Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePurifying Adversarial Perturbation with Adversarially Trained Auto-encoders
May 26, 2019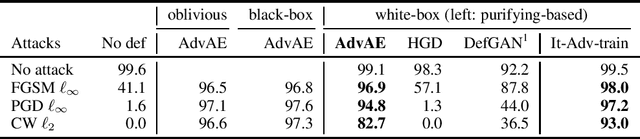

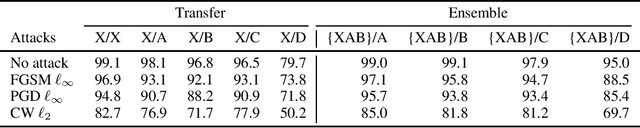
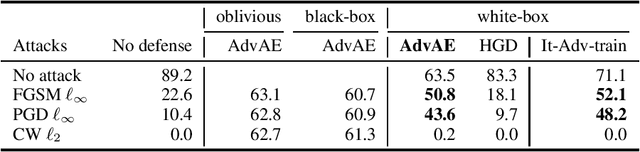
Machine learning models are vulnerable to adversarial examples. Iterative adversarial training has shown promising results against strong white-box attacks. However, adversarial training is very expensive, and every time a model needs to be protected, such expensive training scheme needs to be performed. In this paper, we propose to apply iterative adversarial training scheme to an external auto-encoder, which once trained can be used to protect other models directly. We empirically show that our model outperforms other purifying-based methods against white-box attacks, and transfers well to directly protect other base models with different architectures.
Via