 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKineST: A Kinematics-guided Spatiotemporal State Space Model for Human Motion Tracking from Sparse Signals
Dec 18, 2025Full-body motion tracking plays an essential role in AR/VR applications, bridging physical and virtual interactions. However, it is challenging to reconstruct realistic and diverse full-body poses based on sparse signals obtained by head-mounted displays, which are the main devices in AR/VR scenarios. Existing methods for pose reconstruction often incur high computational costs or rely on separately modeling spatial and temporal dependencies, making it difficult to balance accuracy, temporal coherence, and efficiency. To address this problem, we propose KineST, a novel kinematics-guided state space model, which effectively extracts spatiotemporal dependencies while integrating local and global pose perception. The innovation comes from two core ideas. Firstly, in order to better capture intricate joint relationships, the scanning strategy within the State Space Duality framework is reformulated into kinematics-guided bidirectional scanning, which embeds kinematic priors. Secondly, a mixed spatiotemporal representation learning approach is employed to tightly couple spatial and temporal contexts, balancing accuracy and smoothness. Additionally, a geometric angular velocity loss is introduced to impose physically meaningful constraints on rotational variations for further improving motion stability. Extensive experiments demonstrate that KineST has superior performance in both accuracy and temporal consistency within a lightweight framework. Project page: https://kaka-1314.github.io/KineST/
SSD-Poser: Avatar Pose Estimation with State Space Duality from Sparse Observations
Apr 25, 2025The growing applications of AR/VR increase the demand for real-time full-body pose estimation from Head-Mounted Displays (HMDs). Although HMDs provide joint signals from the head and hands, reconstructing a full-body pose remains challenging due to the unconstrained lower body. Recent advancements often rely on conventional neural networks and generative models to improve performance in this task, such as Transformers and diffusion models. However, these approaches struggle to strike a balance between achieving precise pose reconstruction and maintaining fast inference speed. To overcome these challenges, a lightweight and efficient model, SSD-Poser, is designed for robust full-body motion estimation from sparse observations. SSD-Poser incorporates a well-designed hybrid encoder, State Space Attention Encoders, to adapt the state space duality to complex motion poses and enable real-time realistic pose reconstruction. Moreover, a Frequency-Aware Decoder is introduced to mitigate jitter caused by variable-frequency motion signals, remarkably enhancing the motion smoothness. Comprehensive experiments on the AMASS dataset demonstrate that SSD-Poser achieves exceptional accuracy and computational efficiency, showing outstanding inference efficiency compared to state-of-the-art methods.
REMOTE: Real-time Ego-motion Tracking for Various Endoscopes via Multimodal Visual Feature Learning
Jan 30, 2025Real-time ego-motion tracking for endoscope is a significant task for efficient navigation and robotic automation of endoscopy. In this paper, a novel framework is proposed to perform real-time ego-motion tracking for endoscope. Firstly, a multi-modal visual feature learning network is proposed to perform relative pose prediction, in which the motion feature from the optical flow, the scene features and the joint feature from two adjacent observations are all extracted for prediction. Due to more correlation information in the channel dimension of the concatenated image, a novel feature extractor is designed based on an attention mechanism to integrate multi-dimensional information from the concatenation of two continuous frames. To extract more complete feature representation from the fused features, a novel pose decoder is proposed to predict the pose transformation from the concatenated feature map at the end of the framework. At last, the absolute pose of endoscope is calculated based on relative poses. The experiment is conducted on three datasets of various endoscopic scenes and the results demonstrate that the proposed method outperforms state-of-the-art methods. Besides, the inference speed of the proposed method is over 30 frames per second, which meets the real-time requirement. The project page is here: \href{https://remote-bmxs.netlify.app}{remote-bmxs.netlify.app}
Towards Full-parameter and Parameter-efficient Self-learning For Endoscopic Camera Depth Estimation
Oct 01, 2024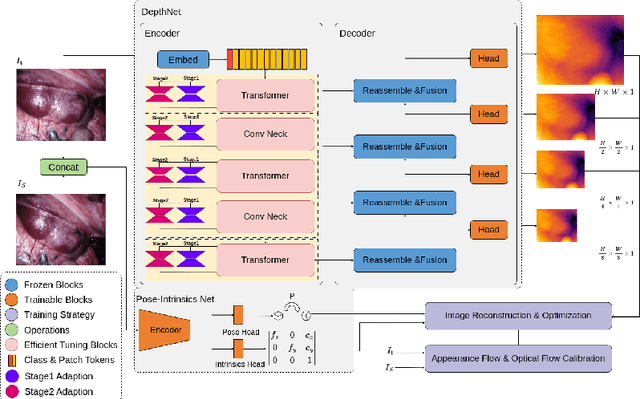
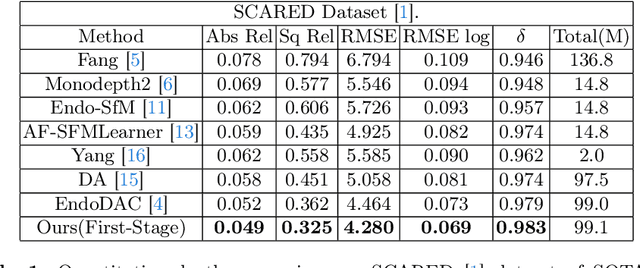
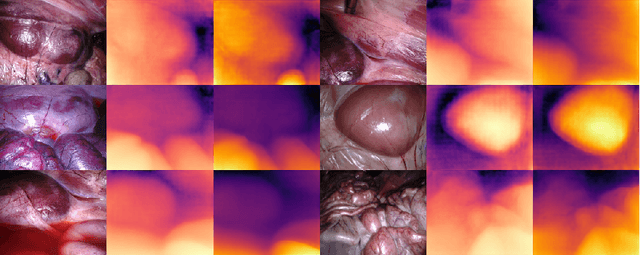
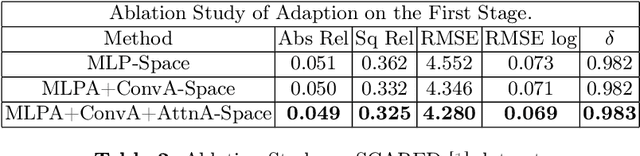
Adaptation methods are developed to adapt depth foundation models to endoscopic depth estimation recently. However, such approaches typically under-perform training since they limit the parameter search to a low-rank subspace and alter the training dynamics. Therefore, we propose a full-parameter and parameter-efficient learning framework for endoscopic depth estimation. At the first stage, the subspace of attention, convolution and multi-layer perception are adapted simultaneously within different sub-spaces. At the second stage, a memory-efficient optimization is proposed for subspace composition and the performance is further improved in the united sub-space. Initial experiments on the SCARED dataset demonstrate that results at the first stage improves the performance from 10.2% to 4.1% for Sq Rel, Abs Rel, RMSE and RMSE log in the comparison with the state-of-the-art models.