 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Bayesian Additive Regression Trees for Conditional Average Treatment Effects in Regression Discontinuity Designs
Mar 04, 2026Regression discontinuity designs (RDD) are widely used for causal inference. In many empirical applications, treatment effects vary substantially with covariates, and ignoring such heterogeneity can lead to misleading conclusions, which motivates flexible modeling of heterogeneous treatment effects in RDD. To this end, we propose a Bayesian nonparametric approach to estimating heterogeneous treatment effects based on Bayesian Additive Regression Trees (BART). The key feature of our method lies in adopting a general Bayesian framework using a pseudo-model defined through a loss function for fitting local linear models around the cutoff, which gives direct modeling of heterogeneous treatment effects by BART. Optimal selection of the bandwidth parameter for the local model is implemented using the Hyvärinen score. Through numerical experiments, we demonstrate that the proposed approach flexibly captures complicated structures of heterogeneous treatment effects as a function of covariates.
Ensemble Prediction via Covariate-dependent Stacking
Aug 19, 2024This paper presents a novel approach to ensemble prediction called "Covariate-dependent Stacking" (CDST). Unlike traditional stacking methods, CDST allows model weights to vary flexibly as a function of covariates, thereby enhancing predictive performance in complex scenarios. We formulate the covariate-dependent weights through combinations of basis functions, estimate them by optimizing cross-validation, and develop an Expectation-Maximization algorithm, ensuring computational efficiency. To analyze the theoretical properties, we establish an oracle inequality regarding the expected loss to be minimized for estimating model weights. Through comprehensive simulation studies and an application to large-scale land price prediction, we demonstrate that CDST consistently outperforms conventional model averaging methods, particularly on datasets where some models fail to capture the underlying complexity. Our findings suggest that CDST is especially valuable for, but not limited to, spatio-temporal prediction problems, offering a powerful tool for researchers and practitioners in various fields of data analysis.
Adaptively Robust and Sparse K-means Clustering
Jul 09, 2024While K-means is known to be a standard clustering algorithm, it may be compromised due to the presence of outliers and high-dimensional noisy variables. This paper proposes adaptively robust and sparse K-means clustering (ARSK) to address these practical limitations of the standard K-means algorithm. We introduce a redundant error component for each observation for robustness, and this additional parameter is penalized using a group sparse penalty. To accommodate the impact of high-dimensional noisy variables, the objective function is modified by incorporating weights and implementing a penalty to control the sparsity of the weight vector. The tuning parameters to control the robustness and sparsity are selected by Gap statistics. Through simulation experiments and real data analysis, we demonstrate the superiority of the proposed method to existing algorithms in identifying clusters without outliers and informative variables simultaneously.
Spatially-Varying Bayesian Predictive Synthesis for Flexible and Interpretable Spatial Prediction
Mar 22, 2022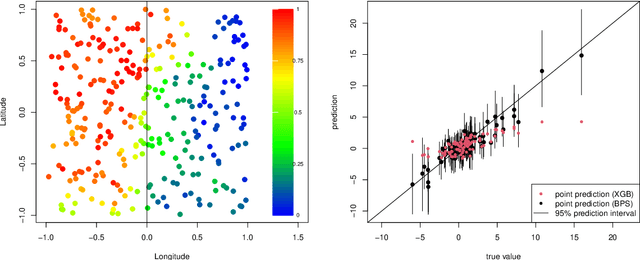
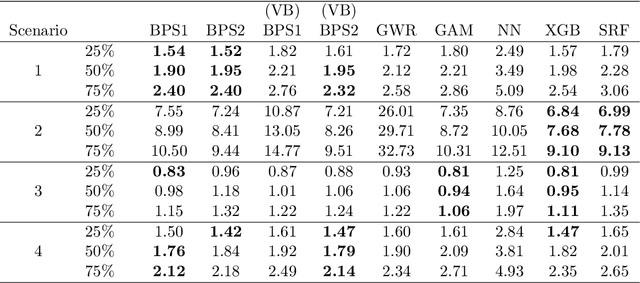
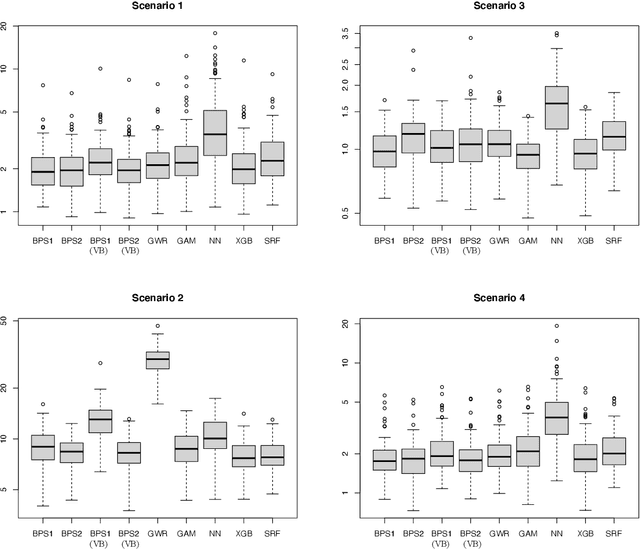
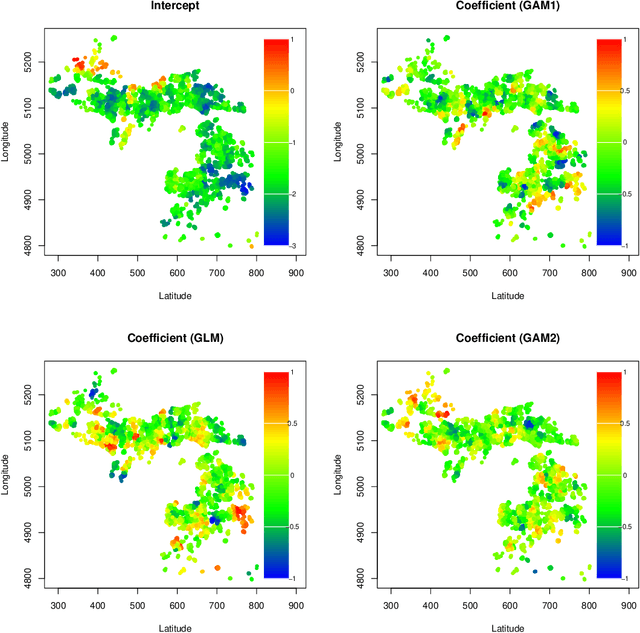
Spatial data are characterized by their spatial dependence, which is often complex, non-linear, and difficult to capture with a single model. Significant levels of model uncertainty -- arising from these characteristics -- cannot be resolved by model selection or simple ensemble methods, as performances are not homogeneous. We address this issue by proposing a novel methodology that captures spatially-varying model uncertainty, which we call spatial Bayesian predictive synthesis. Our proposal is defined by specifying a latent factor spatially-varying coefficient model as the synthesis function, which enables model coefficients to vary over the region to achieve flexible spatial model ensembling. Two MCMC strategies are implemented for full uncertainty quantification, as well as a variational inference strategy for fast point inference. We also extend the estimations strategy for general responses. A finite sample theoretical guarantee is given for the predictive performance of our methodology, showing that the predictions are exact minimax. Through simulation examples and two real data applications, we demonstrate that our proposed spatial Bayesian predictive synthesis outperforms standard spatial models and advanced machine learning methods, in terms of predictive accuracy, while maintaining interpretability of the prediction mechanism.