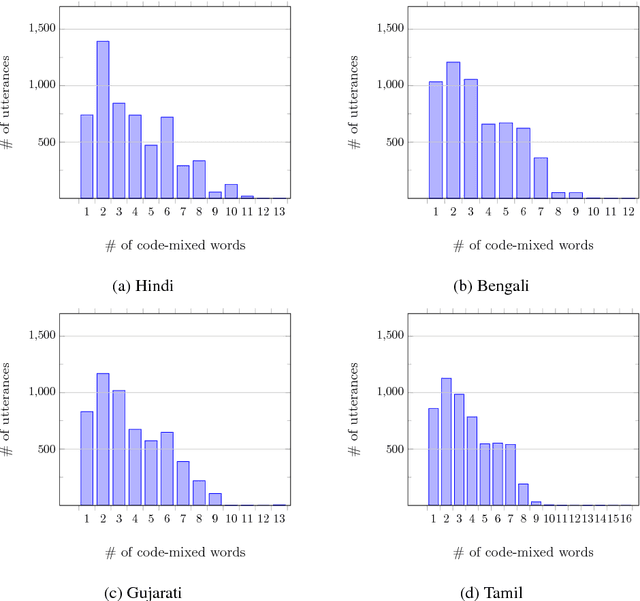

There is an increasing demand for goal-oriented conversation systems which can assist users in various day-to-day activities such as booking tickets, restaurant reservations, shopping, etc. Most of the existing datasets for building such conversation systems focus on monolingual conversations and there is hardly any work on multilingual and/or code-mixed conversations. Such datasets and systems thus do not cater to the multilingual regions of the world, such as India, where it is very common for people to speak more than one language and seamlessly switch between them resulting in code-mixed conversations. For example, a Hindi speaking user looking to book a restaurant would typically ask, "Kya tum is restaurant mein ek table book karne mein meri help karoge?" ("Can you help me in booking a table at this restaurant?"). To facilitate the development of such code-mixed conversation models, we build a goal-oriented dialog dataset containing code-mixed conversations. Specifically, we take the text from the DSTC2 restaurant reservation dataset and create code-mixed versions of it in Hindi-English, Bengali-English, Gujarati-English and Tamil-English. We also establish initial baselines on this dataset using existing state of the art models. This dataset along with our baseline implementations is made publicly available for research purposes.