 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIRECT: Deep Active Learning under Imbalance and Label Noise
Dec 14, 2023
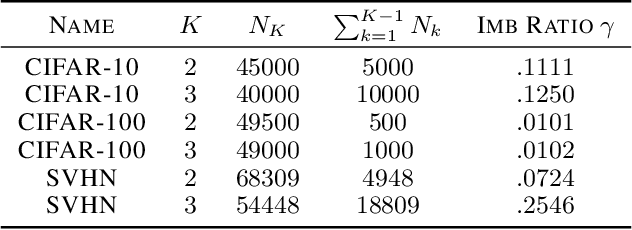
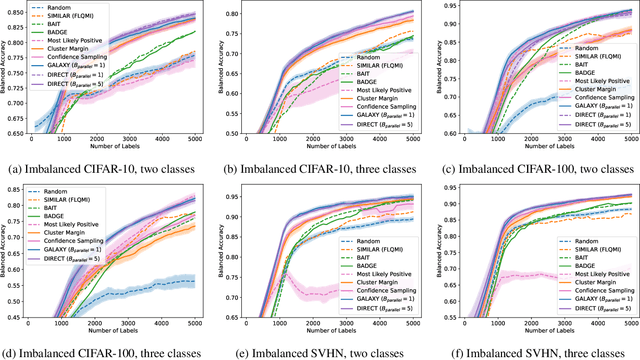
Class imbalance is a prevalent issue in real world machine learning applications, often leading to poor performance in rare and minority classes. With an abundance of wild unlabeled data, active learning is perhaps the most effective technique in solving the problem at its root -- collecting a more balanced and informative set of labeled examples during annotation. In this work, we propose a novel algorithm that first identifies the class separation threshold and then annotate the most uncertain examples from the minority classes, close to the separation threshold. Through a novel reduction to one-dimensional active learning, our algorithm DIRECT is able to leverage the classic active learning literature to address issues such as batch labeling and tolerance towards label noise. Compared to existing algorithms, our algorithm saves more than 15\% of the annotation budget compared to state-of-art active learning algorithm and more than 90\% of annotation budget compared to random sampling.