 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching Specific Scientific Knowledge into Large Language Models through Additional Training
Dec 18, 2023



Through additional training, we explore embedding specialized scientific knowledge into the Llama 2 Large Language Model (LLM). Key findings reveal that effective knowledge integration requires reading texts from multiple perspectives, especially in instructional formats. We utilize text augmentation to tackle the scarcity of specialized texts, including style conversions and translations. Hyperparameter optimization proves crucial, with different size models (7b, 13b, and 70b) reasonably undergoing additional training. Validating our methods, we construct a dataset of 65,000 scientific papers. Although we have succeeded in partially embedding knowledge, the study highlights the complexities and limitations of incorporating specialized information into LLMs, suggesting areas for further improvement.
Sequential Experimental Design for Spectral Measurement: Active Learning Using a Parametric Model
May 11, 2023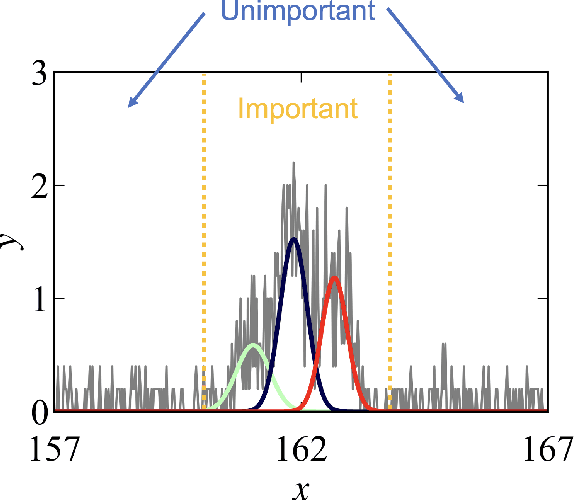
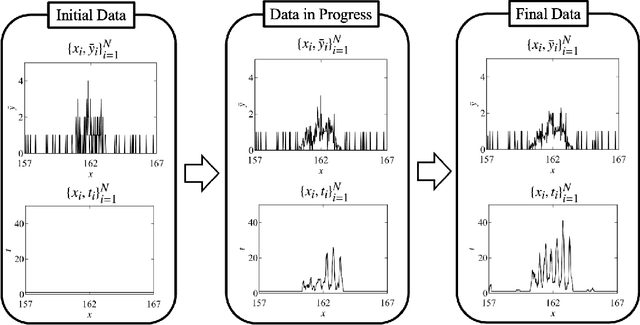
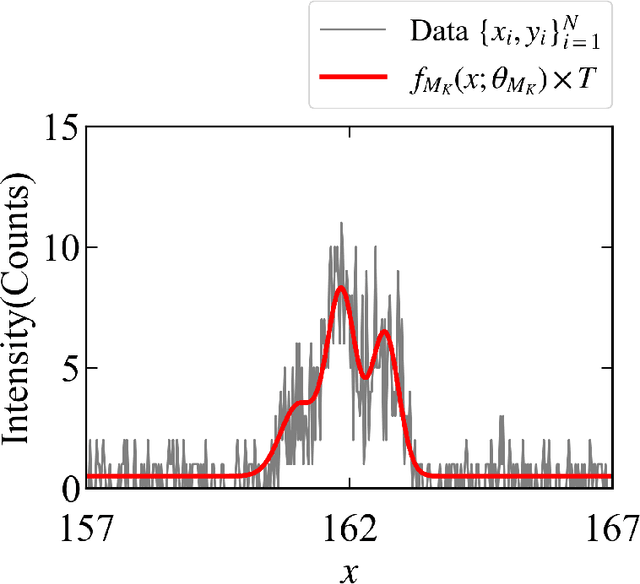
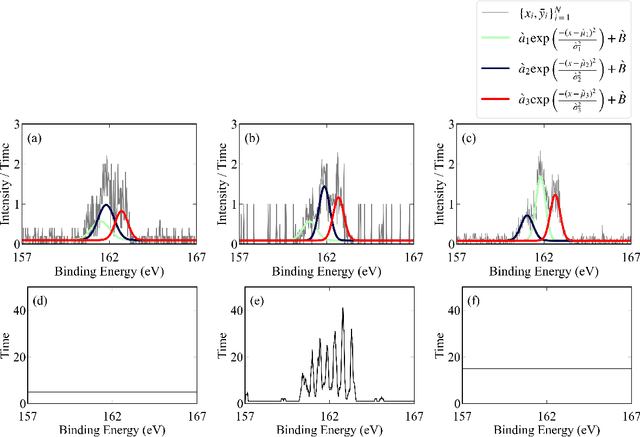
In this study, we demonstrate a sequential experimental design for spectral measurements by active learning using parametric models as predictors. In spectral measurements, it is necessary to reduce the measurement time because of sample fragility and high energy costs. To improve the efficiency of experiments, sequential experimental designs are proposed, in which the subsequent measurement is designed by active learning using the data obtained before the measurement. Conventionally, parametric models are employed in data analysis; when employed for active learning, they are expected to afford a sequential experimental design that improves the accuracy of data analysis. However, due to the complexity of the formulas, a sequential experimental design using general parametric models has not been realized. Therefore, we applied Bayesian inference-based data analysis using the exchange Monte Carlo method to realize a sequential experimental design with general parametric models. In this study, we evaluated the effectiveness of the proposed method by applying it to Bayesian spectral deconvolution and Bayesian Hamiltonian selection in X-ray photoelectron spectroscopy. Using numerical experiments with artificial data, we demonstrated that the proposed method improves the accuracy of model selection and parameter estimation while reducing the measurement time compared with the results achieved without active learning or with active learning using the Gaussian process regression.