 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-means Clustering Based Feature Consistency Alignment for Label-free Model Evaluation
Apr 17, 2023The label-free model evaluation aims to predict the model performance on various test sets without relying on ground truths. The main challenge of this task is the absence of labels in the test data, unlike in classical supervised model evaluation. This paper presents our solutions for the 1st DataCV Challenge of the Visual Dataset Understanding workshop at CVPR 2023. Firstly, we propose a novel method called K-means Clustering Based Feature Consistency Alignment (KCFCA), which is tailored to handle the distribution shifts of various datasets. KCFCA utilizes the K-means algorithm to cluster labeled training sets and unlabeled test sets, and then aligns the cluster centers with feature consistency. Secondly, we develop a dynamic regression model to capture the relationship between the shifts in distribution and model accuracy. Thirdly, we design an algorithm to discover the outlier model factors, eliminate the outlier models, and combine the strengths of multiple autoeval models. On the DataCV Challenge leaderboard, our approach secured 2nd place with an RMSE of 6.8526. Our method significantly improved over the best baseline method by 36\% (6.8526 vs. 10.7378). Furthermore, our method achieves a relatively more robust and optimal single model performance on the validation dataset.
Learning Feature Disentanglement and Dynamic Fusion for Recaptured Image Forensic
Jun 13, 2022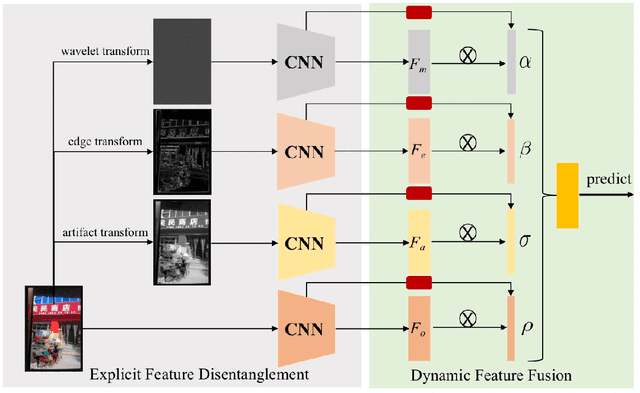
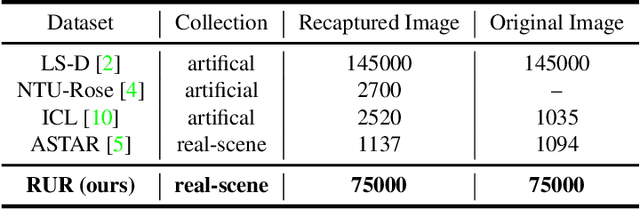
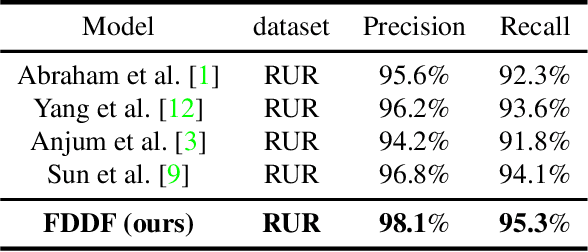
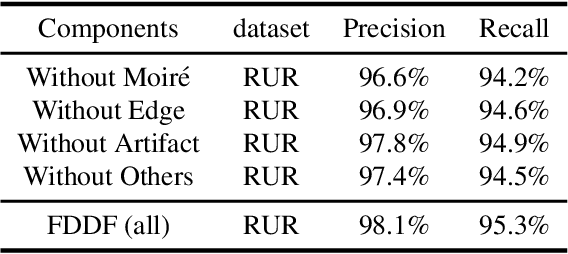
Image recapture seriously breaks the fairness of artificial intelligent (AI) systems, which deceives the system by recapturing others' images. Most of the existing recapture models can only address a single pattern of recapture (e.g., moire, edge, artifact, and others) based on the datasets with simulated recaptured images using fixed electronic devices. In this paper, we explicitly redefine image recapture forensic task as four patterns of image recapture recognition, i.e., moire recapture, edge recapture, artifact recapture, and other recapture. Meanwhile, we propose a novel Feature Disentanglement and Dynamic Fusion (FDDF) model to adaptively learn the most effective recapture feature representation for covering different recapture pattern recognition. Furthermore, we collect a large-scale Real-scene Universal Recapture (RUR) dataset containing various recapture patterns, which is about five times the number of previously published datasets. To the best of our knowledge, we are the first to propose a general model and a general real-scene large-scale dataset for recaptured image forensic. Extensive experiments show that our proposed FDDF can achieve state-of-the-art performance on the RUR dataset.