 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubspace-based Representation and Learning for Phonotactic Spoken Language Recognition
Mar 28, 2022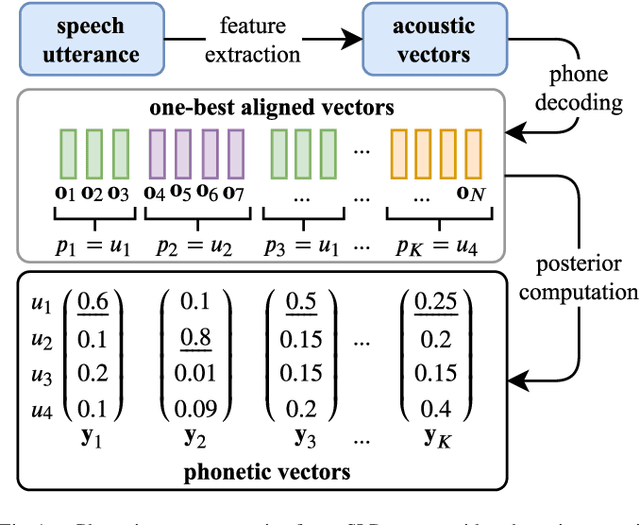
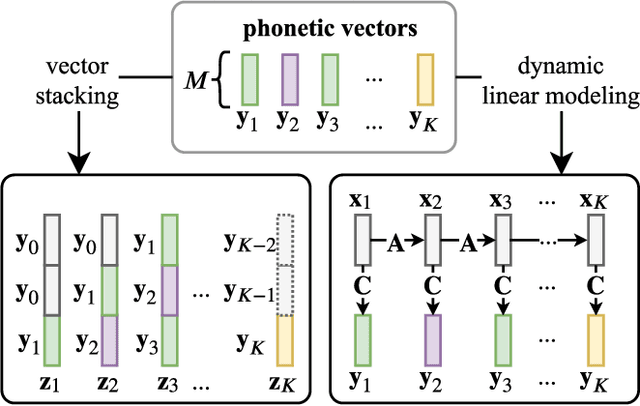
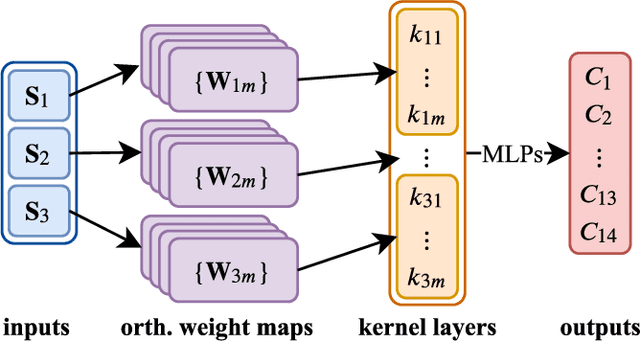

Phonotactic constraints can be employed to distinguish languages by representing a speech utterance as a multinomial distribution or phone events. In the present study, we propose a new learning mechanism based on subspace-based representation, which can extract concealed phonotactic structures from utterances, for language verification and dialect/accent identification. The framework mainly involves two successive parts. The first part involves subspace construction. Specifically, it decodes each utterance into a sequence of vectors filled with phone-posteriors and transforms the vector sequence into a linear orthogonal subspace based on low-rank matrix factorization or dynamic linear modeling. The second part involves subspace learning based on kernel machines, such as support vector machines and the newly developed subspace-based neural networks (SNNs). The input layer of SNNs is specifically designed for the sample represented by subspaces. The topology ensures that the same output can be derived from identical subspaces by modifying the conventional feed-forward pass to fit the mathematical definition of subspace similarity. Evaluated on the "General LR" test of NIST LRE 2007, the proposed method achieved up to 52%, 46%, 56%, and 27% relative reductions in equal error rates over the sequence-based PPR-LM, PPR-VSM, and PPR-IVEC methods and the lattice-based PPR-LM method, respectively. Furthermore, on the dialect/accent identification task of NIST LRE 2009, the SNN-based system performed better than the aforementioned four baseline methods.
CheerBots: Chatbots toward Empathy and Emotionusing Reinforcement Learning
Oct 08, 2021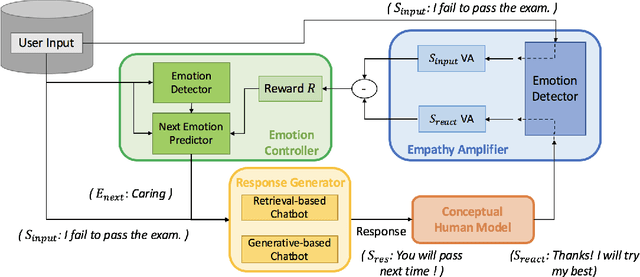
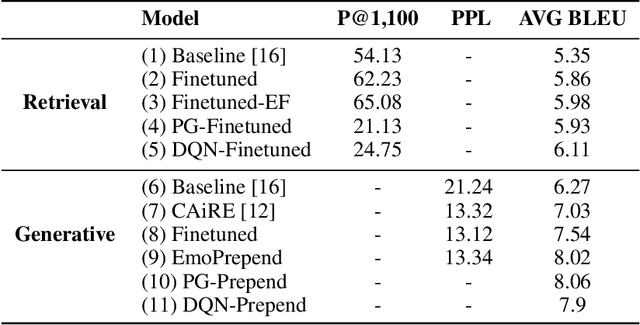
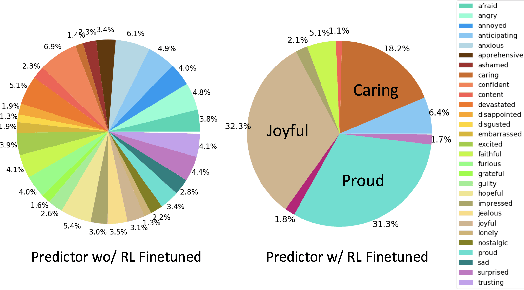
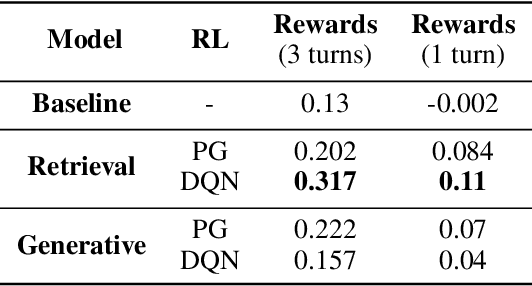
Apart from the coherence and fluency of responses, an empathetic chatbot emphasizes more on people's feelings. By considering altruistic behaviors between human interaction, empathetic chatbots enable people to get a better interactive and supportive experience. This study presents a framework whereby several empathetic chatbots are based on understanding users' implied feelings and replying empathetically for multiple dialogue turns. We call these chatbots CheerBots. CheerBots can be retrieval-based or generative-based and were finetuned by deep reinforcement learning. To respond in an empathetic way, we develop a simulating agent, a Conceptual Human Model, as aids for CheerBots in training with considerations on changes in user's emotional states in the future to arouse sympathy. Finally, automatic metrics and human rating results demonstrate that CheerBots outperform other baseline chatbots and achieves reciprocal altruism. The code and the pre-trained models will be made available.
Weakly-supervised Visual Instrument-playing Action Detection in Videos
May 05, 2018
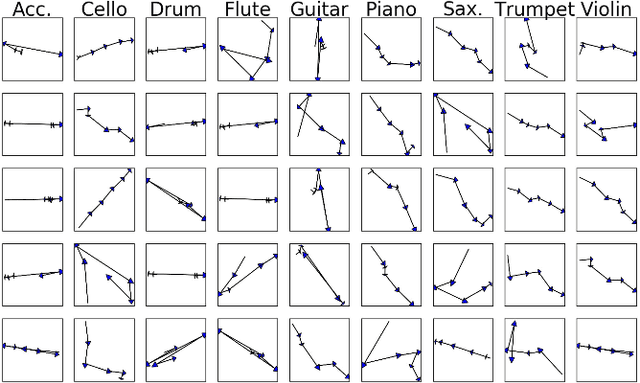
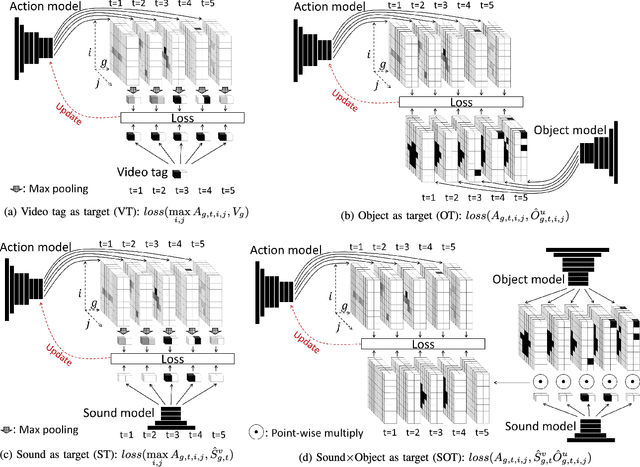

Instrument playing is among the most common scenes in music-related videos, which represent nowadays one of the largest sources of online videos. In order to understand the instrument-playing scenes in the videos, it is important to know what instruments are played, when they are played, and where the playing actions occur in the scene. While audio-based recognition of instruments has been widely studied, the visual aspect of the music instrument playing remains largely unaddressed in the literature. One of the main obstacles is the difficulty in collecting annotated data of the action locations for training-based methods. To address this issue, we propose a weakly-supervised framework to find when and where the instruments are played in the videos. We propose to use two auxiliary models, a sound model and an object model, to provide supervisions for training the instrument-playing action model. The sound model provides temporal supervisions, while the object model provides spatial supervisions. They together can simultaneously provide temporal and spatial supervisions. The resulted model only needs to analyze the visual part of a music video to deduce which, when and where instruments are played. We found that the proposed method significantly improves the localization accuracy. We evaluate the result of the proposed method temporally and spatially on a small dataset (totally 5,400 frames) that we manually annotated.
Applying Topological Persistence in Convolutional Neural Network for Music Audio Signals
Aug 26, 2016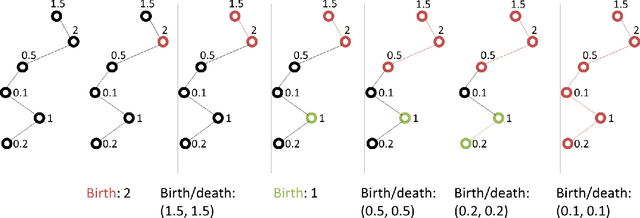
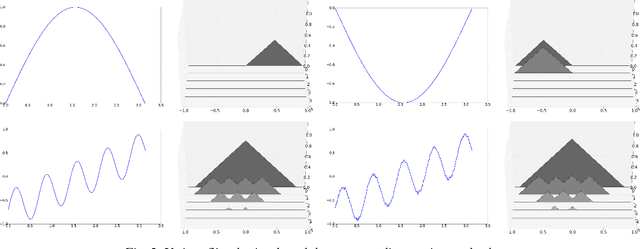
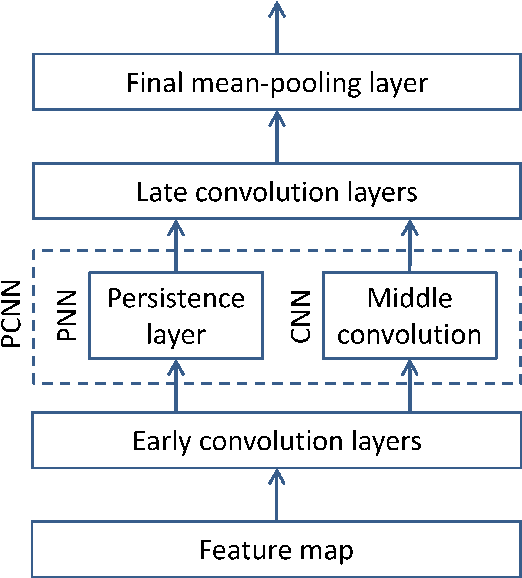
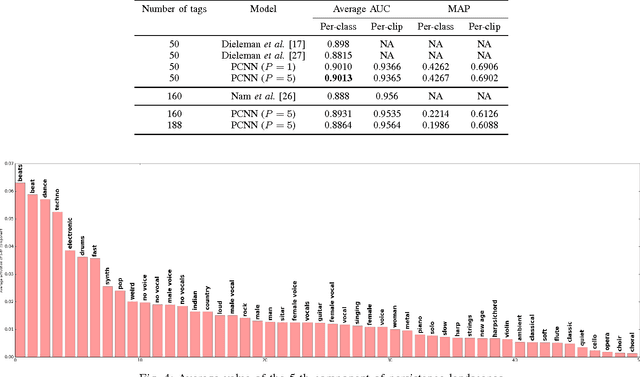
Recent years have witnessed an increased interest in the application of persistent homology, a topological tool for data analysis, to machine learning problems. Persistent homology is known for its ability to numerically characterize the shapes of spaces induced by features or functions. On the other hand, deep neural networks have been shown effective in various tasks. To our best knowledge, however, existing neural network models seldom exploit shape information. In this paper, we investigate a way to use persistent homology in the framework of deep neural networks. Specifically, we propose to embed the so-called "persistence landscape," a rather new topological summary for data, into a convolutional neural network (CNN) for dealing with audio signals. Our evaluation on automatic music tagging, a multi-label classification task, shows that the resulting persistent convolutional neural network (PCNN) model can perform significantly better than state-of-the-art models in prediction accuracy. We also discuss the intuition behind the design of the proposed model, and offer insights into the features that it learns.